我正在嘗試應用我自己的功能。下面你可以看到資料和功能。
import pandas as pd
import numpy as np
data_test = {
'sales_2017': [100,0,300,0,200],
'profit_2017': [20,0,30,50,0],
}
df = pd.DataFrame(data_test, columns = ['sales_2017','profit_2017','sales_2018','profit_2018'])
df['effective']= df['profit_2017']/df['sales_2017']
df
# Create distribution table
conditions = [
(df['effective'] == 0),
(df['effective'] > 0.1) & (df['effective'] < 0.20),
(df['effective'] > 0.20),
(df['effective'] == "NaN"),
(df['effective'] == "inf"),
]
values = ['Equal to zero','Between 0.1 and 0.2', 'Above 0.2', 'Equal to NaN', "Equal to infinity"]
df['effective_range'] = np.select(conditions, values)
distribution_table = df.groupby('effective_range').agg(count=('effective_range','count'))
所以這里的主要思想是根據“等于零”、“0.1和0.2之間”、“0.2以上”、“等于NaN”、“等于無窮大”這個條件創建一個分布表。
我的設定有 with'Nan'和 with的值'inf',這會導致決賽桌出現問題,您可以在下面看到圖片。
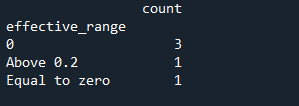
那么任何人都可以幫助我如何解決這個問題并有一個像下面的表格一樣的表格嗎?
effective_range count 等于 0 1 0.1 和 0.2 之間 0 大于 0.2 1 等于 NaN 1 等于無窮大 1
uj5u.com熱心網友回復:
用途Series.isna及numpy.isinf方法:
# Create distribution table
conditions = [
(df['effective'] == 0),
(df['effective'] > 0.1) & (df['effective'] < 0.20),
(df['effective'] > 0.20),
(df['effective'].isna()),
(np.isinf(df['effective'])),
]
values = ['Equal to zero','Between 0.1 and 0.2', 'Above 0.2',
'Equal to NaN', "Equal to infinity"]
df['effective_range'] = np.select(conditions, values)
distribution_table = df.groupby('effective_range').agg(count=('effective_range','count'))
print (distribution_table)
count
effective_range
0 2
Above 0.2 1
Equal to NaN 1
Equal to zero 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/467787.html