
警報是監控系統中必不可少的一塊, 當然了, 也是最難搞的一塊. 我們乍一想, 警報似乎很簡單一件事:
假如發生了例外情況, 發送或郵件/訊息通知給某人或某頻道,
一把梭搞起來之后,就不免有一些小麻煩:
-
這個啊…一天中總有那么幾次波動,也難修難查了,算了算了不看了;
-
警報太多了,實在看不過來,屏蔽/歸檔/放生吧…
-
有毒吧,這個閾值也太低了;
-
臥槽,這些警報啥意思啊,發給我干嘛啊?
-
臥槽臥槽臥槽,怎么一下子幾十百來條警報, 哦…原來網路出問題了全崩了,
玩笑歸玩笑,但至少我們能看出,警報不是一個簡單的計算+通知系統,只是,”做好警報”這件事本身是個綜合問題,代碼能解決的也只是其中的一小部分,更多的事情要在組織、人事和管理上去做,
從 for 引數開始
我們首先需要一些背景知識:Prometheus 是如何計算并產生警報的?
看一條簡單的警報規則:
alert: KubeAPILatencyHigh
annotations:
message: The API server has a 99th percentile latency of {{ $value }} seconds
for {{ $labels.verb }} {{ $labels.resource }}.
expr: |
cluster_quantile:apiserver_request_latencies:histogram_quantile{job="apiserver",quantile="0.99",subresource!="log"} > 4
for: 10m
labels:
severity: critical這條警報的大致含義是,假如 kube-apiserver 的 P99 回應時間大于 4 秒,并持續 10 分鐘以上,就產生報警,
首先要注意的是由 for 指定的 Pending Duration,這個引數主要用于降噪,很多類似回應時間這樣的指標都是有抖動的,通過指定 Pending Duration,我們可以 過濾掉這些瞬時抖動,讓 on-call 人員能夠把注意力放在真正有持續影響的問題上,
那么顯然,下面這樣的狀況是不會觸發這條警報規則的,因為雖然指標已經達到了警報閾值,但持續時間并不夠長:

但偶爾我們也會碰到更奇怪的事情,
問題 1 為什么不報警?
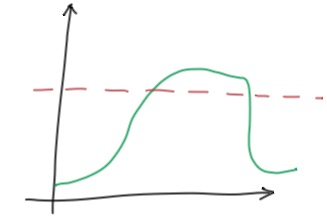
類似上面這樣持續超出閾值的場景,為什么有時候會不報警呢?
問題 2 為什么報警?
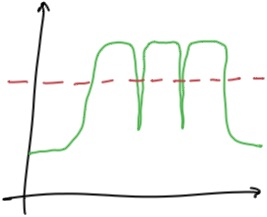
類似上面這樣并未持續超出閾值的場景,為什么有時又會報警呢?
采樣間隔
這其實都源自于 Prometheus 的資料存盤方式與計算方式,
