我們是袋鼠云數堆疊 UED 團隊,致力于打造優秀的一站式資料中臺產品,我們始終保持工匠精神,探索前端道路,為社區積累并傳播經驗價值,
本文作者:景明
我們以一段 C 代碼為例,來看一下代碼被編譯成二進制可執行程式之后,是如何被 CPU 執行的,
在這段代碼中,只是做了非常簡單的加法操作,將 x 和 y 兩個數字相加得到 z,并回傳結果 z,
int main() {
int x = 1;
int y = 2;
int z = x + y;
return z;
}
我們知道,CPU 并不能直接執行這段 C 代碼,而是需要對其進行編譯,將其轉換為二進制的機器碼,然后 CPU 才能按照順序執行編譯后的機器碼,
先通過 GCC 編譯器將這段 C 代碼編譯成二進制檔案,輸入以下命令讓其編譯成目的檔案:
gcc -O0 -o code_prog code.c
輸入上面的命令之后回車,在檔案夾中生成名為 code_prog 的可執行程式,接下來再將編譯出來的 code_prog 程式進行反匯編,這樣就可以看到二進制代碼和對應的匯編代碼,可以使用 objdump 的完成該任務,命令如下所示:
objdump -d code_prog
最后編譯出來的機器碼如下:
0000000100003f84 <_main>:
100003f84: ff 43 00 d1 sub sp, sp, #16 // 開辟堆疊空間,即開辟了四個 4 位元組空間
100003f88: ff 0f 00 b9 str wzr, [sp, #12] // 將 wzr 暫存器的資料存盤到 sp 暫存器的 #12 地址上,設為0
100003f8c: 28 00 80 52 mov w8, #1 // 創建一個 x = 1,并將 1 存入 w8 暫存器中
100003f90: e8 0b 00 b9 str w8, [sp, #8] // 將 w8 暫存器的資料存入 sp 暫存器中 #8 的地址中,也就是將 x = 1 存入
100003f94: 48 00 80 52 mov w8, #2 // 創建一個 y = 2,并將 2 存入 w8 暫存器中
100003f98: e8 07 00 b9 str w8, [sp, #4] // 將 w8 暫存器的資料存入 sp 暫存器中 #4 的地址中,也就是將 y = 2 存入
100003f9c: e8 0b 40 b9 ldr w8, [sp, #8] // 讀取 sp 暫存器中 #8 的資料存入 w8 暫存器中,也就是獲取 x = 1
100003fa0: e9 07 40 b9 ldr w9, [sp, #4] // 讀取 sp 暫存器中 #4 的資料存入 w9 暫存器中,也就是獲取 y = 2
100003fa4: 08 01 09 0b add w8, w8, w9 // 將 w8、w9 暫存器的 x,y 資料進行相加,并存入 w8 暫存器中,也就是 z = 3
100003fa8: e8 03 00 b9 str w8, [sp] // 將 w8 暫存器的資料存入 sp 暫存器中
100003fac: e0 03 40 b9 ldr w0, [sp] // 讀取 sp 暫存器中的資料存到 w0 暫存器中,z = 3
100003fb0: ff 43 00 91 add sp, sp, #16 // 清空開辟的堆疊空間
100003fb4: c0 03 5f d6 ret // 回傳結果
PS: wzr 為 32 的零暫存器,專門用來清零,也就是 sp 上 #12 指向的資料設定為 0
觀察上方,左邊就是編譯生成的機器碼,在這里它是使用十六進制來展示的,這主要是因為十六進制比較容易閱讀,所以通常使用十六進制來展示二進制代碼,
可以觀察到上圖是由很多行組成的,每一行都是一個指令,該指令可以讓 CPU 執行指定的任務,
中間的部分是匯編代碼,例如原本是二進制表示的指令,在匯編代碼中可以使用單詞來表示,比如 mov、add 就分別表示資料的存盤和相加,
通常將匯編語言撰寫的程式轉換為機器語言的程序稱為“匯編”;反之,機器語言轉化為匯編語言的程序稱為“反匯編”,比如上圖就是對 code_prog 行程進行了反匯編操作,
右邊添加的注釋,表示每條指令的具體含義,
這一大堆指令按照順序集合在一起就組成了程式,所以程式的執行,本質上就是 CPU 按照順序執行這一大堆指令的程序,
CPU 是怎么執行程式的?
