編譯丨張瀧玲、楊柳
編輯丨維克多
今年1月份,蘇黎世聯邦理工學院的Stefan Feuerriegelc教授在 《Communications of the ACM》期刊上刊文“Artificial Intelligence Across Company Borders”,在文中教授指出了人工智能(AI)產業落地程序中常見挑戰:如何開展跨公司合作?
 教授表示:通過資料共享構造大規模的跨公司資料集是一種方式,但有資料保密和隱私泄漏風險,且受隱私相關法律的限制,而保護隱私的分布式機器學習框架—聯邦學習,能讓資料不出本地,解決上述痛點,
教授表示:通過資料共享構造大規模的跨公司資料集是一種方式,但有資料保密和隱私泄漏風險,且受隱私相關法律的限制,而保護隱私的分布式機器學習框架—聯邦學習,能讓資料不出本地,解決上述痛點,
但傳統的聯邦學習目前并不能提供規范的隱私保護證明,此外,其場景容易受到因果攻擊,因此,教授指出,結合聯邦學習和領域自適應,能夠更大限度讓合作公司從協作AI模型中受益,同時將原始訓練資料保持在本地,以下是Stefan Feuerriegelc教授對領域自適應聯邦學習的介紹,由星云Clustar高級演算法工程師張瀧玲、楊柳翻譯整理,
近年來,以AI為核心的數字技術正在驅動經濟社會發展,資料顯示,2030年,AI將使全球工業部門的經濟活動增加13萬億美元,然而,由于無法獲取或有效利用跨國公司資料,使得這一技術的潛力在很大程度上仍未得到完全開發,AI收益于大量具有代表性的資料(representative data),這些資料通常需要來自于多家公司,特別是在實際工業場景中,面對少見的意外事件或者關鍵系統狀態,想使AI模型取得良好的性能是極具挑戰性的,
實作跨公司AI技術的一種直接方式是通過資料共享構造大規模的跨公司資料集,但出于資料保密和隱私泄漏風險的考慮,大多數公司都不愿意直接共享資料,并且在大多數情況下,共享資料受到隱私相關法律的限制,因此,具有領域自適應的聯邦學習是解決跨公司AI問題的關鍵,一方面,聯邦學習能夠在不泄漏各公司資料隱私的前提下,實作模型訓練和推理;另一方面,領域自適應允許各公司按照自己特定的應用場景和條件,對聯邦模型做定制,
1.AI合作的障礙
跨公司AI主要存在兩個障礙:
首先是跨公司的資料隱私性,因為直接共享原始資料可能會給競爭對手公司暴露有關自身公司的運營流程或知識產權專有資訊等,這一障礙常常出現在公司尋求與供應商、客戶或競爭對手公司想進行AI合作時,
例如,制造工廠的資料可以揭示引數設定、產品成分、產率、產量、路線和機器正常運行時間,如果此類資料被泄漏,它可能會被客戶在公司談判中濫用或進而幫助競爭對手提高生產力和改進產品,同時除了知識產權之外,一些深層的限制因素也會降低公司之間共享資料的意愿或傾向,例如公司間的信任程度、道德約束、保護公司用戶隱私權的法律法規以及網路安全風險,因此我們需要一個保護資料隱私的解決方案,即在不暴露各公司的源資料前提下進行模型推斷,
其次是跨公司間的合作需要考慮到領域偏移(domain shifts)的影響,領域偏移是指為不同公司使用不同配置機器或作業系統采集得到的資料分布不匹配,例如,來自一家公司采集到的機器資料可能不能作為另一家公司的代表性資料由于不同機器資料采集條件不一樣,領域偏移給潛在的推論帶來了障礙:在一家公司的資料上訓練得到的模型可能表現不佳當部署到另一家資料分布明顯不同的公司時,
2.跨公司AI
AI研究的最新進展有望突破這兩個難題,聯邦學習是一種保護隱私的分布式機器學習框架,旨在讓多個邊緣設備或服務器在不共享資料樣本的前提下,通過共享本地模型引數(梯度或權重),共同進行機器學習的模型訓練,
跨公司的縱向聯邦學習可以從所有參與公司(例如,來自多個工廠、機車車輛廠或發電廠)的共同資料(joint data)中進行,通過共享各公司的模型引數(梯度或權重),共同進行機器學習的模型訓練,
為了實作這一點,跨公司的縱向聯邦學習通過將模型訓練與對原始訓練資料的訪問解耦:各公司通過加密技術在不暴露各自的原始資料前提下對齊共同資料,通過利用各參與方本地資料進行模型訓練,并將中間結果回傳給協調方,協調方匯總各參與方的中間結果,構建協作模型,以整體提升模型性能和效果,在此程序中,沒有公司有權直接訪問到其他公司的原始訓練資料,
在跨公司AI的背景下,針對跨公司間的合作的領域偏移問題,由于不同公司的資料分布通常只是較少重疊,即目標域和源域域有一定差異,我們引入領域自適應理論,目標是學習到的不變數,即不受合作公司的特定操作條件限制,從而減輕跨公司之間由于領域偏移產生的模型表現不佳的影響,
具體主要通過學習源域和目標域的公共的特征表示,在公共特征空間,源域和目標域的分布要盡可能相同,以便邊緣分布在特征空間中對齊,