首先,Prometheus 按照配置的抓取間隔(scrape_interval)定時抓取指標資料,因此存盤的是形如 (timestamp, value) 這樣的采樣點,
對于警報, Prometheus 會按固定的時間間隔重復計算每條警報規則,因此警報規則計算得到的只是稀疏的采樣點,而警報持續時間是否大于 for 指定的 Pending Duration 則是由這些稀疏的采樣點決定的,
而在 Grafana 渲染圖表時,Grafana 發送給 Prometheus 的是一個 Range Query,其執行機制是從時間區間的起始點開始,每隔一定的時間點(由 Range Query 的 step 請求引數決定) 進行一次計算采樣,
這些結合在一起,就會導致警報規則計算時“看到的內容”和我們在 Grafana 圖表上觀察到的內容不一致,比如下面這張示意圖:
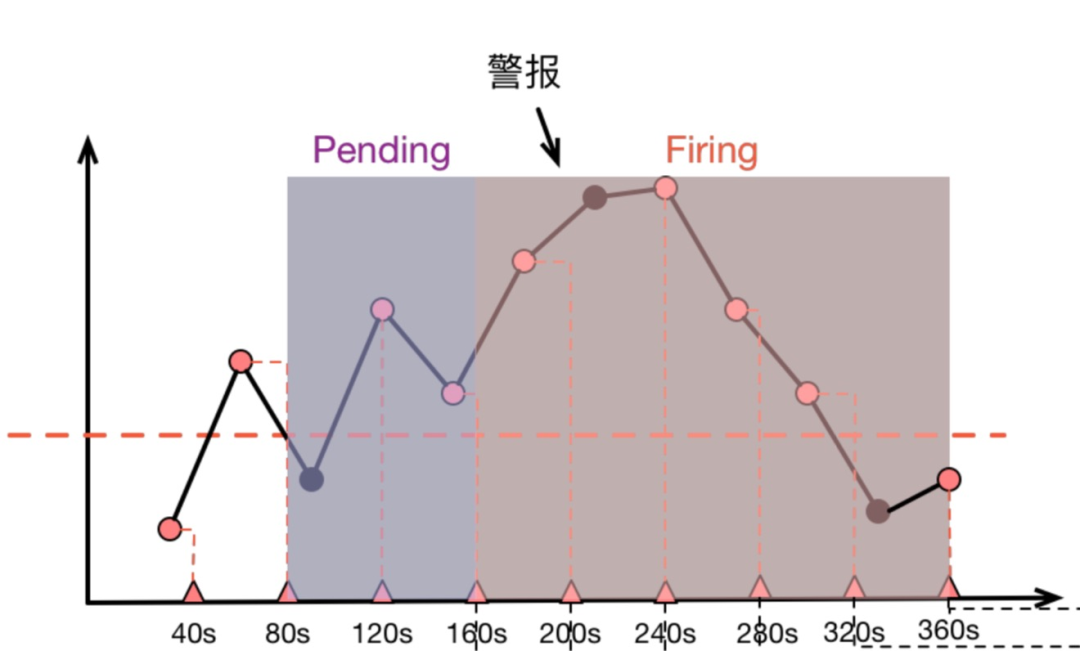
上面圖中,圓點代表原始采樣點:
-
40s 時,第一次計算,低于閾值,
-
80s 時,第二次計算,高于閾值,進入 Pending 狀態,
-
120s 時,第三次計算,仍然高于閾值,90s 處的原始采樣點雖然低于閾值,但是警報規則計算時并沒有”看到它“,
-
160s 時,第四次計算,高于閾值,Pending 達到 2 分鐘,進入 firing 狀態 持續高于閾值,
-
直到 360s 時,計算得到低于閾值,警報消除,
由于采樣是稀疏的,部分采樣點會出現被跳過的狀況,而當 Grafana 渲染圖表時,取決于 Range Query 中采樣點的分布,圖表則有可能捕捉到 被警報規則忽略掉的”低谷“(圖三)或者也可能無法捕捉到警報規則碰到的”低谷“(圖二),如此這般,我們就被”圖表“給蒙騙過去,質疑起警報來了,
如何應對
首先嘛, Prometheus 作為一個指標系統天生就不是精確的——由于指標本身就是稀疏采樣的,事實上所有的圖表和警報都是”估算”,我們也就不必 太糾結于圖表和警報的對應性,能夠幫助我們發現問題解決問題就是一個好監控系統,當然,有時候我們也得證明這個警報確實沒問題,那可以看一眼 ALERTS 指標,ALERTS 是 Prometheus 在警報計算程序中維護的內建指標,它記錄每個警報從 Pending 到 Firing 的整個歷史程序,拉出來一看也就清楚了,
但有時候 ALERTS 的說服力可能還不夠,因為它本身并沒有記錄每次計算出來的值到底是啥,而在我們回頭去考證警報時,又無法選取出和警報計算程序中一模一樣的計算時間點, 因此也就無法還原警報計算時看到的計算值究竟是啥,這時候終極解決方案就是把警報所要計算的指標定義成一條 Recording Rule,計算出一個新指標來記錄計算值,然后針對這個 新指標做閾值報警,kube-prometheus 的警報規則中就大量采用了這種技術,
到此為止了嗎?
