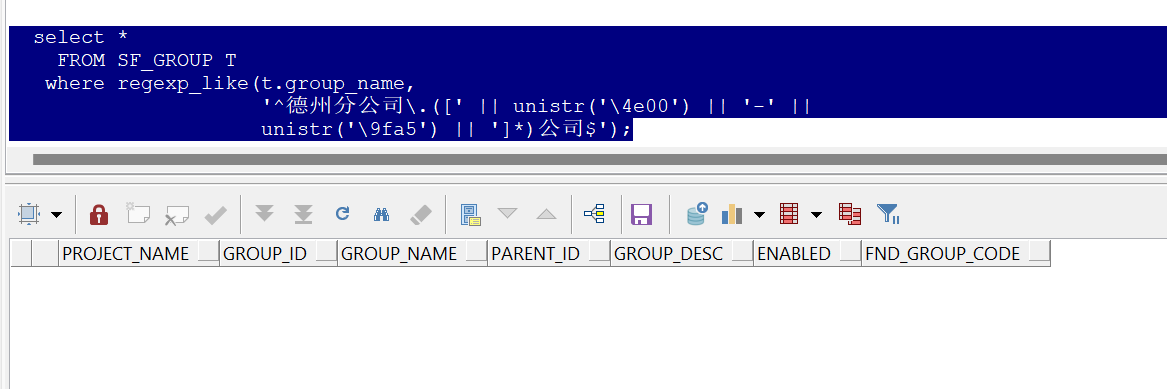
我想匹配以 . 開頭德州分公司.和結尾的字符公司。我的正則運算式如下:
select *
FROM SF_GROUP T
where regexp_like(t.group_name,
'^德州分公司\.([' || unistr('\4e00') || '-' ||
unistr('\9fa5') || ']*)公司$');
-- or another try
select *
FROM SF_GROUP T
where regexp_like(t.group_name,
'^德州分公司\.([\u4e00-\u9fa5]*)公司$');
但是上述方法都不起作用。要匹配的字符(漢字):
德州分公司.禹城分公司
德州分公司.齊河分公司
德州分公司.綜合部
德州分公司.集團客戶部
我表中的記錄:
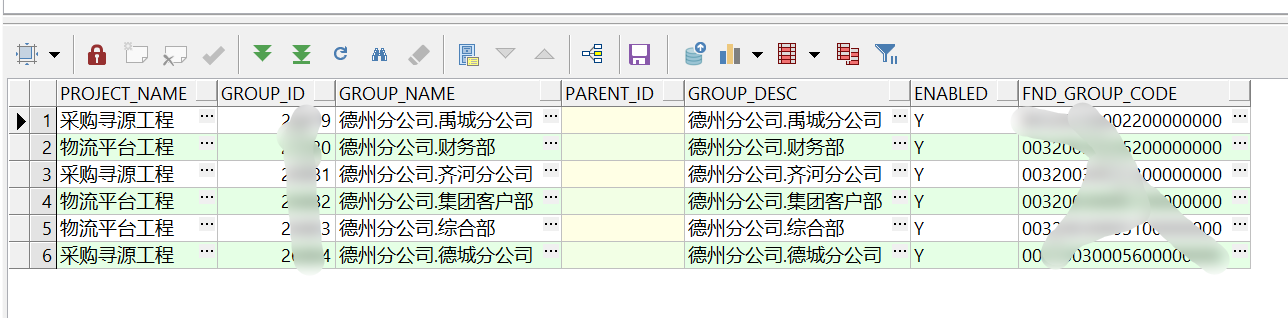
我想得到的輸出:

但是,在我執行句子后它什么也沒回傳:
請幫忙。
uj5u.com熱心網友回復:
如果你有資料:
CREATE TABLE sf_group (group_name) AS
SELECT '德州分公司.禹城分公司' FROM DUAL UNION ALL
SELECT '德州分公司.齊河分公司' FROM DUAL UNION ALL
SELECT '德州分公司.綜合部' FROM DUAL UNION ALL
SELECT '德州分公司.集團客戶部' FROM DUAL;
然后:
SELECT group_name,
DUMP(group_name, 1010)
FROM sf_group
應該輸出如下內容:
團隊名字 轉儲(GROUP_NAME,1010) 德州分公司.禹城分公司 Typ=1 Len=31 CharacterSet=AL32UTF8: 229,190,183,229,183,158,229,136,134,229,133,172,229,143,184,46,231,166,185,229,159,142,229,136,134,229,1433,297,1333,17 德州分公司.齊河分公司 Typ=1 Len=31 CharacterSet=AL32UTF8: 229,190,183,229,183,158,229,136,134,229,133,172,229,143,184,46,233,189,144,230,178,179,229,136,134,229,14338,17 德州分公司綜合部 Typ=1 Len=25 CharacterSet=AL32UTF8: 229,190,183,229,183,158,229,136,134,229,133,172,229,143,184,46,231,187,188,229,144,136,233,131,168 德州分公司集團客戶部 Typ=1 Len=31 CharacterSet=AL32UTF8: 229,190,183,229,183,158,229,136,134,229,133,172,229,143,184,46,233,155,134,229,155,162,229,174,162,230,131,18,61
如果您沒有看到 UTF-8 字符集,那么您的問題可能與您用于存盤字串的字符集有關;您可以嘗試將列從CHARorVARCHAR2資料型別更改為NCHARor NVARCHAR2。
我想匹配以 . 開頭
德州分公司.和結尾的字符公司。
如果不需要過濾中間字符,最簡單的方法是不使用正則運算式,而是使用LIKE:
SELECT *
FROM sf_group
WHERE group_name LIKE '德州分公司.%公司';
哪個輸出:
團隊名字 德州分公司.禹城分公司 德州分公司.齊河分公司
如果您想過濾中間字符,那么您的第一個查詢有效:
SELECT '^德州分公司\.(['
|| unistr('\4e00')
|| '-'
|| unistr('\9fa5')
|| ']*)公司$' FROM DUAL;
