from scrapy_selenium import SeleniumRequest
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.select import Select
from selenium import webdriver
url='https://www.aeafa.es/asociados.php?provinput='
driver =webdriver.Chrome('C:\Program Files (x86)\chromedriver.exe')
driver.get(url)
wait = WebDriverWait(driver, 30)
detail=wait.until(EC.element_to_be_clickable((By.XPATH, "//tbody//td[6]")))
detail.click()
錯誤將在這些:
detail=wait.until(EC.element_to_be_clickable((By.XPATH, "//tbody//td[6]")))
detail.click()
我希望他們點擊這些的標題是頁面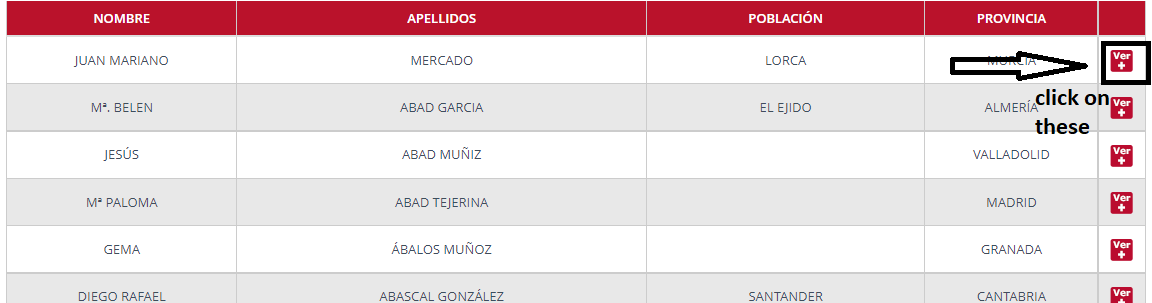
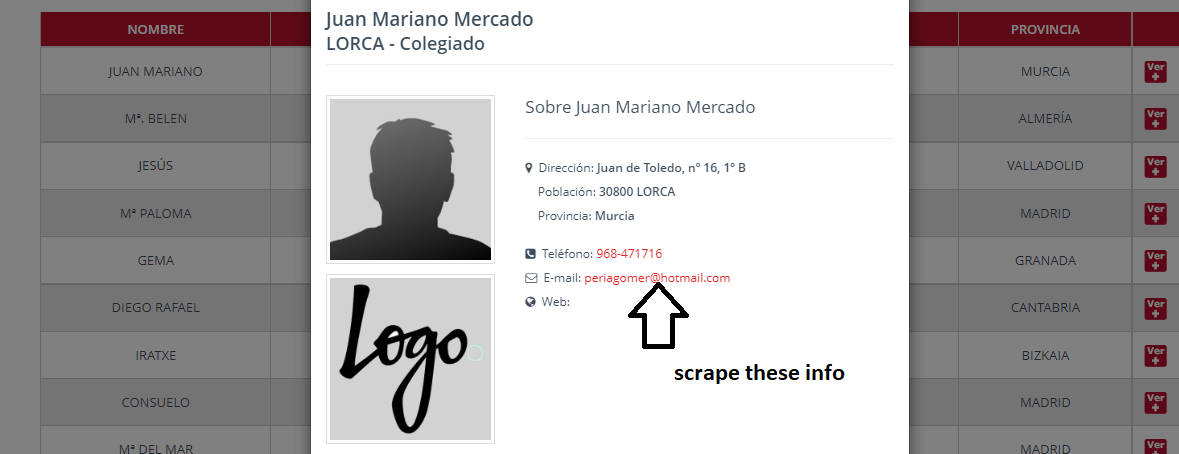
然后會刮掉這些資訊。如何抓取這些資料。
uj5u.com熱心網友回復:
您無法找到HTML 屬性以單擊它。嘗試更換
detail=wait.until(EC.element_to_be_clickable((By.XPATH, "//td//img//@src"))).click()
和
detail = wait.until(EC.element_to_be_clickable((By.XPATH, "//a[@title='info']")))
detail.click()
更新 由于您的 ScrapySelenium 方法似乎不起作用,請嘗試常見的 Selenium 方法。然后你可以讓它適應 Scrapy
from selenium import webdriver
driver = webdriver.Chrome()
url = 'https://www.aeafa.es/asociados.php?provinput='
driver.get(url)
for mail in driver.find_elements("xpath", "//p/a[starts-with(@href, 'mailto')]"):
print(mail.get_attribute('textContent'))
請注意,您無需打開每個詳細資訊彈出視窗即可獲取所需的電子郵件文本
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/492875.html
上一篇:簡單的網頁抓取