我是 R 的新手,我正在為 ggplot 中的一些繪圖而苦苦掙扎。
我有一些月度資料,我只是將其繪制為與線相連的點。
ggplot(data=df, aes(x=x,y=y))
geom_line(aes(group=g)) geom_point()

現在,我想在分組的三個類別之間添加 Wilcoxon 測驗的成對結果。它應該看起來像這樣。
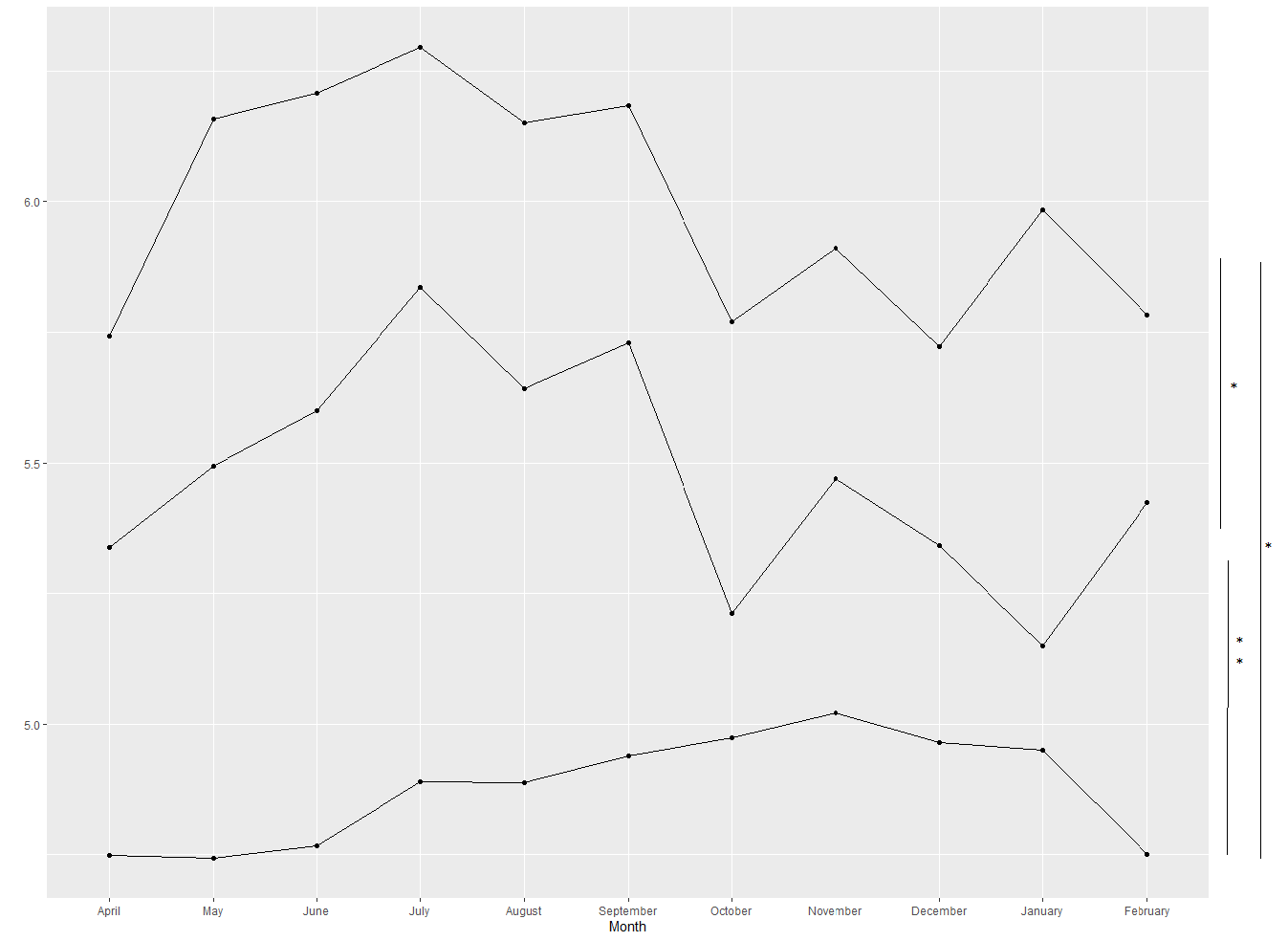
我有點困惑,我知道stat_pvalue_manual適用于類別,但我有一個連續的 y 軸。它應該是水平的。
也許有更多的功能可以做到這一點。有沒有人有如何做到這一點的例子?
