有沒有辦法在不爆炸行的情況下加入 2 個資料集?如果至少一行資料集“df2”滿足與“df1”資料集的連接條件,我只需要一個標志。
有什么辦法可以避免加入嗎?我想避免加入,然后只保留第一行的視窗函式。
條件左連接是 =[(df2.id == df1.id) & (df2.date >= df1.date)]
例子:
Input df1
| ID | 城市 | 運動會 | 日期 |
|---|---|---|---|
| 美國廣播公司 | 倫敦 | 足球 | 2022-02-11 |
| 定義 | 巴黎 | 凌空抽射 | 2022-02-10 |
| 吉 | 曼徹斯特 | 籃球 | 2022-02-09 |
Input df2
| ID | num_spect | 日期 |
|---|---|---|
| 美國廣播公司 | 100.000 | 2022-01-10 |
| 美國廣播公司 | 200.000 | 2022-04-15 |
| 美國廣播公司 | 150.000 | 2022-02-11 |
Output NOT DESIDERED <- 不受歡迎
| ID | 城市 | 運動會 | 日期 | num_spect |
|---|---|---|---|---|
| 美國廣播公司 | 倫敦 | 足球 | 2022-02-11 | 100.000 |
| 美國廣播公司 | 倫敦 | 足球 | 2022-02-11 | 200.000 |
| 美國廣播公司 | 倫敦 | 足球 | 2022-02-11 | 150.000 |
| 定義 | 巴黎 | 凌空抽射 | 2022-02-10 | |
| 吉 | 曼徹斯特 | 籃球 | 2022-02-09 |
Output DESIDERED <- 想要的
| ID | 城市 | 運動會 | 日期 | num_spect | 旗幟 |
|---|---|---|---|---|---|
| 美國廣播公司 | 倫敦 | 足球 | 2022-02-11 | 100.000 | 1 |
| 定義 | 巴黎 | 凌空抽射 | 2022-02-10 | ||
| 吉 | 曼徹斯特 | 籃球 | 2022-02-09 |
uj5u.com熱心網友回復:
這是我使用左連接的實作
from pyspark.sql import functions as F
from pyspark.sql.types import *
from pyspark.sql import Window
df1 = spark.createDataFrame(
[
("abc", "London", "football", "2022-02-11"),
("def", "Paris", "volley", "2022-02-10"),
("ghi", "Manchester", "basketball", "2022-02-09"),
],
["id", "city", "sport_event", "date"],
)
df1 = df1.withColumn("date", F.col("date").cast(DateType()))
df2 = spark.createDataFrame(
[
("abc", "100.000", "2022-01-10"),
("abc", "200.000", "2022-04-15"),
("abc", "150.000", "2022-02-11"),
],
["id", "num_spect", "date"],
)
df2 = (df2
.withColumn("num_spect", F.col("num_spect").cast(DecimalType(18,3)))
.withColumn("date", F.col("date").cast(DateType()))
)
row_window = Window.partitionBy(
"df1.id",
"city",
"sport_event",
"df1.date",
).orderBy(F.col("num_spect").asc())
final_df = (
df1.alias("df1")
.join(
df2.alias("df2"),
on=(