為了更好的分析程式的執行程序,我們還需要了解一下基礎的計算機硬體資訊,具體如下圖:
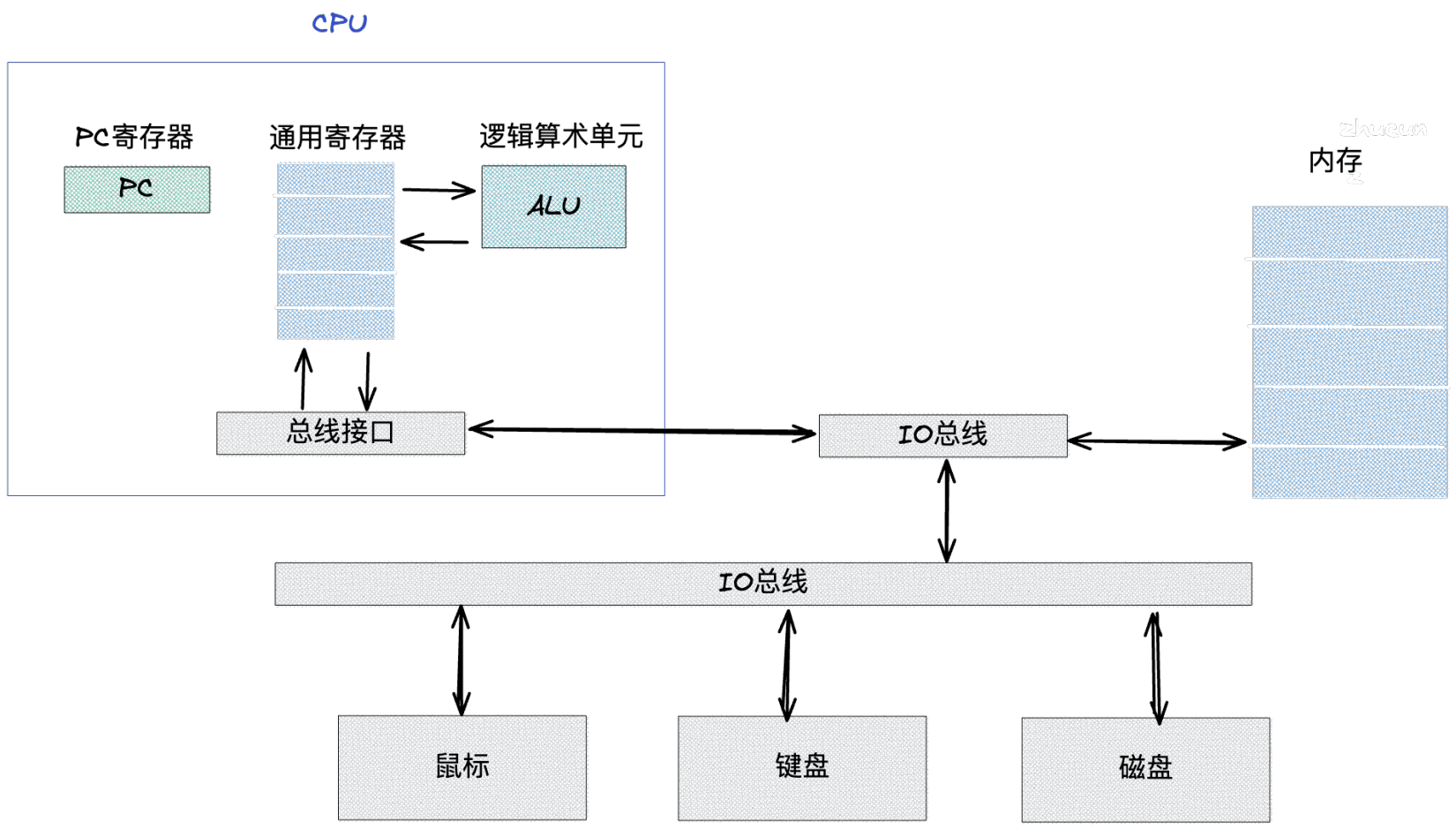
這張圖是比較通用的系統硬體組織模型圖,它主要是由 CPU、主存盤器、各種 IO 總線,還有一些外部設備組成的,
首先,在一個程式執行之前,程式需要被裝進記憶體,比如在 macOS 下面,你可以通過滑鼠點擊一個可執行檔案,當你點擊該檔案的時候,系統中的程式加載器會將該檔案加載到記憶體中,
CPU 可以通過指定記憶體地址,從記憶體中讀取資料,或者往記憶體中寫入資料,有了記憶體地址,CPU 和記憶體就可以有序地互動,
記憶體中的每個存盤空間都有其對應的獨一無二的地址:

在記憶體中,每個存放位元組的空間都有其唯一的地址,而且地址是按照順序排放的,
以開頭代碼為例,這段代碼會被編譯成可執行檔案,可執行檔案中包含了二進制的機器碼,當二進制代碼被加載進了記憶體后,那么記憶體中的每條二進制代碼便都有了自己對應的地址,如下圖所示:
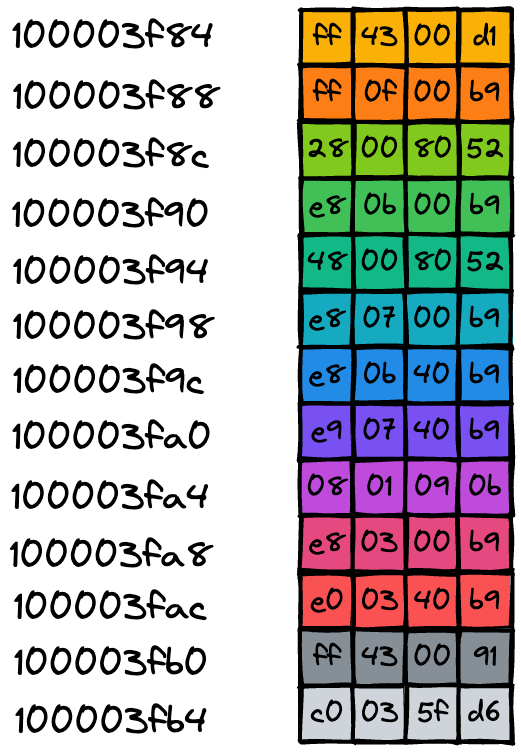