但您也可以硬編碼匹配的字符unistr('\4e00')和unistr('\9fa5'):
SELECT *
FROM sf_group
WHERE REGEXP_LIKE(group_name, '^德州分公司\.[一-龥]*公司$')
他們都輸出:
> | GROUP_NAME |
> | :------------------------------ |
> | 德州分公司.禹城分公司 |
> | 德州分公司.齊河分公司 |
如果您的查詢不起作用并且您想找到它不起作用的值,那么您可以使用:
SELECT group_name,
DUMP(
REGEXP_SUBSTR(t.group_name, '^德州分公司\.(.*)公司$', 1, 1, NULL, 1),
1016
) AS group_name_dump
FROM SF_GROUP T
WHERE -- Find the rows that match the start and end of the pattern.
regexp_like(t.group_name, '^德州分公司\.(.*)公司$')
AND -- Find the rows where the middle of the pattern does not match.
NOT REGEXP_LIKE(
-- Extract the middle capturing group
REGEXP_SUBSTR(t.group_name, '^德州分公司\.(.*)公司$', 1, 1, NULL, 1),
'^[' || unistr('\4e00') || '-' || unistr('\9fa5') || ']*$'
);
查詢:
select *
FROM SF_GROUP T
where regexp_like(t.group_name,
'^德州分公司\.([\u4e00-\u9fa5]*)公司$');
將不起作用,因為正則運算式運算子多語言增強檔案指出:
如果您有直接輸入法,Oracle 允許您直接輸入多位元組字符,或者您可以使用函式來組合多位元組字符。您不能使用 '\xxxx' 形式的 Unicode 十六進制編碼值。Oracle 根據用于編碼字符的位元組值而不是字符的圖形表示來評估字符。所有重音字符都被視為單詞字符。
所以[\u4e00-\u9fa5]匹配字符\或uoe4或eor或0范圍0-\oru或9或f或。a5
db<>在這里擺弄
uj5u.com熱心網友回復:
你可以試試這個它應該可以作業:
select * FROM SF_GROUP T where regexp_like(t.group_name, '^德州分公司.(.*)公司$');
或者你可以使用 LIKE,不需要正則運算式:
where t.group_name like('德州分公司%公司')
uj5u.com熱心網友回復:
作為@MTO 的好答案和您在問題下的評論的附錄:
但是為什么……沒用?
...當它顯然在提供的 db<>fiddle MTO 中作業時...
您的 NLS 會話設定可能會影響結果。
如檔案中所述,“REGEXP_LIKE 條件是排序敏感的”。
使用二進制排序規則,查詢會回傳預期的結果,但并不總是使用其他設定。如果您已NLS_COMP設定為'LINGUISTIC'并NLS_SORT設定為'SCHINESE_RADICAL_M'or'SCHINESE_STROKE_M'然后查詢仍然執行您的預期;但如果您已NLS_SORT設定,'SCHINESE_PINYIN_M'則它不會回傳任何資料。這似乎就是你所看到的。
基于 MTO 的db<>fiddle'SCHINESE_PINYIN_M' ,添加使用這三個設定重復的相同查詢 - 顯示前兩個的結果,沒有結果。
在檔案中閱讀有關語言排序的更多資訊。
您可以更改會話設定,或切換到.*匹配指定字串之間的任何字符的方法,或使用LIKE; 正如 MTO 也顯示的那樣。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/488358.html
標籤:甲骨文
上一篇:物件中的常量