一、互聯網&上網
1、互聯網
what :互聯網=物理連接介質+互聯網協議
why:資料傳輸打破地域限制,否則的話,我想獲得對方主機上的資料,只能拿著硬碟去對方主機拷貝
2、上網
what:用戶上網的程序即瀏覽器向服務端發送請求,然后將服務端主機的文本檔案下載到本地顯示的程序,而瀏覽器與服務器之間走的HTTP協議,
二、HTTP協議簡介
1、全稱 Hyper Text Transfer Protocol(超文本傳輸協議)
HTTP協議是用于從(WWW:World Wide Web,簡萬維網 )服務器傳輸超文本到本地瀏覽器的傳送協議,
2、HTTP協議作業于B/S架構上
瀏覽器作為HTTP客戶端通過URL向HTTP服務端即WEB服務器發送請求Request,
Web服務器根據接收到的請求后,向客戶端發送回應資訊Response,
3、HTTP協議是基于TCP/IP通信協議來傳遞資料的(HTML 檔案, 圖片檔案等)
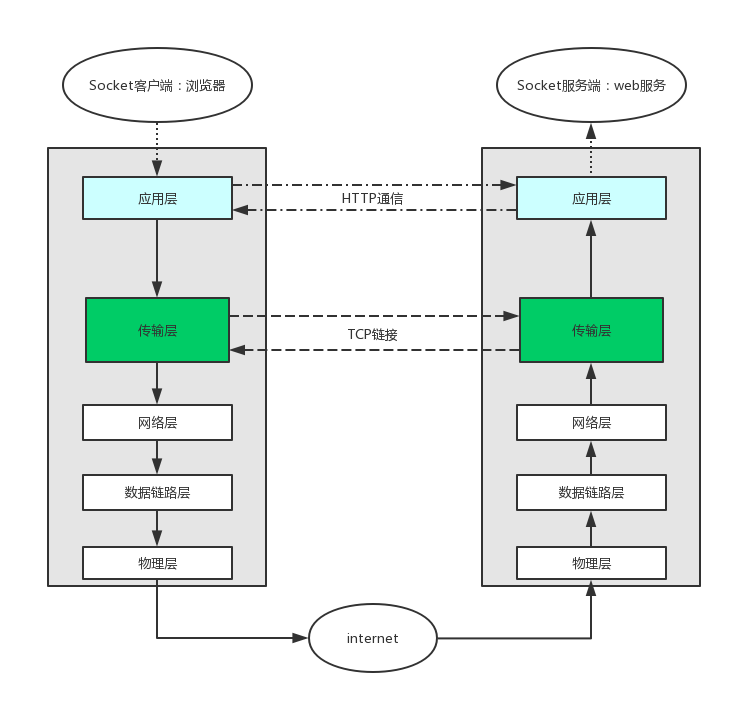
4、HTTP 協議作業原理
HTTP協議作業于客戶端-服務端架構上,瀏覽器作為HTTP客戶端通過URL向HTTP服務端即WEB服務器發送所有請求,
Web服務器有:Apache服務器,IIS服務器(Internet Information Services)等,
Web服務器根據接收到的請求后,向客戶端發送回應資訊,
HTTP默認埠號為80,但是你也可以改為8080或者其他埠,
HTTP三點注意事項: HTTP是無連接:無連接的含義是限制每次連接只處理一個請求,服務器處理完客戶的請求,并收到客戶的應答后,即斷開連接,采用這種方式可以節省傳輸時間, HTTP是媒體獨立的:這意味著,只要客戶端和服務器知道如何處理的資料內容,任何型別的資料都可以通過HTTP發送,客戶端以及服務器指定使用適合的MIME-type內容型別, HTTP是無狀態:HTTP協議是無狀態協議,無狀態是指協議對于事務處理沒有記憶能力,缺少狀態意味著如果后續處理需要前面的資訊,則它必須重傳,這樣可能導致每次連接傳送的資料量增大,另一方面,在服務器不需要先前資訊時它的應答就較快,
5、HTTP協議版本演化


=========HTTP/0.9========= 第一個HTTP協議誕生于1989年3月,已過時, #一:它的組成極其簡單: #1、只允許客戶端發送GET這一種請求 #2、不支持請求頭, #3、由于沒有請求頭,造成了HTTP 0.9協議只支持一種內容,即純文本,不過網頁仍然支持用HTML語言格式化,同時無法插入圖片, #二:無狀態性 #1、HTTP 0.9具有典型的無狀態性,每個事務獨立進行處理,事務結束時就釋放這個連接,詳細解釋如下: 一次HTTP 0.9的傳輸首先要建立一個由客戶端到Web服務器的TCP連接,由客戶端發起一個請求,然后由Web服務器回傳頁面內容,然后連接會關閉,如果請求的頁面不存在,也不會回傳任何錯誤碼, #2、由此可見,HTTP協議的無狀態特點在其第一個版本0.9中已經成型, #三 :HTTP 0.9協議檔案: http://www.w3.org/Protocols/HTTP/AsImplemented.html ========HTTP/1.0========== HTTP/1.0是HTTP協議的第二個版本,至今仍被廣泛采用,首次在通訊中指定版本號,相對于HTTP 0.9 增加了如下主要特性: #1、支持請求頭與回應頭 #2、Response回應以一個回應狀態行開始 #2.1、Response包含的內容不只限于超文本 #3、開始支持客戶端通過POST方法向Web服務器提交資料,并支持GET、HEAD、POST方法 #4、支持長連接Keepalive(但默認還是使用短連接) #5、快取機制以及身份認證 ========HTTP/1.1========== 下面會有詳細介紹 ========HTTP/2.0========== HTTP 2.0是下一代HTTP協議,目前應用還非常少,主要特點有: #1、多路復用(二進制分幀) HTTP 2.0最大的特點: 不會改動HTTP 的語意,HTTP 方法、狀態碼、URI 及首部欄位,等等這些核心概念上一如往常,卻能致力于突破上一代標準的性能限制,改進傳輸性能,實作低延遲和高吞吐量,而之所以叫2.0,是在于新增的二進制分幀層,在二進制分幀層上, HTTP 2.0 會將所有傳輸的資訊分割為更小的訊息和幀,并對它們采用二進制格式的編碼 ,其中HTTP1.x的首部資訊會被封裝到Headers幀,而我們的request body則封裝到Data幀里面, HTTP 2.0 通信都在一個連接上完成,這個連接可以承載任意數量的雙向資料流,相應地,每個資料流以訊息的形式發送,而訊息由一或多個幀組成,這些幀可以亂序發送,然后再根據每個幀首部的流識別符號重新組裝, #2、頭部壓縮 當一個客戶端向相同服務器請求許多資源時,像來自同一個網頁的影像,將會有大量的請求看上去幾乎同樣的,這就需要壓縮技術對付這種幾乎相同的資訊, #3、隨時復位 HTTP1.1一個缺點是當HTTP資訊有一定長度大小資料傳輸時,你不能方便地隨時停止它,中斷TCP連接的代價是昂貴的,使用HTTP2的RST_STREAM將能方便停止一個資訊傳輸,啟動新的資訊,在不中斷連接的情況下提高帶寬利用效率, #4、服務器端推流: Server Push 客戶端請求一個資源X,服務器端判斷也許客戶端還需要資源Z,在無需事先詢問客戶端情況下將資源Z推送到客戶端,客戶端接受到后,可以快取起來以備后用, #5、優先權和依賴 每個流都有自己的優先級別,會表明哪個流是最重要的,客戶端會指定哪個流是最重要的,有一些依賴引數,這樣一個流可以依賴另外一個流,優先級別可以在運行時動態改變,當用戶滾動頁面時,可以告訴瀏覽器哪個影像是最重要的,你也可以在一組流中進行優先篩選,能夠突然抓住重點流,版本演化
6、HTTP/1.1詳解
HTTP/1.1是HTTP協議的第三個版本,是目前主流的HTTP協議版本
HTTP 1.1引入了許多關鍵性能優化:keepalive連接,請求流水線,chunked編碼傳輸,位元組范圍請求等
(1)Persistent Connection(keepalive連接)
#1、長連接 允許HTTP設備在事務處理結束之后將TCP連接保持在打開的狀態,以便未來的HTTP請求重用現在的連接,直到客戶端或服務器端決定將其關閉為止, #2、HTTP1.1對比HTTP1.0? 在HTTP1.0中使用長連接需要添加請求頭 Connection: Keep-Alive,而在HTTP 1.1 所有的連接默認都是長連接,除非特殊宣告不支持( HTTP請求報文首部加上Connection: close )
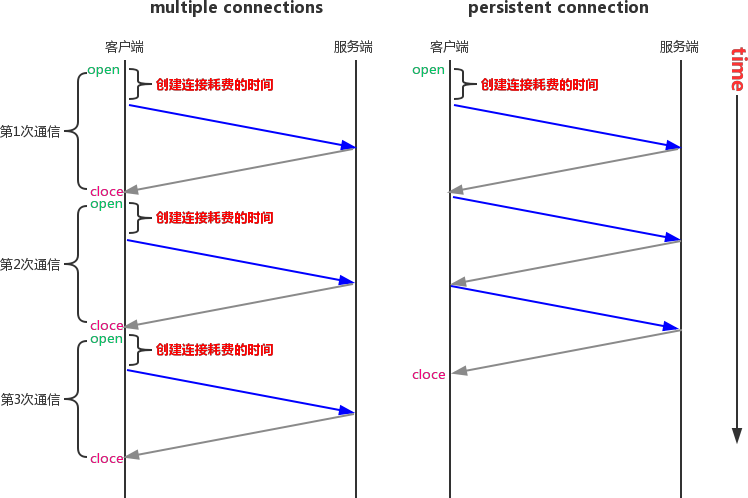
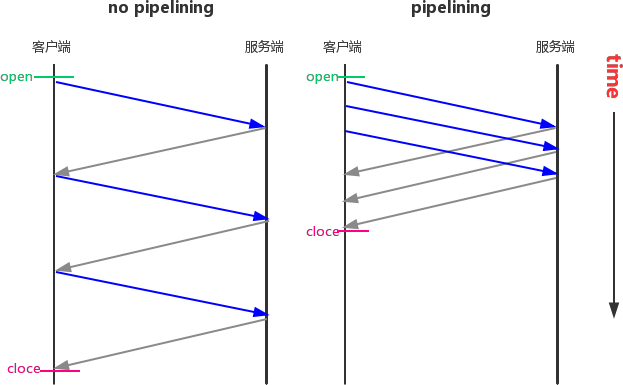
(2)Pipelining(請求流水線)
A client that supports persistent connections MAY "pipeline" its requests (i.e., send multiple requests without waiting for each response). A server MUST send its responses to those requests in the same order that the requests were received. 支持持久連接的客戶端可以“流水線”它的請求(即,發送多個請求而無需等待每個回應),服務器必須按照與收到請求的相同順序來向這些請求發送回應,
(3)chunked編碼傳輸