一旦二進制代碼被裝載進記憶體,CPU 便可以從記憶體中取出一條指令,然后分析該指令,最后執行該指令,
把取出指令、分析指令、執行指令這三個程序稱為一個 CPU 時鐘周期,CPU 是永不停歇的,當它執行完成一條指令之后,會立即從記憶體中取出下一條指令,接著分析該指令,執行該指令,CPU 一直重復執行該程序,直至所有的指令執行完成,
CPU 是怎么知道要取出記憶體中的哪條指令呢?:
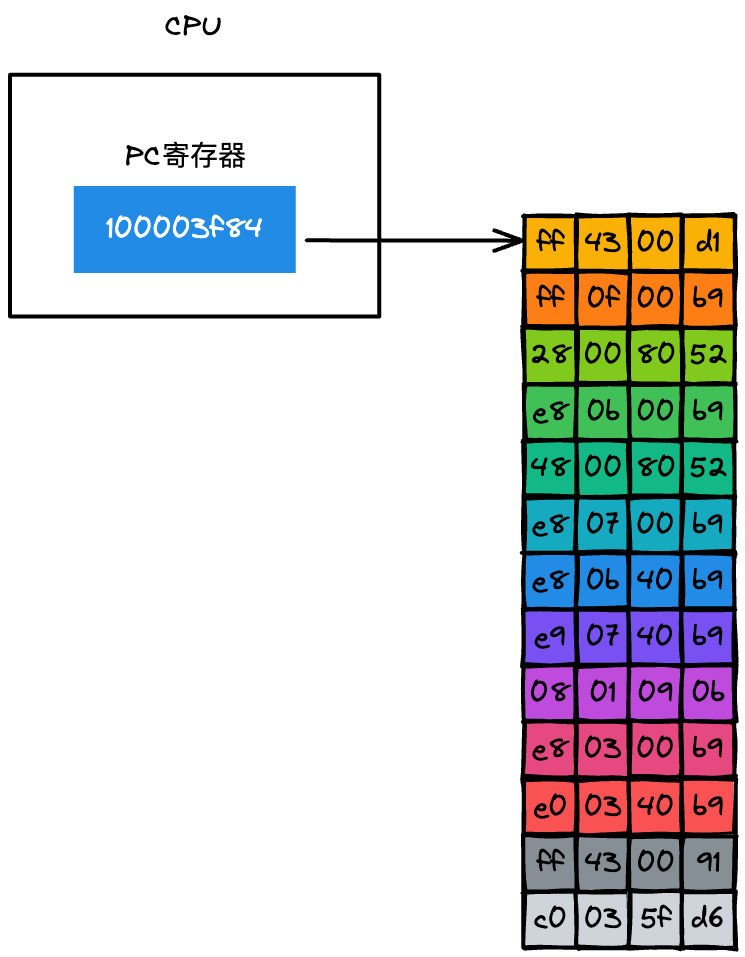
從上圖可以看到 CPU 中有一個 PC 暫存器,它保存了將要執行的指令地址,當二進制代碼被裝載進了記憶體之后,系統會將二進制代碼中的第一條指令的地址寫入到 PC 暫存器中,到了下一個時鐘周期時,CPU 便會根據 PC 暫存器中的地址,從記憶體中取出指令,
PC 暫存器中的指令取出來之后,系統要做兩件事:第一件是將下一條指令的地址更新到 PC 暫存器中,如下圖所示:
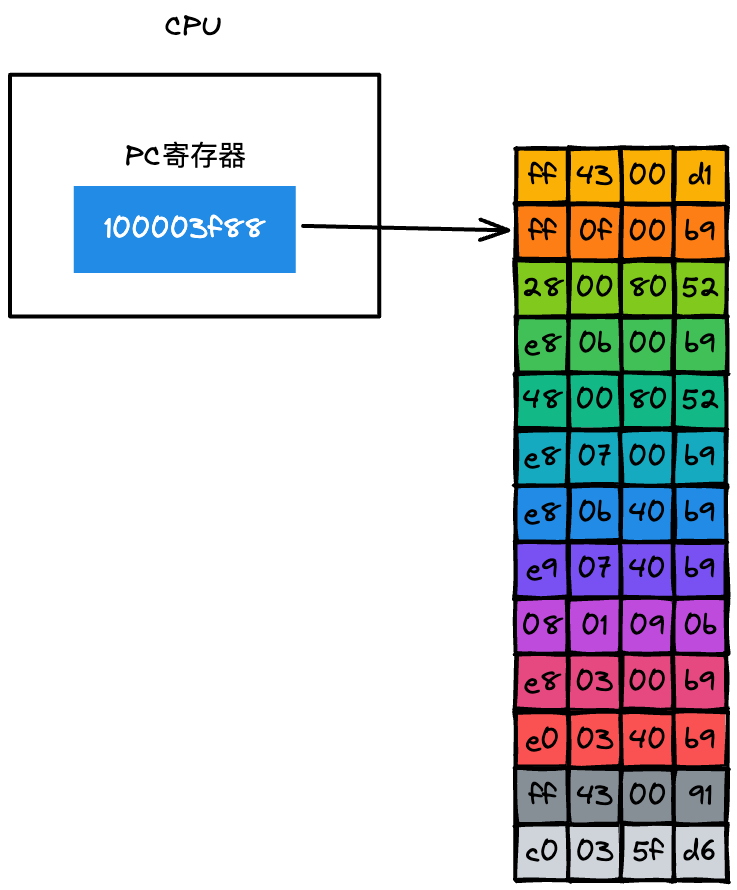
更新了 PC 暫存器之后,CPU 就會立即做第二件事,那就是分析該指令,并識別出不同的型別的指令,以及各種獲取運算元的方法,
