RegExp()
在es5中,RegExp的建構式引數有兩種情況
1、字串
2、正則運算式
// 第一種情況
let regex = new RegExp('abc', 'i')
// 第二種情況
let regex2 = /abc/i
這兩種情況是等價的
let s = 'abc'
regex.test(s) == regex2.test(s); // true
在es5中這兩種方式不能混用,如果第一個引數是一個正則,第二個是修飾會報錯
let regex3 = new RegExp(/abc/,'i')// 報錯
es6改變了這種行為,如果第一個是正則,第二個引數可以使用修飾符,并且回傳的正則運算式會忽略原有的正則運算式修飾符,只使用新指定的修飾符,
let regex4 = new RegExp(/abc/ig, 'i')
在這里,第二個引數i會把原有的正則修飾符ig覆寫,最后的結果為/abc/i
u 修飾符
es6對正則運算式添加了u修飾符,表示為Unicode模式,用來處理大于\uFFFF的Unicode字符
/^\uD83D/u.test('\uD83D\uDC2A'); // false
這里加上了u.所以變成了es6支持,將\uD83D\uDC2A轉譯為一個字符,與\uD83D不匹配,所以回傳false
/^\uD83D/.test('\uD83D\uDC2A'); // true
這里沒有加u.為es5支持,無法識別4個位元組的UTF-16編碼,會將\uD83D\uDC2A識別為兩個字符,比對的時候其中的字符匹配,所以回傳true
點字符 .
點字符在正則運算式中,表示除了換行符以外的任意單個字符,但對于碼點大于0xFFFF的字符,點字串無法識別,必須前面加上u修飾符
let z = '正'
/^.$/.test(z); // true
/^.$/u.test(z); // true
Unicode 字符表示法
es6新增了大括號表示unicode字符,這種字符在正則中必須使用 u 修飾符才能識別,否則會被解讀為量詞,量詞是無法識別大于0xFFFF的unicode字符的,
/\u{61}/.test('a'); // false
/\u{61}/u.test('a'); // true
i 修飾符
i 修飾符為不區分大小寫,對于大于0xFFFF的unicode的修飾符,后面需要加上 u
/[a-z]/i.test('\u212A'); // false
/[a-z]/iu.test('\u212A'); // true
y 修飾符
y修飾符,意為粘連(sticky)修飾符
在正則匹配中,g為全域匹配且沒有位置限制,
y在正則匹配中,有位置限制,必須在上一次匹配完后的下一個字串的第一位開始匹配,
let a = 'aaa-aa-a'
let r = /a+/y
let r2 = /a+/g
// 第一次匹配
r.exec(a); // aaa
r2.exec(a); // aaa
// 第二次匹配
r.exec(a); // null
r2.exec(a); // aa
y為粘連,上一次匹配完后的下一個字串第一位,第一位是:-無法匹配上,解決的方法:其實只需要修改一下正則保證每次匹配上就行了 /a+-/y
g為全域匹配沒有位置限制
RegExp.prototype.sticky
來檢查是否設定了 y 修飾符
let a1 = /heelo\d/y
console.log(a1.sticky); // true
檢測正則運算式修飾符以及正文
- source 回傳正則匹配規則
- flags 回傳正則的修飾符
let rul = /abc/ig
console.log(rul.source); // abc
console.log(rul.flags); // ig
s 修飾符 : dotAll模式
正則運算式中,點(.)是一個特殊的字符,代表任意字符,但是有兩種例外
第一種:四個位元組的UTF-16字符,這個使用 u 修飾符解決
第二種:行終止符,使用 s 修飾符解決
行終止符,就是該字符表示一行的終結,下面四個字符屬于“行終止符”
- U+000A 換行符(
\n) - U+000D 回車符(
\r) - U+2028 行分隔符(line separator)
- U+2029 段分隔符(paragraph separator)
let f = /foo.bar/.test('foo\nbar')
console.log(f); // false // 因為.不匹配 \n ,所以正則運算式回傳false
// 解決方法 : s 修飾符
/* 使用s修飾符,可以使 . 匹配任意單個字符 */
let f2 = /foo.bar/s.test('foo\nbar')
console.log(f2); // true
這種s修飾符的模式被稱為dotAll模式,dot就是代表一切字符,
所以,正則運算式還引入了dotAll模式,檢查該運算式是否開啟了dotAll模式,