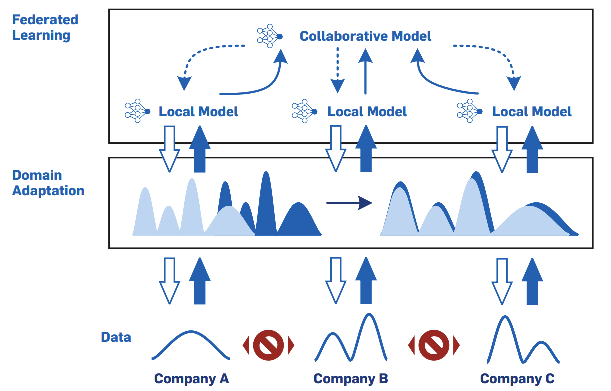
跨公司AI合作可以通過使用聯邦學習來解決直接資料共享的隱私保護的障礙和通過域適應解決領域偏移的障礙,這種組合通常被稱為聯邦遷移學習,
在工業生態系統中通常會遇到兩種型別的遷移學習方法,通常將故障視為標簽但由于故障通常在系統中不常見,因此是不均衡,通常出現標簽在源域中出現但在目標域中沒有(稱為無監督域適應);標簽在源域和目標域中都沒有(稱為無監督遷移學習)
3.跨公司AI落地
公司可以結合聯邦學習和領域自適應,在工業生態系統中實作協同AI,一旦部署,它允許合作公司從協作AI模型中受益,同時將原始訓練資料保持在本地,同時,協作模型的訓練方式可以很好地概括每家公司的資料,并且任何時候都不會共享跨公司的邊界專有資料,只有模型的中間結果(例如梯度)在公司之間共享,此外,協作模型通過學習不變數來代表公司之間的異質性程度,例如,不受公司特定運營條件的影響,每個參與的利益相關公司能夠通過其他合作公司的經驗來擴展自己的運營經驗,
對于工業生態系統,傳統的聯邦學習中的訓練程序通常由中央服務器協調各參與者,但一方面,由于中央服務器的瓶頸特性,可能會造成潛在的漏洞,另一方面,這種集中式架構目前也僅僅應用到雙邊合作這種普遍的場景,
去中心化的方式實施跨公司的AI合作的是十分具有潛力和巨大價值的,因此引入了去中心化的學習設定,在去中心化聯邦學習中,與中央服務器的通信被替換為對等通信,這對于由應用程式或操作條件的相似性和特定用例和操作條件的演變動態形成子網路內的跨公司協作,同時為了完成傳統的中央服務器的任務,分布式賬本技術的使用在此處的應用也是可行的,最后,這里討論的方法需要根據跨企業的實踐經驗中進行選擇,以便公司選擇是否更傾向集中式或去中心化方法的聯邦學習,
雖然聯邦學習能夠提供較為顯著的隱私保護策略,并鼓勵跨公司邊界的協作,但迄今為止,傳統的聯邦學習目前并不能提供規范的隱私保護證明,參與方是可能從梯度更新和之前的模型引數中推斷出一些資訊,此外,傳統的聯邦學習場景容易受到因果攻擊,即訓練好的模型可能會因參與方錯誤的模型更新而遭到破壞,對于公司而言,避免此類攻擊的實施是非常重要的,這里有一種解決方案是提出使用額外的隱私保護技術,例如差分隱私或密碼學手段等等,
4.結合聯邦學習和領域自適應,可以在跨公司環境中釋放AI的力量
對于從業者而言,將跨公司的AI合作引入工業生態系統將需要指導和實施程序的一系列設計原則,例如,如果兩家公司的應用程式內的資料分布沒有明顯的領域偏移,則可以直接應用聯邦學習而不需要與領域自適應相結合等,
此外,跨公司AI合作的實施必須滿足實踐的進一步需求,這可能需要更多擴展,例如持續學習和資料異質性的解決方案,例如,對于高度異構的系統,必須選擇足夠魯棒的模型實作,從而實作可遷移性(例如,跨不同的產品型號、不同的傳感器組組合或不同的制造商),同時隨著時間的推移,行業成熟后也應該做好引導作業來制定一系列的標準規范跨公司合作進一步釋放AI的力量,
5.發展方向
將聯邦學習與領域適應相結合,可以在跨公司合作中釋放AI的力量,這種跨公司的AI合作可以擴展到傳統的供應鏈或領域之外,例如,創建合作評級組織的大型生態系統,雖然這一愿景可能會在不久的將來實作,但公司可以開始在值得信賴的合作伙伴中學習和使用這項新技術,同時仍然需要開發公平指標去分配模型,這是跨公司AI合作的微觀經濟含義,行業經理應確定可以幫助更全面優化其績效的資料合作伙伴,做到與系統思維保持一致,
跨公司的 AI 還可以激發新的商業模式,例如通過AI即提供服務或由第三方公司支持資料,特別是中小型公司將從利用其他公司的資料資源中受益,在這方面,服務系統工程可以幫助制定基于跨公司AI設計和開發服務系統網路的系統原則,朝著這個方向邁出的第一步是系統地理解利益相關者和資源之間的價值共創模式,
跨公司利用AI合作將受益于正在進行的研究,目前研究也在做出新的嘗試來推進聯邦學習,提高其可擴展性、魯棒性和有效性,同時加強的隱私保護和提高模型性能方面,對這些具有領域自適應能力的聯邦學習可以促進跨公司邊界使用AI合作呈指數級增長,
參考鏈接:
https://cacm.acm.org/magazines/2022/1/257442-artificial-intelligence-across-company-borders/fulltext
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/472929.html
標籤:其他
上一篇:超越聯邦學習,讓AI跨越公司邊界:解決資料隱私和場景模型定制問題
下一篇:Vue3使用插槽時的父子組件傳值