在指令分析完成之后,就要執行指令了,
在執行指令前,我們還需要認識一下 CPU 中的重要部件:暫存器,
暫存器
暫存器是 CPU 中用來存放資料的設備,不同處理器中暫存器的個數也是不一樣的,之所要暫存器,是因為 CPU 訪問記憶體的速度很慢,所以 CPU 就在內部添加了一些存盤設備,這些設備就是暫存器,
他們的讀取速度如下:
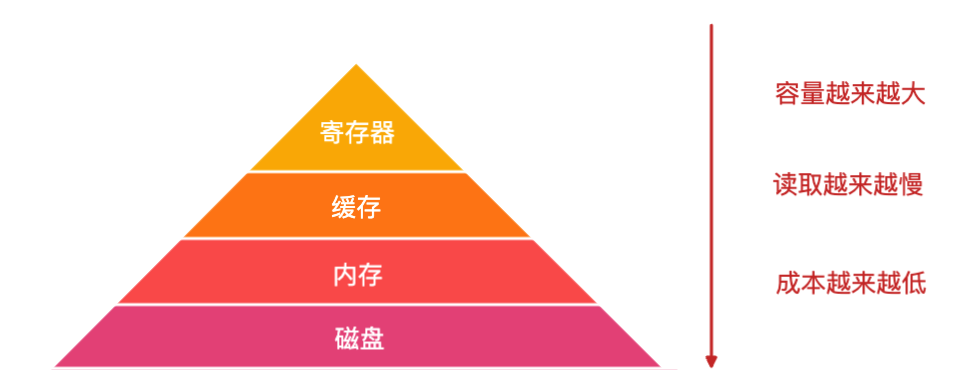
總結來說,暫存器容量小,讀寫速度快,記憶體容量大,讀寫速度慢,
暫存器通常用來存放資料或者記憶體中某塊資料的地址,我們把這個地址又稱為指標,通常情況下暫存器對存放的資料是沒有特別的限制的,比如某個通用暫存器既可以存盤資料,也可以存盤指標,
不過由于歷史原因,我們還會將某些專用的資料或者指標存盤在專用的通用暫存器中 ,比如 rbp 暫存器通常用來存放堆疊幀指標的,rsp 暫存器用來存放堆疊頂指標的,PC 暫存器用來存放下一條要執行的指令等,
特殊暫存器
Stack Pointer register(SP)
The use of SP as an operand in an instruction, indicates the use of the current stack pointer.
指向當前堆疊指標,堆疊指標總是指向堆疊頂位置,一般堆疊的堆疊底不能動,所以資料入堆疊前要先修改堆疊指標,使它指向新的空余空間然后再把資料存進去,出堆疊的時候相反,
堆疊指標,隨時跟蹤堆疊頂地址,按"先進后出"的原則存取資料,
Link Register (LR)
連接暫存器,一是用來保存子程式回傳地址;二是當例外發生時,LR中保存的值等于例外發生時PC的值減4(或者減2),因此在各種例外模式下可以根據LR的值回傳到例外發生前的相應位置繼續執行,
Program Counter(PC)
A 64-bit Program Counter holding the address of the current instruction.
保存了將要執行的指令地址
Word Zero Register(WZR)
零暫存器,用于給int清零
tips
不同指令中暫存器后 #d 有什么區別?
