考慮以下 RNN 架構:
regressor = Sequential()
regressor.add(LSTM(units = 50, return_sequences = True, input_shape = (X_train.shape[1], 1)))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50))
regressor.add(Dropout(0.2))
regressor.add(Dense(units = 1))
請注意,使用的時間步長為 60,并且此架構是為時間序列預測(更具體地說,股票價格預測)開發的。這是模型摘要:
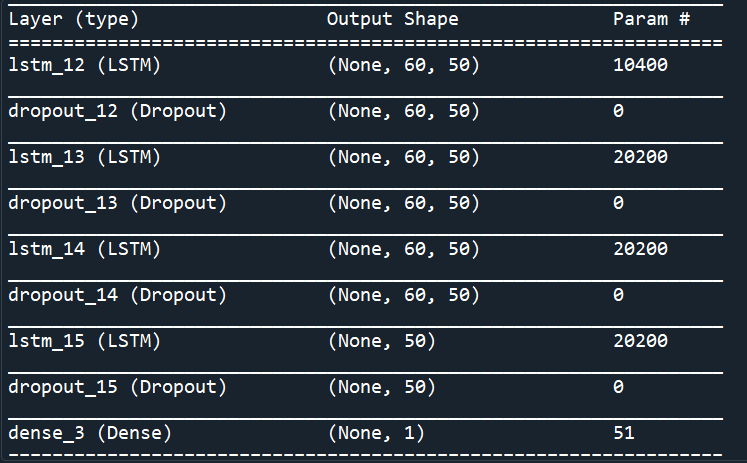
我只需要檢查一下我對這個架構的理解。第一層是具有 50 個單元的 LSTM 層,因此,輸出是形狀為 的 3d 矩陣(none,60,50),這意味著它將在每個時間步回傳 50 個單元的狀態,因此,對于每個單元,它將為每個單元輸出 60 個狀態步驟,所以我們將有形狀(none,60,50)。none這是批處理大小的占位符,將在呼叫fit或predict函式時確定。這些值將完全連接到下一個 LSTM 層。第二和第三 LSTM 層也是如此。對于第四個 LSTM 層,由于return_sequence= False,Keras 將只回傳每個單元格在最后時間步的最終隱藏狀態,因為我們有 50 個單元格,那么我們將有 50 個隱藏狀態值,因此,輸出形狀(none,50)。然后將這些值連接到一個輸出密集層,其中一個神經元將計算最終值,因此它的形狀為(none,1)。請問這樣對嗎?
uj5u.com熱心網友回復:
嗯你是對的。LSTM 的作業原理是遞回,首先你必須計算一個物體的第一個序列,然后你才能走得更遠......dropout在 LSTM 的層之間添加不是一個好的策略,為什么你不在dropoutLSTM 層內部使用。此外,在最后一層使用的東西kernel_regularizer會增加對大權重或更大尺寸輸入的懲罰。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/534010.html