#1、介紹 該編碼將物體分塊傳送并逐塊標明長度,直到長度為0塊表示傳輸結束, 這在物體長度未知時特別有用(比如由資料庫動態產生的資料) #2、傳輸編碼和分塊編碼 當回應頭里包含Transfer-Encoding: chunked,代表分塊編碼,會把「報文」分割成若干個大小已知的塊,塊之間是緊挨著發送的,這樣就不需要在發送之前知道整個報文的大小了,也意味著不需要寫回Content-Length首部了, #3、分塊傳輸的應用 當使用持久連接時,在服務器發送主體內容之前,必須計算出主體內容的大小,然后放到回應頭里(Content-Length:主體的位元組數)發送給客戶端, 如果服務器動態創建內容,可能在發送之前無法知道主體大小,分塊編碼就是為了解決這種情況:服務器把主體逐塊發送,說明每一塊的大小,服務器再用大小為0的塊作為結束塊,,為下一個回應做準備,此時回應頭里便不再需要Content-Length了 除非使用了分塊編碼Transfer-Encoding: chunked,否則回應頭首部必須使用Content-Length首部, 摘自HTTP/1.1:https://tools.ietf.org/html/rfc2616 #4、關于Content-Length首部: 如果請求頭包含Accept-Encoding': 'gzip',則服務端會將內容壓縮后回傳,內容的Content-Length長度是壓縮后的長度, 如果請求頭不包含Accept-Encoding': 'gzip', 服務器就不會采取gzip壓縮,同時我司服務器設定也不進行分塊編碼,所以回傳回應頭的Content-Length首部是必須的,但是這個值的大小肯定是沒有進行過壓縮的檔案大小,
(4)位元組范圍請求
HTTP1.1支持傳送內容的一部分,比方說,當客戶端已經有內容的一部分,為了節省帶寬,可以只向服務器請求一部分,該功能通過在請求訊息中引入了range頭域來實作,它允許只請求資源的某個部分,在回應訊息中Content-Range頭域宣告了回傳的這部分物件的偏移值和長度,如果服務器相應地回傳了物件所請求范圍的內容,則回應碼206(Partial Content)
(5)HTTP 1.1還新增了如下特性:
#1、請求訊息和回應訊息都應支持Host頭域 在HTTP1.0中認為每臺服務器都系結一個唯一的IP地址,因此,請求訊息中的URL并沒有傳遞主機名(hostname),但隨著虛擬主機技術的發展,在一臺物理服務器上可以存在多個虛擬主機(Multi-homed Web Servers),并且它們共享一個IP地址,因此,Host頭的引入就很有必要了, #2、新增了一批Request method HTTP1.1增加了OPTIONS,PUT, DELETE, TRACE, CONNECT方法 #3、快取處理 HTTP/1.1在1.0的基礎上加入了一些cache的新特性,引入了物體標簽,一般被稱為e-tags,新增更為強大的Cache-Control頭,
三、HTTP 協議之訊息結構
HTTP是基于客戶端/服務端(C/S)的架構模型,通過一個可靠的鏈接來交換資訊,是一個無狀態的請求/回應協議,
一個HTTP"客戶端"是一個應用程式(Web瀏覽器或其他任何客戶端),通過連接到服務器達到向服務器發送一個或多個HTTP的請求的目的,
一個HTTP"服務器"同樣也是一個應用程式(通常是一個Web服務,如Apache Web服務器或IIS服務器等),通過接收客戶端的請求并向客戶端發送HTTP回應資料,
HTTP使用統一資源識別符號(Uniform Resource Identifiers, URI)來傳輸資料和建立連接,
一旦建立連接后,資料訊息就通過類似Internet郵件所使用的格式[RFC5322]和多用途Internet郵件擴展(MIME)[RFC2045]來傳送,
四、HTTP協議之請求Request
1、請求的URL