[#d]在ARM代表的是一個常數運算式,
如:#0x3FC、#0、#0xF0000000、#200、#0xF0000001
都是代表著一個常數,
在 sp 暫存器中,代表的是當前堆疊頂指標移動的位置,
如:
sub sp, sp, #16;// 獲取 sp 中的堆疊頂指標移動 16位的位置,并把位置更新到 sp 暫存器中,實作開辟空間
在通用暫存器 W0 - W11 中,代表的操作的常數值,
mov w8, #2,// 把常數 2 添加到 w8 暫存器中
通用暫存器
以下介紹下比較常見的通用暫存器:
- 其中W0~W3 用于函式呼叫入參,其中,W0 還用于程式的回傳值.
- W4~W11用于保存區域變數,
- W13為SP,時刻指向堆疊頂,當有資料入堆疊或出堆疊時,需要更新SP
- W14為鏈接暫存器,主要是用作保存子程式回傳的地址,
- W15為PC暫存器,指向將要執行的下一條指令地址,
常見指令
mov
資料傳送指令,將立即數或暫存器(operant2)傳送到目標暫存器Rd,可用于移位運算等操作,指令格式如下:
MOV{cond}{S} Rd,operand2
如:
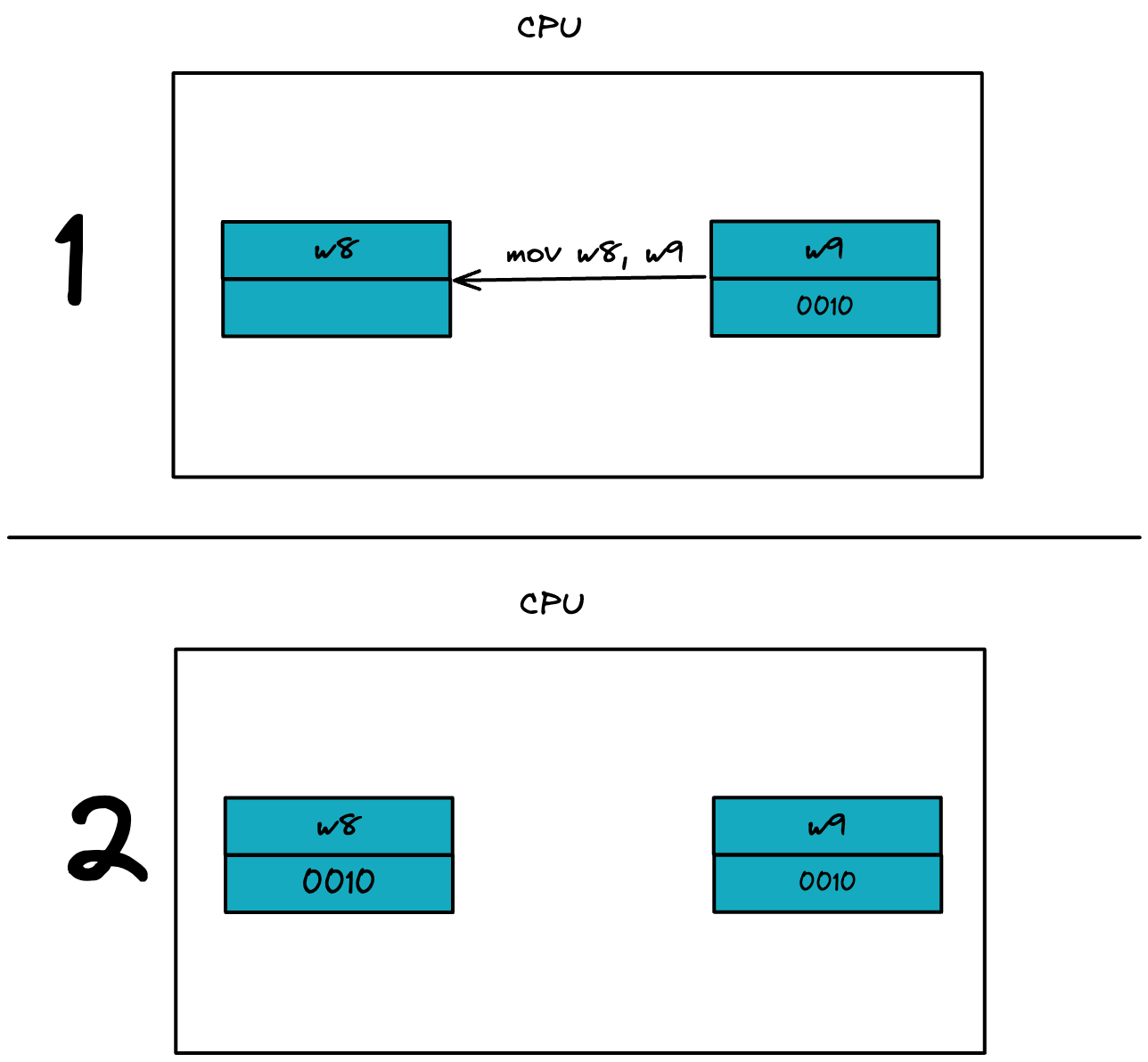
mov w8, #1,就是往 w8 暫存器中寫入 #1.
