我有一個包含多個交易狀態資料的檔案,請參閱“檔案圖片”。現在我想為所有交易狀態獲取不同的資料框,而不是第三列。第一列中的字串對于所有事務狀態都是固定的,字串下面的行是列名。
通過字串,我想區分資料幀,以供參考,請參閱下面的所需輸出。
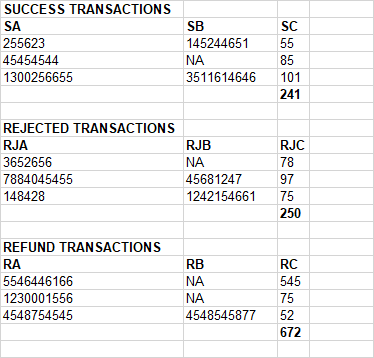
檔案資料
SUCCESS TRANSACTIONS
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
241
REJECTED TRANSACTIONS
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
250
REFUND TRANSACTIONS
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
672
需要輸出
成功交易 DF
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
被拒絕的交易 DF
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
退款交易 DF
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
uj5u.com熱心網友回復:
讓我們準備資料:
import pandas as pd
from io import StringIO
data = '''
SUCCESS TRANSACTIONS
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
241
REJECTED TRANSACTIONS
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
250
REFUND TRANSACTIONS
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
672
'''
df = pd.read_csv(StringIO(data), sep='\s\s ', engine='python', names=[*'abc'])
我不確定這些資料是否與您這邊的資料完全相同。所以要小心下面的代碼。無論如何,這就是你發布的內容,就這樣吧。
拆分此類構造的常用方法是這樣的:
- 提取一些模式作為起始行的標記;
- 使用
cumsum方法將連續組的行標記為相同的編號; - 使用這些數字來識別
groupby.
這是它在代碼中的外觀:
grouper = df['a'].str.endswith('TRANSACTIONS').cumsum()
groups = {}
for _, gr in df.groupby(grouper):
name = gr.iloc[0, 0]
groups[name] = (
gr[1:-1] # skip the very first row with a general name, and the last one with total
.T.set_index(gr.index[1]).T # use the row under the general name as a column names
.reset_index(drop=True) # drop old indexes
.rename_axis(columns='')
)
for name, group in groups.items():
display(group.style.set_caption(name))
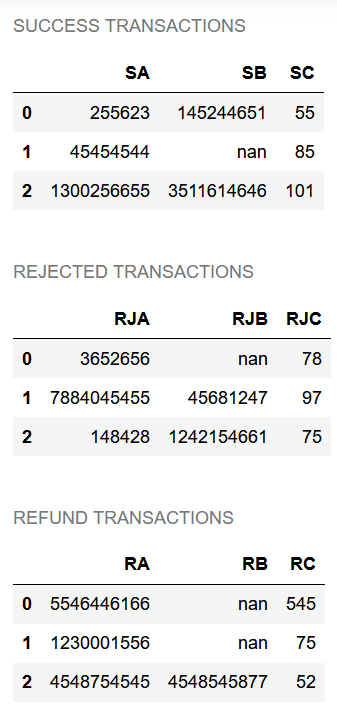
輸出:
uj5u.com熱心網友回復:
將檔案決議為資料幀的一種方法。
代碼
from io import StringIO
import re
def parse_file(filenm):
'''
split file into block of rows based upon 1 or more blank rows
-re.split('\n\s*\n', data)
convert each block into dataframe (function make_dataframe)
'''
def make_dataframe(p):
' Create dataframe from block of rows from file (not including first/last rows)'
return pd.read_csv(
StringIO('\n'.join(p[1:-1])),
sep = '\s ',
engine = 'python')
with open(filenm) as f:
return {p[0]:make_dataframe(p) # p[0] is section name
for s in re.split('\n\s*\n', f.read()) # split file on 1 blank lines
if (p:=s.split('\n'))} # p has block of lines
用法
# Parse file into dataframes
dfs = parse_files('test.txt')
# Show dataframes
dfs = parse_file('test.txt')
for k, df in dfs.items():
print(k)
print(df)
print()
輸出
SUCCESS TRANSACTIONS DF
SA SB SC
0 255623 145244651 55
1 45454544 NaN 85
2 1300256655 3511614646 101
REJECTED TRANSACTIONS DF
RJA RJB RJC
0 3652656 NaN 78
1 7884045455 45681247 97
2 148428 1242154661 75
REFUND TRANSACTIONS DF
RA RB RC
0 5546446166 NaN 545
1 1230001556 NaN 75
2 4548754545 4548545877 52
uj5u.com熱心網友回復:
如果資料存盤在字串中ds:
print('\n'.join(['\n'.join(ta.split('\n')[:-1]) for ta in ds.split(\n\n)]))
列印您要求的內容。
SUCCESS TRANSACTIONS
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
REJECTED TRANSACTIONS
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
REFUND TRANSACTIONS
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
在列印上面輸出的整個代碼下方:
data_as_string = """\
SUCCESS TRANSACTIONS
SA SB SC
255623 145244651 55
45454544 NA 85
1300256655 3511614646 101
241
REJECTED TRANSACTIONS
RJA RJB RJC
3652656 NA 78
7884045455 45681247 97
148428 1242154661 75
250
REFUND TRANSACTIONS
RA RB RC
5546446166 NA 545
1230001556 NA 75
4548754545 4548545877 52
672"""
ds = data_as_string
nl = '\n'
dnl = '\n\n'
# with finally:
print(nl.join([nl.join(ta.split(nl)[:-1]) for ta in ds.split(dnl)]))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/505743.html
上一篇:如何根據R中的列過濾df
下一篇:洗掉特定的重復值并保持對角線