(1)什么是URI? HTTP使用統一資源識別符號(Uniform Resource Identifiers, URI)來傳輸資料和建立連接, (2)什么是URL? URL是一種特殊型別的URI,包含了用于查找某個資源的足夠的資訊 URL,全稱是UniformResourceLocator, 中文叫統一資源定位符,是互聯網上用來標識某一處資源的地址,
(3)舉例URL
#以下面這個URL為例,介紹下普通URL的各部分組成: http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name 一個完整的URL包括以下幾部分: #1.協議部分:http:// 該URL的協議部分為“http:”,在"HTTP"后面的“//”為分隔符,這代表網頁使用的是HTTP協議,在Internet中可以使用多種協議,如HTTP,FTP等等, ===>如果不寫,瀏覽器會自動補全,但必須有 #2.域名部分:www.aspxfans.com 一個URL中,也可以使用IP地址作為域名使用 ===>必須有 #3.埠部分:8080 跟在域名后面的是埠,域名和埠之間使用“:”作為分隔符, ===>埠不是一個URL必須的部分,如果省略埠部分,將采用默認埠80 #4.虛擬目錄部分:/news/ 從域名后的第一個“/”開始到最后一個“/”為止,是虛擬目錄部分, ===>虛擬目錄也不是一個URL必須的部分, #5.檔案名部分:index.asp 從域名后的最后一個“/”開始到“?”為止,是檔案名部分,如果沒有“?”,則是從域名后的最后一個“/”開始到“#”為止,是檔案部分,如果沒有“?”和“#”,那么從域名后的最后一個“/”開始到結束,都是檔案名部分, ===>檔案名部分也不是一個URL必須的部分,如果省略該部分,則使用默認的檔案名 #6.引數部分:boardID=5&ID=24618&page=1 從“?”開始到“#”為止之間的部分為引數部分,又稱搜索部分、查詢部分,引數可以允許有多個引數,引數與引數之間用“&”作為分隔符, ===>引數部分非必須 #7.錨部分:#name 從“#”開始到最后,都是錨部分, ===>錨部分也不是一個URL必須的部分
(4)URI與URL的區別
#1、URI,是uniform resource identifier,統一資源識別符號,用來唯一的標識一個資源, Web上可用的每種資源如HTML檔案、影像、視頻片段、程式等都是一個來URI來定位的 URI一般由三部組成: ①訪問資源的命名機制 ②存放資源的主機名 ③資源自身的名稱,由路徑表示,著重強調于資源, #2、URL是uniform resource locator,統一資源定位器,它是一種具體的URI,即URL可以用來標識一個資源,而且還指明了如何locate這個資源, URL是Internet上用來描述資訊資源的字串,主要用在各種WWW客戶程式和服務器程式上,特別是著名的Mosaic, 采用URL可以用一種統一的格式來描述各種資訊資源,包括檔案、服務器的地址和目錄等,URL一般由三部組成: ①協議(或稱為服務方式) ②存有該資源的主機IP地址(有時也包括埠號) ③主機資源的具體地址,如目錄和檔案名等 #3、URN,uniform resource name,統一資源命名,是通過名字來標識資源,比如mailto:[email protected], URI是以一種抽象的,高層次概念定義統一資源標識,而URL和URN則是具體的資源標識的方式,URL和URN都是一種URI,籠統地說,每個 URL 都是 URI,但不一定每個 URI 都是 URL,這是因為 URI 還包括一個子類,即統一資源名稱 (URN),它命名資源但不指定如何定位資源,上面的 mailto、news 和 isbn URI 都是 URN 的示例, 在Java的URI中,一個URI實體可以代表絕對的,也可以是相對的,只要它符合URI的語法規則,而URL類則不僅符合語意,還包含了定位該資源的資訊,因此它不能是相對的, 在Java類別庫中,URI類不包含任何訪問資源的方法,它唯一的作用就是決議, 相反的是,URL類可以打開一個到達資源的流,