mov w8, w9, 就是把 w9 暫存器的資料發送到 w8 暫存器中,最終 w8 和 w9 暫存器的資料一致,如下圖:
ldr
ldr 從記憶體中讀取資料放入暫存器中
LDR{cond}{T} Rd,<地址>;加載指定地址上的資料(字),放入Rd中
如:
ldr w8, [sp, #8] 讀取 sp 暫存器中 #8 位置的資料存入 w8 暫存器中,改變的只有 w8 ,sp 暫存器不變
str
str 指令用于將暫存器中的資料保存到記憶體
STR{cond}{T} Rd,<地址>;存盤資料(字)到指定地址的存盤單元,要存盤的資料在Rd中
如:
str w8, [sp] , 將 w8 暫存器的資料存入 sp 暫存器中
add
加法運算指令,將operand2 資料與Rn 的值相加,結果保存到Rd 暫存器,指令格式如下:
ADD{cond}{S} Rd,Rn,operand2
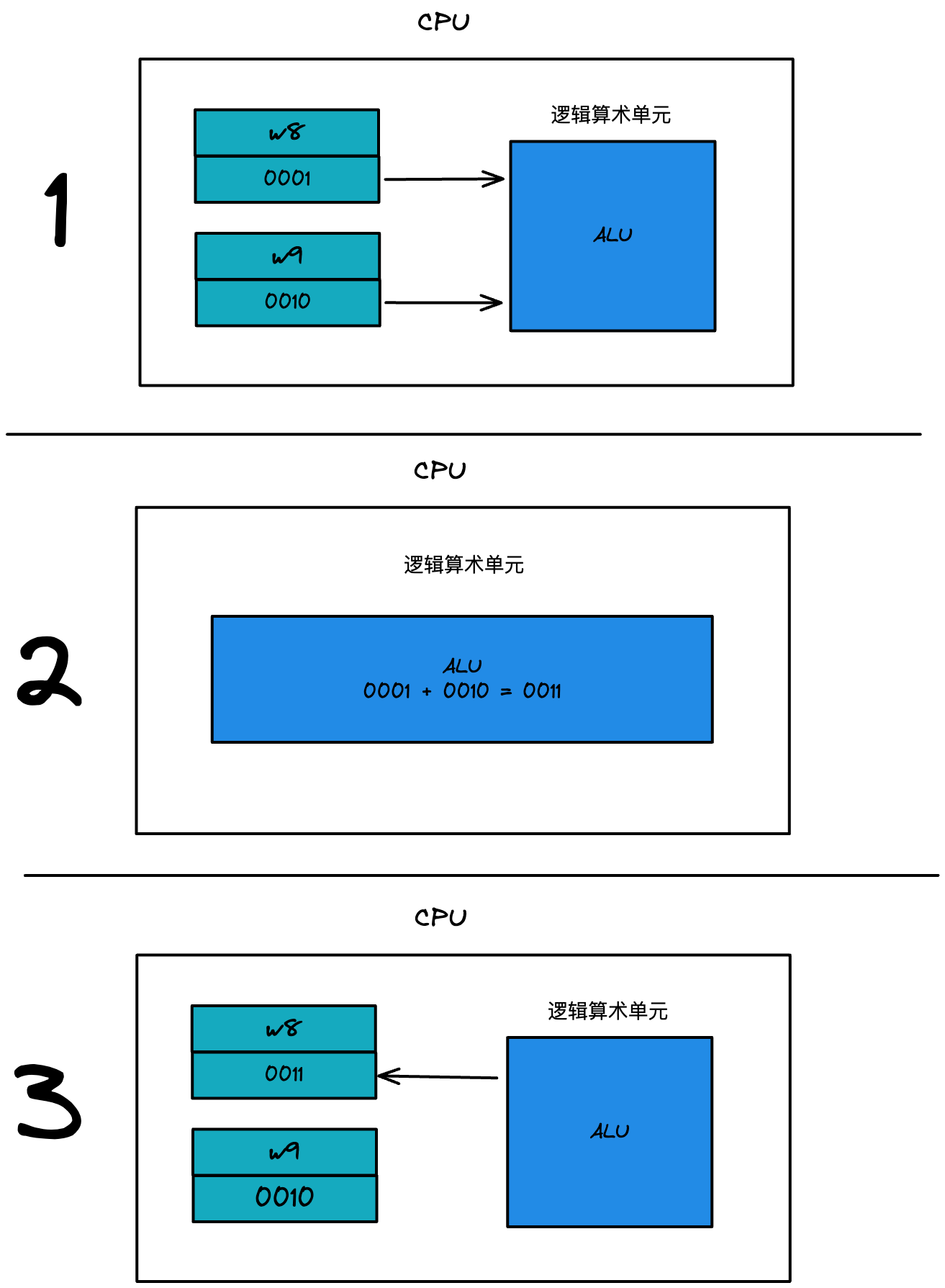
以 add w8, w8, w9 為例,就是把 w8、w9 暫存器的 x,y 資料進行相加,并存入 w8 暫存器中
如下圖:
sub
減法運算指令,用暫存器 Rn 減去operand2,結果保存到 Rd 中,指令格式如下:
SUB{cond}{S} Rd,Rn,operand2
如:
sub R0,R0,#1 -- R0=R0-1
執行程序
了解了以上的知識,我們再來分析一遍代碼的執行程序,
在 C 程式中,CPU 會首先執行呼叫 main 函式,在呼叫 main 函式時,生成一塊記憶體空間,用來存放 main 函式執行程序中的資料,
