我的示例資料如下所示
customer_id revenue_m10 revenue_m9 revenue_m8 target
1 1234 1231 1256 1239
2 5678 3425 3255 2345
我正在嘗試根據 scikit-learn 的 train_test_split 模塊將我的資料集拆分為訓練和測驗。
所以,我嘗試了下面的代碼
X_train,X_test,y_train, y_test = train_test_split(
sample_set_df[all_features],
sample_set_df[target_var],
test_size=0.3
)
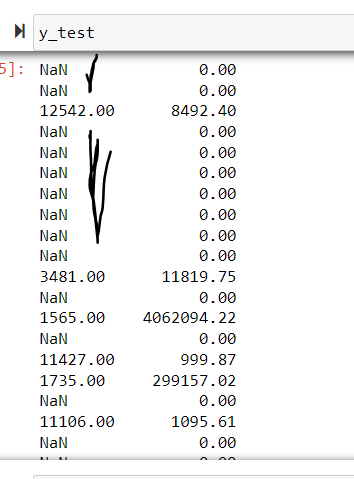
但是當我查看時y_test,它看起來像下面NaNs一樣。不確定是什么問題。索引號是否丟失或任何其他問題?
如果索引是一個問題,我知道我們該如何解決這個問題?
uj5u.com熱心網友回復:
y_test是一個熊貓系列,列印它顯示它的索引和資料。它的索引中似乎sample_set_df有NaNs。
包含在NaNs索引中不會影響train_test_split資料的拆分方式。不過,您可能對實際資料有疑問。當您有 時,目標為 0 NaNs。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/536698.html
上一篇:如何獲取一批中每張影像的平均值?
下一篇:HTML標簽