(F.col("df1.id") == F.col("df2.id"))
& (F.col("df2.date") >= F.col("df1.date"))
),
how="left",
)
.withColumn(
"flag",
F.when(
F.col("df2.id").isNull(),
F.lit(None),
).otherwise(F.lit(1)),
)
.withColumn("row_num", F.row_number().over(row_window))
.filter(F.col("row_num") == 1)
.orderBy(F.col("df1.id"))
.drop(F.col("df2.id"))
.drop(F.col("df2.date"))
.drop(F.col("row_num"))
)
final_df.show()
輸出:
--- ---------- ----------- ---------- --------- ----
| id| city|sport_event| date|num_spect|flag|
--- ---------- ----------- ---------- --------- ----
|abc| London| football|2022-02-11| 150.000| 1|
|def| Paris| volley|2022-02-10| null|null|
|ghi|Manchester| basketball|2022-02-09| null|null|
--- ---------- ----------- ---------- --------- ----
uj5u.com熱心網友回復:
這是我的 2 美分:
1.創建資料框如下:
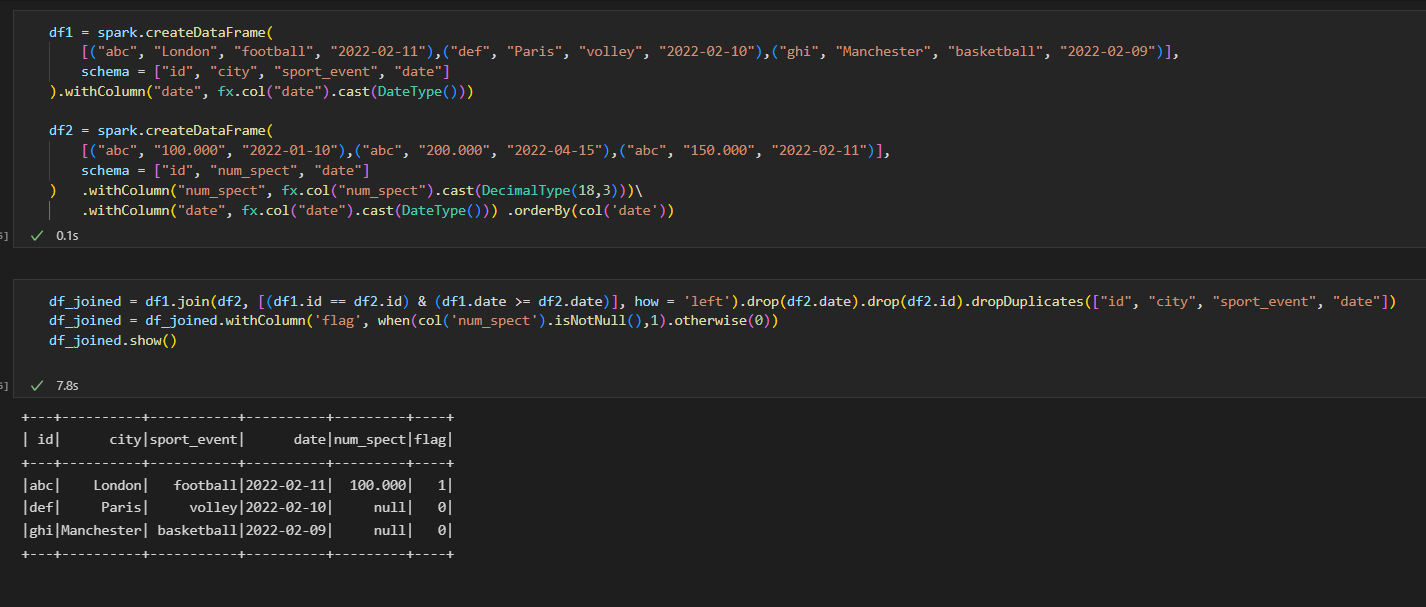
df1 = spark.createDataFrame(
[("abc", "London", "football", "2022-02-11"),("def", "Paris", "volley", "2022-02-10"),("ghi", "Manchester", "basketball", "2022-02-09")],
schema = ["id", "city", "sport_event", "date"]
).withColumn("date", fx.col("date").cast(DateType()))
df2 = spark.createDataFrame(
[("abc", "100.000", "2022-01-10"),("abc", "200.000", "2022-04-15"),("abc", "150.000", "2022-02-11")],
schema = ["id", "num_spect", "date"]
) .withColumn("num_spect", fx.col("num_spect").cast(DecimalType(18,3)))\
.withColumn("date", fx.col("date").cast(DateType())) .orderBy(col('date'))
然后根據條件加入,然后洗掉重復項,最后根據 num_spect 值更新列標志:
df_joined = df1.join(df2, [(df1.id == df2.id) & (df1.date >= df2.date)], how = 'left').drop(df2.date).drop(df2.id).dropDuplicates(["id", "city", "sport_event", "date"]) df_joined = df_joined.withColumn('flag', when(col('num_spect').isNotNull(),1).otherwise(0))列印資料框 df_joined.show()
請參考以下螢屏截圖以供參考:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/519898.html
上一篇:沒有cte的更新很慢