Prometheus 警報不僅包含 Prometheus 本身,還包含用于警報治理的 Alertmanager,我們可以看一看上面那張指標計算示意圖的全圖:
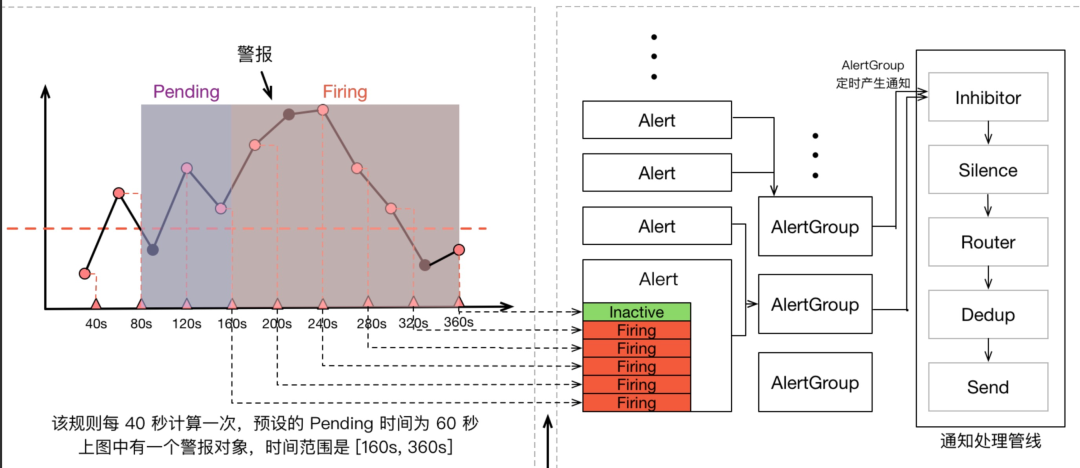
在警報產生后,還要經過 Alertmanager 的分組、抑制處理、靜默處理、去重處理和降噪處理最后再發送給接收者,而這個程序也有大量的因素可能會導致警報產生了卻最終 沒有進行通知,
為什么要 Alertmanager?
我們先介紹一點背景知識,Prometheus 生態中的警報是在 Prometheus Server 中計算警報規則(Alert Rule)并產生的,而所謂計算警報規則,其實就是周期性地執行一段 PromQL,得到的查詢結果就是警報,比如:
node_load5 > 20
這個 PromQL 會查出所有”在最近一次采樣中,5分鐘平均 Load 大于 20”的時間序列,這些序列帶上它們的標簽就被轉化為警報,
只是,當 Prometheus Server 計算出一些警報后,它自己并沒有能力將這些警報通知出去,只能將警報推給 Alertmanager,由 Alertmanager 進行發送,
這個切分,一方面是出于單一職責的考慮,讓 Prometheus “do one thing and do it well”, 另一方面則是因為警報發送確實不是一件”簡單”的事,需要一個專門的系統來做好它,可以這么說,Alertmanager 的目標不是簡單地”發出警報”,而是”發出高質量的警報”,它提供的高級功能包括但不限于:
Go Template 渲染警報內容;
-
管理警報的重復提醒時機與消除后消除通知的發送;
-
根據標簽定義警報路由,實作警報的優先級、接收人劃分,并針對不同的優先級和接收人定制不同的發送策略;
-
將同型別警報打包成一條通知發送出去,降低警報通知的頻率;
-
支持靜默規則: 用戶可以定義一條靜默規則,在一段時間內停止發送部分特定的警報,比如已經確認是搜索集群問題,在修復搜索集群時,先靜默掉搜索集群相關警報;
-
支持”抑制”規則(Inhibition Rule): 用戶可以定義一條”抑制”規則,規定在某種警報發生時,不發送另一種警報,比如在”A 機房網路故障”這條警報發生時,不發送所有”A 機房中的警報”;
假如你很忙,那么讀到這里就完全 OK 了,反正這類文章最大的作用就是讓我們”知道有 X 這回事,大概了解有啥特性,當有需求匹配時,能想到試試看 X 合不合適“,其中 X = Alertmanager,當然,假如你是個好奇寶寶,那么還可以看看下面的決議,
Alertmanager 內部架構
先看官方檔案中的架構圖:
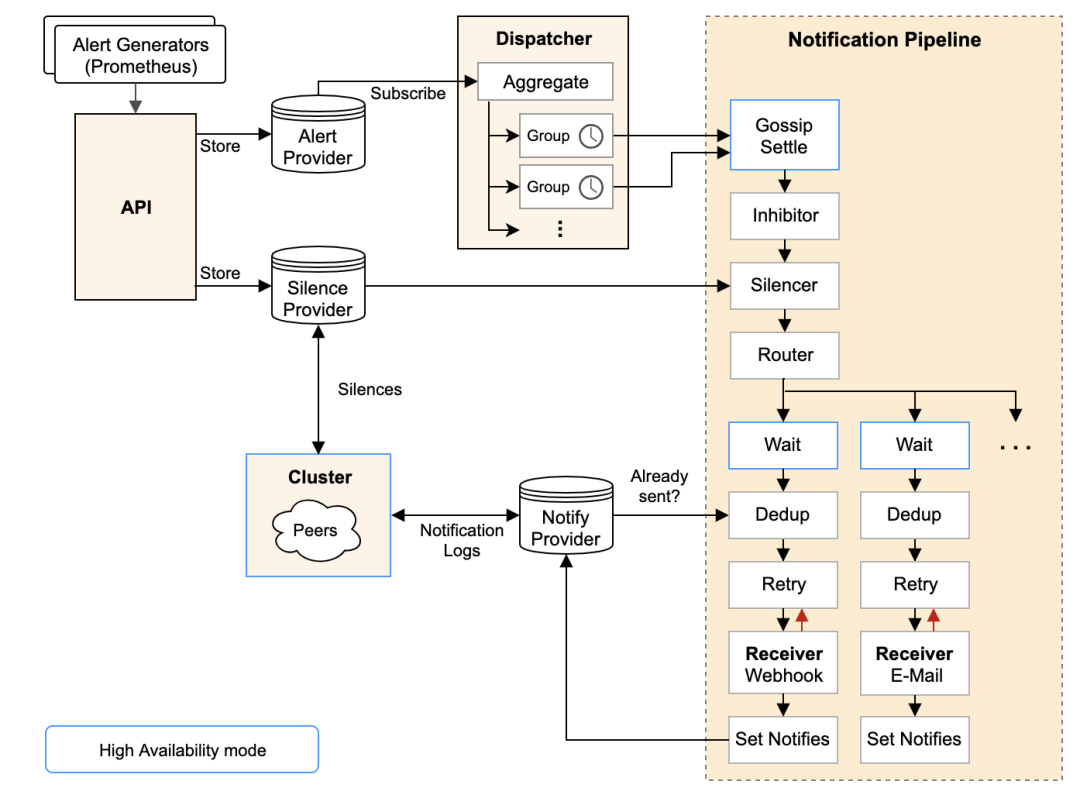