提前致謝。
結構(串列(x = c(“四月”,“四月”,“四月”,“五月”,“五月”,“五月”,“六月”,“六月”,“六月”,“七月”,“七月", "7月", "8月", "8月", "8月", "9月", "9月", "9月", "10月", "10月", "10月", "11月", "11月", "十一月", "十二月", "十二月", "十二月", "一月", "一月", "一月", "二月", "二月", "二月"), g = c("a", " b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", " c", "a", "b", "c", "a", "b", "c", "a", "b", "c"), y = c(4.748, 5.3388, 5.7433, 4.744, 5.4938, 6.1583, 4.767, 5.6, 6.2067, 4.889, 5.8363, 6.295, 4.887, 5.6413, 6.15, 4.94, 5.73, 6.1833, 4.974, 5.2113, 5.77, 5.022, 5.47, 5.9117, 4.964, 5.3425, 5.7217, 4.95, 5.15, 5.9833, 4.75, 5.425, 5.7833)), class = "data.frame", row.names = c(NA, -33L))“c”、“a”、“b”、“c”、“a”、“b”、“c”),y = c(4.748、5.3388、5.7433、4.744、5.4938、6.1583、4.767、5.6、6.2067 , 4.889, 5.8363, 6.295, 4.887, 5.6413, 6.15, 4.94, 5.73, 6.1833, 4.974, 5.2113, 5.77, 5.022, 5.47, 5.9117, 4.964, 5.3425, 5.7217, 4.95, 5.15, 5.9833, 4.75, 5.425, 5.7833)) , class = "data.frame", row.names = c(NA, -33L))“c”、“a”、“b”、“c”、“a”、“b”、“c”),y = c(4.748、5.3388、5.7433、4.744、5.4938、6.1583、4.767、5.6、6.2067 , 4.889, 5.8363, 6.295, 4.887, 5.6413, 6.15, 4.94, 5.73, 6.1833, 4.974, 5.2113, 5.77, 5.022, 5.47, 5.9117, 4.964, 5.3425, 5.7217, 4.95, 5.15, 5.9833, 4.75, 5.425, 5.7833)) , class = "data.frame", row.names = c(NA, -33L))
uj5u.com熱心網友回復:
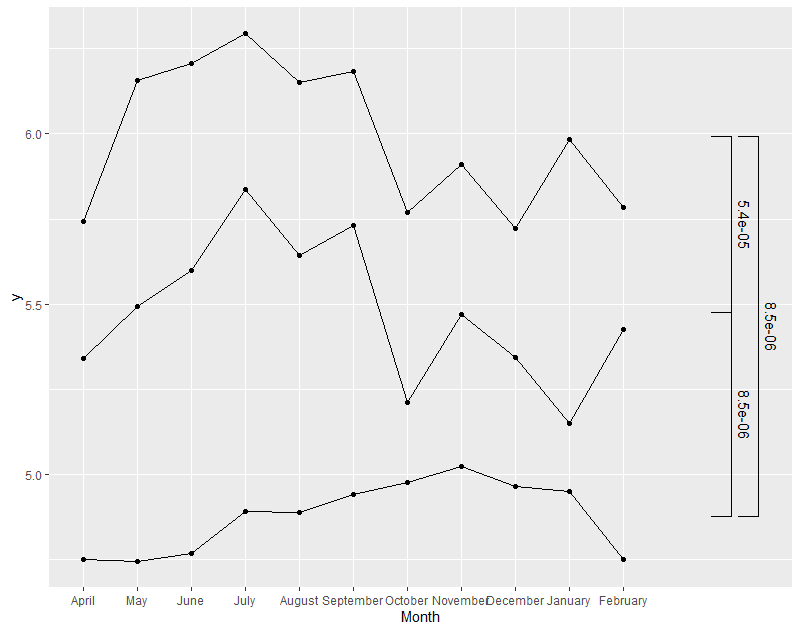
有幾件事使這變得很繁瑣,主要的是你的 x 軸有一個離散的刻度,而且stat_pvalue_manual似乎只適用于連續的刻度,并且需要坐標交換。因此,需要對因子進行排序,并將其從 更改geom_line為geom_path,并且需要計算每個因子水平的均值并將其添加到stat_test物件中。這導致:
#Test data
df <- structure(list(x = c("April", "April", "April", "May", "May", "May", "June", "June", "June", "July", "July", "July", "August", "August", "August", "September", "September", "September", "October", "October", "October", "November", "November", "November", "December", "December", "December", "January", "January", "January", "February", "February", "February"), g = c("a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c", "a", "b", "c"), y = c(4.748, 5.3388, 5.7433, 4.744, 5.4938, 6.1583, 4.767, 5.6, 6.2067, 4.889, 5.8363, 6.295, 4.887, 5.6413, 6.15, 4.94, 5.73, 6.1833, 4.974, 5.2113, 5.77, 5.022, 5.47, 5.9117, 4.964, 5.3425, 5.7217, 4.95, 5.15, 5.9833, 4.75, 5.425, 5.7833)), class = "data.frame", row.names = c(NA, -33L))
df$x <- factor(df$x, levels=unique(df$x))
stat.test <- compare_means(
y ~ g, data = df
)
#Calculate mean values by group
means <- aggregate(df$y, list(g=df$g), mean)
means2 <- means$x
names(means2) <- means$g
stat.test$group1 <- means2[stat.test$group1]
stat.test$group2 <- means2[stat.test$group2]
stat.test$y.position = c(13, 13.5, 13) #arbitrary location for plotting brackets
#Modify the plot
ggplot(data=df, aes(x=y,y=as.numeric(x)))
geom_path(aes(group=g))
geom_point()
stat_pvalue_manual(stat.test, coord.flip = TRUE) coord_flip()
scale_y_continuous("Month", labels=levels(df$x),
breaks=seq_along(levels(df$x)), minor_breaks = 1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/533435.html