let f3 = /foo.bar/s
console.log(f3.dotAll); // true // 開始了dotAll模式
先行斷言和后行斷言
先行斷言
先行斷言指的是,x在y的前面才匹配
語法:/x(?=y)/ x在y符號前才匹配
let look = '100% 東方不敗'
/\d+(?=%)/.exec(look); // 100 // 數字在百分號前面才匹配
let look2 = '100! 東方不敗'
console.log(/\d+(?=%)/.exec(look2)); // null 沒有匹配到%前的數字
后行斷言
與先行斷言相反,x在y的后面時才匹配
語法:/(?<=y)x/ 說明: ? 后面跟 <= 條件y
let look3 = '東方不敗 $100 西方求敗'
/(?<=\$)\d+/.exec(look3); // 100 表示在\$后的字符才會被匹配
注意 : 先行斷言和后行斷言的條件是不計入回傳結果的
具名組匹配
正則運算式使用圓括號進行組的匹配,每組圓括號代表著一個匹配,匹配結果可以從組中提取出來
let rul = /(\d{4})-(\d{2})-(\d{2})/
let r = rul.exec('2022-12-13')
console.log(r[1]); // 2022
console.log(r[2]); // 12
console.log(r[3]); // 13
雖然結果可以從組中提取出來,但它是通過下標提取的,如果組的順序發生改變,那么下標也需要做對應更改,其實是不太方便的,對此es2018引入了"具名組匹配",可以給組取別名,通過別名提取結果
語法:(?<別名>正則)
let rul2 = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/
let r2 = rul2.exec('2022-12-13')
console.log(r2.groups.year); // 2022
console.log(r2.groups.month); // 12
console.log(r2.groups.day); // 13
console.log(r2.groups.minute); // undefined 如果沒有匹配,那么物件屬性為undefined
解構賦值和替換
通過上面的具名組匹配,給組取別名后,在正則的groups中,匹配的屬性實際上是一個物件,通過解構賦值可以直接從匹配結果上為變數賦值,
. 可以匹配任意字符,查找單個字符,除了換行和行結束符,
n* 匹配任何包含零個或多個 n 的字串,
解構:
let {groups : {hours,minute}} = /^(?<hours>.*):(?<minute>.*)/.exec('12:49')
console.log(hours,minute); // 12 49 // 通過解構賦值提取
替換
字串替換時,使用$<組名>進行替換
- 將匹配的字串位置替換
- 不影響原正則運算式
let rul4 = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/u
console.log('2022-12-13'.replace(rul4,'$<day>/$<month>/$<year>')); // 13-12-2022
console.log(rul4); // /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/u
replace()的第二個引數可以是一個函式
let data = 'https://www.cnblogs.com/wang-fan-w/p/2022-12-13'.replace(rul4,(matched,params1,param2,params3,position,sources,groups)=>{
let {day,month,year} = groups;
return `${day}/${month}/${year}`
})
console.log(data); // 13-12-2022
說明:
- matched // '2022-12-13' 匹配結果
- params1 // 第一個組匹配2022
- param2 // 第一個組匹配12
- params3 // 第一個組匹配13
- position // 匹配開始的位置 0
- sources // 原字串 2022-12-13
- groups // 具名組構成的一個物件
參考
如果要在正則運算式內部參考某個“具名組匹配”,可以使用 \k<組名> 的寫法
let str = /^(?<word>[a-z]+)!\k<word>$/
str.test('abc!abc'); // true 參考了具名匹配,前后都是abc,前后字符一致
str.test('abc!ab'); // false 參考了具名匹配,前后字符不匹配,但是第二個少一個c