-
從左上開始,Prometheus 發送的警報到 Alertmanager;
-
警報會被存盤到 AlertProvider 中,Alertmanager 的內置實作就是包了一個 map,也就是存放在本機記憶體中,這里可以很容易地擴展其它 Provider;
-
Dispatcher 是一個單獨的 goroutine,它會不斷到 AlertProvider 拉新的警報,并且根據 YAML 配置的 Routing Tree 將警報路由到一個分組中;
-
分組會定時進行 flush (間隔為配置引數中的 group_interval), flush 后這組警報會走一個 Notification Pipeline 鏈式處理;
-
Notification Pipeline 為這組警報確定發送目標,并執行抑制邏輯,靜默邏輯,去重邏輯,發送與重試邏輯,實作警報的最終投遞;
下面就分開講一講核心的兩塊:
-
Dispatcher 中的 Routing Tree 的實作與設計意圖
-
Notification Pipeline 的實作與設計意圖
Routing Tree
Routing Tree 的是一顆多叉樹,節點的資料結構定義如下:
// 節點包含警報的路由邏輯
type Route struct {
// 父節點
parent *Route
// 節點的配置,下文詳解
RouteOpts RouteOpts
// Matchers 是一組匹配規則,用于判斷 Alert 與當前節點是否匹配
Matchers types.Matchers
// 假如為 true, 那么 Alert 在匹配到一個節點后,還會繼續往下匹配
Continue bool
// 子節點
Routes []*Route
}
具體的處理代碼很簡單,深度優先搜索:警報從 root 開始匹配(root 默認匹配所有警報),然后根據節點中定義的 Matchers 檢測警報與節點是否匹配,匹配則繼續往下搜索,默認情況下第一個”最深”的 match (也就是 DFS 回溯之前的最后一個節點)會被回傳,特殊情況就是節點配置了 Continue=true,這時假如這個節點匹配上了,那不會立即回傳,而是繼續搜索,用于支持警報發送給多方這種場景(比如”抄送”)
深度優先搜索
func (r *Route) Match(lset model.LabelSet) []*Route {
if !r.Matchers.Match(lset) {
return nil
}
var all []*Route
for _, cr := range r.Routes {
// 遞回呼叫子節點的 Match 方法
matches := cr.Match(lset)
all = append(all, matches...)
