在此鏈接上:
我使用這段代碼:
import pandas as pd
url="https://www.basketball-reference.com/teams/MIA/2022.html"
pd.read_html(url,match="Shooting")
但它說:ValueError:沒有找到匹配模式'Shooting'的表。
如果我嘗試 pd.read_html(url,match="Roster") 或 pd.read_html(url,match="Totals") 它會搜索這些表。
uj5u.com熱心網友回復:
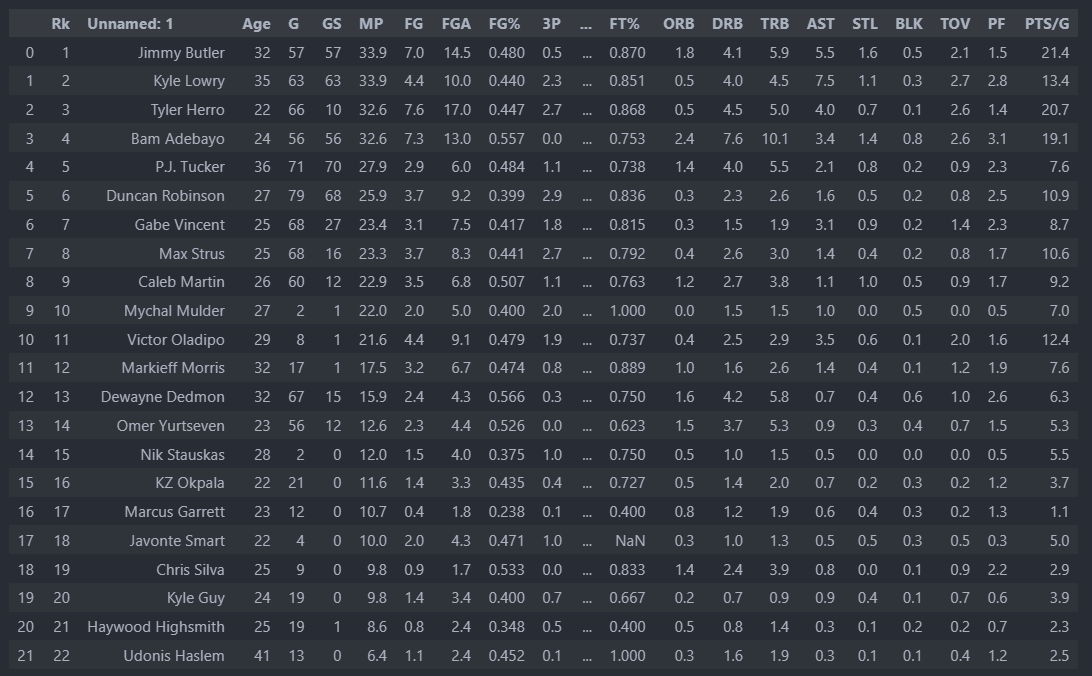
它是您要閱讀的第二張表。你可以簡單地做:
import pandas as pd
url="https://www.basketball-reference.com/teams/MIA/2022.html"
pd.read_html(url)[1]
uj5u.com熱心網友回復:
我發現每個內部注釋的 HTML 代碼div#all_*與實際評分表內容相同。所以看起來表格在頁面加載后以某種方式從使用 JavaScript 的評論中生成。顯然,這是某種刮擦保護。
我的意思的截圖(你想得到的射擊部分):
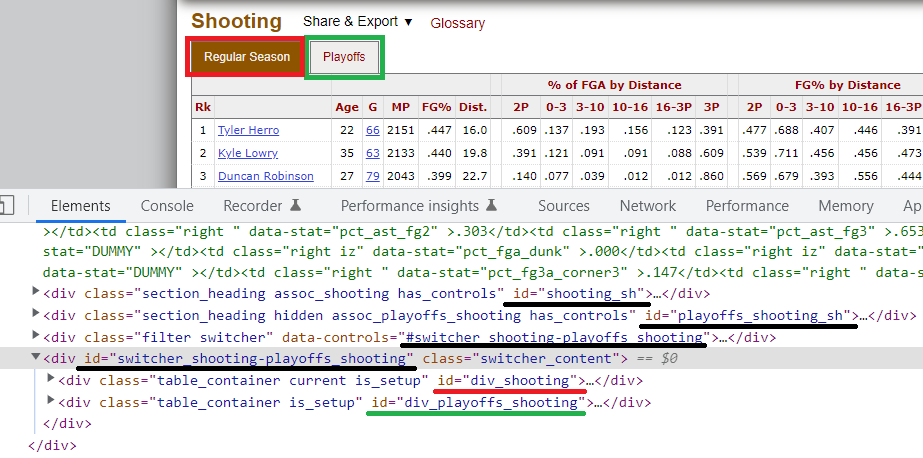

好吧,我現在看到的唯一解決方案是首先加載頁面的整個 HTML,然后req.content使用replace函式進行修改(洗掉所有特殊的 HTML 注釋字符),最后使用 pandas 獲得您想要的表格:
import requests
import pandas as pd
url = "https://www.basketball-reference.com/teams/MIA/2022.html"
req = requests.get(url)
req = req.text.replace('<!--', '')
# req = req.replace('-->', '') # not necessary in this case
pd.read_html(req, match="Shooting")
由于整個 HTML 代碼不再包含注釋,我建議按索引獲取表格。
射擊 - 常規賽季選項卡:
pd.read_html(req)[15]
對于投籃 - 季后賽選項卡:
pd.read_html(req)[16]
uj5u.com熱心網友回復:
pd.read_html()沒有找到所有的表格標簽。只有7個被退回。名冊、每場比賽、總計、高級和其他 3 個。射擊不在其中,所以pd.read_html(url,match="Shooting")會給你一個錯誤。
import pandas as pd
url = 'https://www.basketball-reference.com/teams/MIA/2022.html'
x = pd.read_html(url)
print(len(x)) #7
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/492877.html
標籤:Python python-3.x 熊猫 网页抓取