sub sp, sp, #16
將 0 寫入到 #12 的位元組位置上,
str wzr, [sp, #12]
接下來給 x 附值
mov w8, #1
str w8, [sp, #8]
第一行指令是把 1 添加進暫存器中,第二行指令是把 1 存入 #8 地址的記憶體空間中,
接著給 y 附值
mov w8, #2
str w8, [sp, #4]
第一行指令是把 2 添加進暫存器中,第二行指令是把 2 存入 #4 地址的記憶體空間中,
執行完 x, y 的生成,接下來執行 z = x + y
ldr w8, [sp, #8]
ldr w9, [sp, #4]
add w8, w8, w9
第一行指令取出記憶體空間地址為 #8 的資料,也就是 1. 第二行指令去除記憶體空間地址為 #4 的資料,也就是 2,第三行指令則對取出的資料進行相加操作,并將結果 3 存入暫存器中,
str w8, [sp]
ldr w0, [sp]
第一行指令把暫存器中的最終的資料存入記憶體中,第二行指令則獲取記憶體中的結果,存入暫存器中,等待回傳
add sp, sp, #16
把開辟的空間進行清理,
ret
回傳結果
總結
本文主要講解了 CPU 的執行程序,順便了解了一下基礎的計算機硬體資訊,如有想法??歡迎討論!!!
參考
-《圖解 Google V8》- 李兵
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/548750.html
標籤:其他