if matches != nil && !cr.Continue {
break
}
}
// 假如沒有任何節點匹配上,那就匹配根節點
if len(all) ==0 {
all = append(all, r)
}
return all
}
為什么要設計一個復雜的 Routing Tree 邏輯呢?我們看看 Prometheus 官方的配置例子:為了簡化撰寫,Alertmanager 的設計是根節點的所有引數都會被子節點繼承(除非子節點重寫了這個引數)
route:
# 根節點的警報會發送給默認的接收組
# 該節點中的警報會按’cluster’和’alertname’做 Group,每個分組中最多每5分鐘發送一條警報,同樣的警報最多4小時發送一次
receiver:’default-receiver’
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [cluster, alertname]
# 沒有匹配到子節點的警報,會默認匹配到根節點上
# 接下來是子節點的配置:
routes:
# 所有 service 欄位為 mysql 或 cassandra 的警報,會發送到’database-pager’這個接收組
# 由于繼承邏輯,這個節點中的警報仍然是按’cluster’和’alertname’做 Group 的
- receiver:’database-pager’
group_wait: 10s
match_re:
service: mysql|cassandra
# 所有 team 欄位為 fronted 的警報,會發送到’frontend-pager’這個接收組
# 很重要的一點是,這個組中的警報是按’product’和’environment’做分組的,因為’frontend’面向用戶,更關心哪個’產品’的什么’環境’出問題了
- receiver:’frontend-pager’
group_by: [product, environment]
match:
team: frontend
總結一下,Routing Tree 的設計意圖是讓用戶能夠非常自由地給警報歸類,然后根據歸類后的類別來配置要發送給誰以及怎么發送:
發送給誰?上面已經做了很好的示例,’資料庫警報’和’前端警報’都有特定的接收組,都沒有匹配上那么就是’默認警報’, 發送給默認接收組
怎么發送?對于一類警報,有個多個欄位來配置發送行為:
-
group_by
決定了警報怎么分組,每個 group 只會定時產生一次通知,這就達到了降噪的效果,而不同的警報類別分組方式顯然是不一樣的,舉個例子:配置中的 ‘資料庫警報’ 是按 ‘集群’ 和 ‘規則名’ 分組的,這表明對于資料庫警報,我們關心的是“哪個集群的哪個規則出問題了”,比如一個時間段內,’華東’集群產生了10條 ‘API回應時間過長’ 警報,這些警報就會聚合在一個通知里發出來;配置中的 ‘前端警報’ 是按 ‘產品’ 和 ‘環境’ 分組的, 這表明對于前端警報,我們關心的是“哪個產品的哪個環境出問題了”,
-
group_interval 和 group_wait
控制分組的細節,不細談,其中 group_interval 控制了這個分組最快多久執行一次 Notification Pipeline,
-
repeat_interval
假如一個相同的警報一直 FIRING,Alertmanager 并不會一直發送警報,而會等待一段時間,這個等待時間就是 repeat_interval,顯然,不同型別警報的發送頻率也是不一樣的,
group_interval 和 repeat_interval 的區別會在下文中詳述,
Notification Pipeline
由 Routing Tree 分組后的警報會觸發 Notification Pipeline:
當一個 AlertGroup 新建后,它會等待一段時間(group_wait 引數),再觸發第一次 Notification Pipeline 假如這個 AlertGroup 持續存在,那么之后每隔一段時間(group_interval 引數),都會觸發一次 Notification Pipeline 每次觸發 Notification Pipeline,AlertGroup 都會將組內所有的 Alert 作為一個串列傳進 Pipeline, Notification Pipeline 本身是一個按照責任鏈模式設計的介面,MultiStage 這個實作會鏈式執行所有的 Stage:
// A Stage processes alerts under the constraints of the given context.
type Stage interface {
Exec(ctx context.Context, l log.Logger, alerts …*types.Alert) (context.Context, []*types.Alert, error)
}
// A MultiStage executes a series of stages sequencially.
