我正在嘗試撰寫我的第一個刮板,但我遇到了一個問題。我看過的所有教程當然都提到了標簽,以便捕捉你想要抓取的部分,他們提到了類似的東西,或者這實際上是我到目前為止的代碼,我正在嘗試抓取標題、日期,以及每個故事的國家:
import requests
import csv
from bs4 import BeautifulSoup
from itertools import zip_longest
result = requests.get("https://www.cdc.gov/globalhealth/healthprotection/stories-from-the-
field/stories-by-country.html?Sort=Date::desc")
source = result.content
soup = BeautifulSoup(source,"lxml")
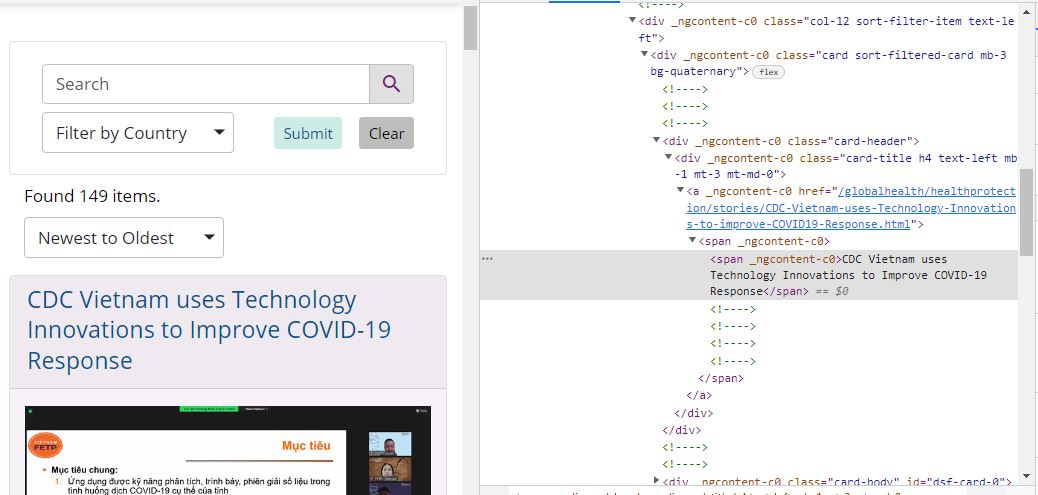
--------------------------現在我的問題來了-------------------- ---------------------- 當我開始在 CDC 中尋找標題時,越南使用技術創新來改善 COVID-19 回應,就像這樣!
當我嘗試我學到的代碼時:
title = soup.find_all("span__ngcontent-c0",{"class": ##I don't know what goes here!})
當然它不起作用。我已經搜索并發現這個 _ngcontent-c0 實際上是有角度的,但我不知道如何刮掉它!有什么幫助嗎?
uj5u.com熱心網友回復:
該網站需要javascript來呈現您想要抓取的所有內容。
它呼叫 API 來獲取所有內容。只需請求此 API。
你需要做這樣的事情:
import requests
result = requests.get(
"https://www.cdc.gov/globalhealth/healthprotection/stories-from-the-field/dghp-stories-country.json")
for item in result.json()["items"]:
print("Title: " item["Title"])
print("Date: " item["Date"][0:10])
print("Country: " ','.join(item["Country"]))
print()
輸出:
Title: System Strengthening – A One Health Approach
Date: 2016-12-12
Country: Kenya,Multiple
Title: Early Warning Alert and Response Network Put the Brakes on Deadly Diseases
Date: 2016-12-12
Country: Somalia,Syria
我希望我能夠幫助你。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/492880.html