其實可以這么理解,參考就是將前面定義好的組,拿過來復用,
數字參考
首先需要明確分組的概念,即正則中的()中的內容是一個分組,里面的內容作為一個整體參考,如果在分組后面接上 \數字,表示匹配第幾個分組
let str2 = /^(\d{2})([a-z]+)\1$/
console.log(str2.test('11abcd')); // false
console.log(str2.test('11aa11')); // true
第一個輸出:問題出在結尾是英文,這里結尾使用了\數字,1表示匹配第一個分組,第一個分組是必須是2個數字,這里的結尾用的英文所以回傳false
第二個輸出:true,其實這時的正則為/^(\d{2})([a-z]+)(\d{2})$/,\1參考了第一個組
具名匹配的參考和數字參考可以同時使用
let str3 = /^(?<word>[a-z]+)-(\d{2})-\k<word>-\2$/
str3.test('a-11-a-11'); // true
str3.test('a-11-a-aa'); // false
第一個輸出:這里使用了參考以及數字參考
第二個輸出:false, 結尾通過數字參考后,應該為數字\d{2}
d 修飾符:正則匹配索引
es2022新增d修飾符,可以在exec()、match()的回傳結果添加indices屬性,在該屬性上可以拿到匹配的開始位置和結束位置,下標從0開始
let text = 'abcdefg'
let te = /bc/d
let result = te.exec(text)
result.index; // 1 拿到bc匹配的起始位置,下標為1
result.indices; // [1,3] 拿到bc匹配的開始和結束位置的下一個字符的位置
非常重要!!!這里需要注意的是,匹配的字串開始位置是字串的第一個值,匹配的結束位置,并不在回傳結果中,正確來說,匹配的結束位置是匹配字串的末尾的下一個位置,如果這一句不理解,下面的內容將會很難理解
如果正則中包含組匹配,那么indices屬性對應的陣列就會包含多個成員,并且提供每個組的開始位置和結束位置
let text2 = 'abccdef'
let te2 = /bc+(de)/d
let result2 = te2.exec(text2)
console.log(result2.indices); // [1,6][4,6]
- 這里的匹配并不是單個的匹配,而是整體,最外層的
bc其實不參與單獨的匹配,而是放到bcde整體中,所以第一個陣列列印的是1,6,b的下標為1,e的下一個字符的下標為6` - 組會單獨進行匹配,
d的下標為4,e的下一個字符的下標為6
多個組匹配以及下標
let text3 = 'abccdefgh'
let te3 = /bc+(de(fg))/d
let result3 = te3.exec(text3)
result3.indices; // [1,8][4,8][6,8]
匹配的順序:bcdefg、defg、fg,對應的列印結果[1,8][4,8][6,8]
如果正則運算式包含具名匹配,那么indices.groups的屬性會是一個物件,可以從該物件獲取具名組匹配的開始位置和結束位置
let text4 = 'abcdefgh'
let te4 = /bc+(?<word>de)/d // 具名組<word>
let result4 = te4.exec(text4)
result4.indices; // [1,5][3,5]
result4.indices.groups; // {word : [3,5]}
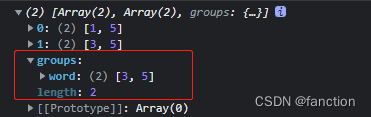

如果未匹配上則列印undefined
String.prototype.matchAll()
matchAll()可以一次性取出所有匹配,回傳的是遍歷器(Iterator)而不是陣列
let strings = 'test1test2test3';
let regex = /t(e)(st(\d?))/g;
for(let match of strings.matchAll(regex)){
console.log(match); // 回傳所有匹配
}

轉為陣列的方法一
[...strings.matchAll(regex)]; // 回傳所有匹配,結果為陣列
轉為陣列的方法二
Array.from(strings.matchAll(regex)); // 回傳所有匹配,結果為陣列

案例原始碼:https://gitee.com/wang_fan_w/es6-science-institute
如果覺得這篇文章對你有幫助,歡迎點亮一下star喲
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/544483.html
標籤:JavaScript