type MultiStage []Stage
// Exec implements the Stage interface.
func (ms MultiStage) Exec(ctx context.Context, l log.Logger, alerts …*types.Alert) (context.Context, []*types.Alert, error) {
var err error
for _, s := range ms {
if len(alerts) ==0{
return ctx, nil, nil
}
ctx, alerts, err = s.Exec(ctx, l, alerts…)
if err != nil {
return ctx, nil, err
}
}
return ctx, alerts, nil
}
MultiStage 里塞的就是開頭架構圖里畫的 InhibitStage、SilenceStage…這么一條鏈式處理的流程,這里要提一下,官方的架構圖畫錯了,RoutingStage 其實處在整個 Pipeline 的首位,不過這個順序并不影響邏輯,要重點說的是DedupStage和NotifySetStage它倆協同負責去重作業,具體做法是:
-
NotifySetStage 會為發送成功的警報記錄一條發送通知,key 是’接收組名字’+’GroupKey 的 key 值’,value 是當前 Stage 收到的 []Alert (這個串列和最開始進入 Notification Pipeline 的警報串列有可能是不同的,因為其中有些 Alert 可能在前置 Stage 中已經被過濾掉了)
-
DedupStage 中會以’接收組名字’+’GroupKey 的 key 值’為 key 查詢通知記錄,假如:
查詢無結果,那么這條通知沒發過,為這組警報發送一條通知;
查詢有結果,那么查詢得到已經發送過的一組警報 S,判斷當前的這組警報 A 是否為 S 的子集:
假如 A 是 S 的子集,那么表明 A 和 S 重復,這時候要根據 repeat_interval 來決定是否再次發送:
距離 S 的發送時間已經過去了足夠久(repeat_interval),那么我們要再發送一遍;
距離 S 的發送時間還沒有達到 repeat_interval,那么為了降低警報頻率,觸發去重邏輯,這次我們就不發了;
假如 A 不是 S 的子集,那么 A 和 S 不重復,需要再發送一次;上面的表述可能有些抽象,最后表現出來的結果是:
-
假如一個 AlertGroup 里的警報一直發生變化,那么雖然每次都是新警報,不會被去重,但是由于 group_interval (假設是5分鐘)存在,這個 AlertGroup 最多 5 分鐘觸發一次 Notification Pipeline,因此最多也只會 5 分鐘發送一條通知;
-
假如一個 AlertGroup 里的警報一直不變化,就是那么幾條一直 FIRING 著,那么雖然每個 group_interval 都會觸發 Notification Pipeline,但是由于 repeate_interval(假設是1小時)存在,因此最多也只會每 1 小時為這個重復的警報發送一條通知;再說一下 Silence 和 Inhibit,兩者都是基于用戶主動定義的規則的:
-
Silence Rule:靜默規則用來關閉掉部分警報的通知,比如某個性能問題已經修復了,但需要排期上線,那么在上線前就可以把對應的警報靜默掉來減少噪音;
-
Inhibit Rule:抑制規則用于在某類警報發生時,抑制掉另一類警報,比如某個機房宕機了,那么會影響所有上層服務,產生級聯的警報洪流,反而會掩蓋掉根本原因,這時候抑制規則就有用了;因此 Notification Pipeline 的設計意圖就很明確了:通過一系列邏輯(如抑制、靜默、去重)來獲得更高的警報質量,由于警報質量的維度很多(剔除重復、類似的警報,靜默暫時無用的警報,抑制級聯警報),因此 Notification Pipeline 設計成了責任鏈模式,以便于隨時添加新的環節來優化警報質量,
結語
Alertmanager 整體的設計意圖就是奔著治理警報(通知)去的,首先它用 Routing Tree 來幫助用戶定義警報的歸類與發送邏輯,然后再用 Notification Pipeline 來做抑制、靜默、去重以提升警報質量,這些功能雖然不能解決”警報”這件事中所有令人頭疼的問題,但確實為我們著手去解決”警報質量”相關問題提供了趁手的工具,
來源丨網址:
https://aleiwu.com/post/alertmanager/
https://aleiwu.com/post/prometheus-alert-why/
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/The-easiest-to-understand-Prometheus-alarm-principle.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/544990.html
標籤:其他