2、Request請求的格式
客戶端發送一個HTTP請求到服務器的請求訊息格式為:請求行(request line)、請求頭部(header)、空行和請求資料四部分,
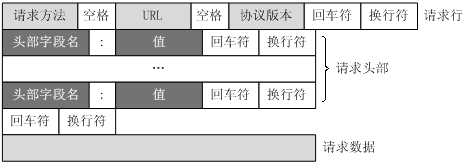
Request請求詳解:
請求行以一個方法GET或POST開頭,以空格分開,后面跟著請求的URI和協議的版本,詳細解釋如下 GET /linhaifeng/p/7278389.html HTTP/1.1 Host: www.cnblogs.com Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 #第一部分:請求行,用來說明請求型別,要訪問的資源以及所使用的HTTP版本. GET說明請求型別為GET /linhaifeng/p/7278389.html為要訪問的資源 該行的最后一部分說明使用的是HTTP1.1版本 #第二部分:從第二行起為請求頭部,緊接著請求行(即第一行)之后,用來說明服務器要使用的附加資訊 HOST將指出請求的目的地. User-Agent,服務器端和客戶端腳本都能訪問它,它是瀏覽器型別檢測邏輯的重要基礎.該資訊由你的瀏覽器來定義,并且在每個請求中自動發送等等 #第三部分:空行,請求頭部后面的空行是必須的 即使第四部分的請求資料為空,也必須有空行, #第四部分:請求資料也叫主體,可以添加任意的其他資料, 這個例子的請求資料為空,只有POST方法才有請求體,可以用瀏覽器登錄一個網站,輸錯賬號密碼來抓取POST請求 POST / HTTP1.1 Host:www.wrox.com User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022) Content-Type:application/x-www-form-urlencoded Content-Length:40 Connection: Keep-Alive name=Professional%20Ajax&publisher=WileyRequest請求詳解
3、HTTP請求方法
#1、Http協議定義了很多與服務器互動的方法(了解) HTTP1.0定義了三種請求方法: GET, POST 和 HEAD方法, HTTP1.1新增了五種請求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法, #2、了解下各個方法的大致意義 GET 請求指定的頁面資訊,并回傳物體主體, HEAD 類似于get請求,只不過回傳的回應中沒有具體的內容,用于獲取報頭 POST 向指定資源提交資料進行處理請求(例如提交表單或者上傳檔案),資料被包含在請求體中,POST請求可能會導致新的資源的建立和/或已有資源的修改, PUT 從客戶端向服務器傳送的資料取代指定的檔案的內容, DELETE 請求服務器洗掉指定的頁面, CONNECT HTTP/1.1協議中預留給能夠將連接改為管道方式的代理服務器, OPTIONS 允許客戶端查看服務器的性能, TRACE 回顯服務器收到的請求,主要用于測驗或診斷, #3、一個URL地址用于描述一個網路上的資源,而HTTP中最基本的四個方法GET, POST, PUT, DELETE就對應著對這個資源的查,改,增,刪4個操作, #4、 我們最常見的就是GET和POST了,GET一般用于獲取/查詢資源資訊,而POST一般用于更新資源資訊.HTTP請求方法(了解)
GET與POST的區別:
#1、區別1: 引數的組織方式不同 GET提交的資料會放在URL之后,以?分割URL和傳輸資料,引數之間以&相連, 例 如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD,如果資料是英文字母/數字,原樣發送,如果是空格,轉換為+,如果是中文/其他字符,則直接把字串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX為該符號以16進制表示的ASCII, POST方法是把提交的資料放在HTTP包的Body中. 因此,GET提交的資料會在地址欄中顯示出來,而POST提交,地址欄不會改變 #2、區別2:傳輸資料大小限制 首先宣告:HTTP協議沒有對傳輸的資料大小進行限制,HTTP協議規范也沒有對URL長度進行限制, 而在實際開發中存在的限制主要有: GET:特定瀏覽器和服務器對URL長度有限制,例如 IE對URL長度的限制是2083位元組(2K+35),對于其他瀏覽器,如Netscape、FireFox等,理論上沒有長度限制,其限制取決于操作系 統的支持, 因此對于GET提交時,傳輸資料就會受到URL長度的 限制, POST:由于不是通過URL傳值,理論上資料不受 限,但實際各個WEB服務器會規定對post提交資料大小進行限制,Apache、IIS6都有各自的配置, 可以簡單總結為: GET提交的資料大小有限制(因為瀏覽器對URL的長度有限制),而POST方法提交的資料沒有限制. GET方式需要使用Request.QueryString來取得變數的值,而POST方式通過Request.Form來獲取變數的值, #3、區別3:安全性 POST的安全性要比GET的安全性高,比如:通過GET提交資料,用戶名和密碼將明文出現在URL上,因為(1)登錄頁面有可能被瀏覽器快取;(2)其他人查看瀏覽器的歷史紀錄,那么別人就可以拿到你的賬號和密碼了,除此之外,使用GET提交資料還可能會造成Cross-site request forgery攻擊
五、HTTP協議之回應Response
服務器接收并處理客戶端發過來的請求后會回傳一個HTTP的回應訊息Response
HTTP回應也由四個部分組成,分別是:狀態行、訊息報頭、空行和回應正文,
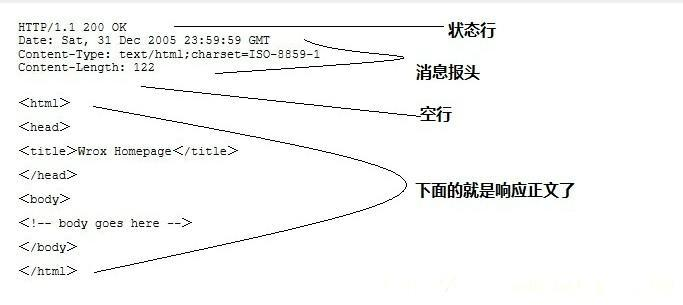
#第一部分:狀態行,由HTTP協議版本號, 狀態碼, 狀態訊息 三部分組成, 第一行為狀態行,(HTTP/1.1)表明HTTP版本為1.1版本,狀態碼為200,狀態訊息為(ok) #第二部分:訊息報頭,用來說明客戶端要使用的一些附加資訊, Date:生成回應的日期和時間; Content-Type:指定了MIME型別的HTML(text/html),編碼型別是UTF-8 #第三部分:空行,訊息報頭后面的空行是必須的 #第四部分:回應正文,服務器回傳給客戶端的文本資訊, 空行后面的html部分為回應正文,
狀態碼(略)
六、HTTP協議完整作業流程
HTTP協議定義Web客戶端如何從Web服務器請求Web頁面,以及服務器如何把Web頁面傳送給客戶端,HTTP協議采用了請求/回應模型,客戶端向服務器發送一個請求報文,請求報文包含請求的方法、URL、協議版本、請求頭部和請求資料,服務器以一個狀態行作為回應,回應的內容包括協議的版本、成功或者錯誤代碼、服務器資訊、回應頭部和回應資料,
以下是 HTTP 請求/回應的步驟:
1、客戶端連接到Web服務器 一個HTTP客戶端,通常是瀏覽器,與Web服務器的HTTP埠(默認為80)建立一個TCP套接字連接,例如,http://www.oakcms.cn, 2、發送HTTP請求 通過TCP套接字,客戶端向Web服務器發送一個文本的請求報文,一個請求報文由請求行、請求頭部、空行和請求資料4部分組成, 3、服務器接受請求并回傳HTTP回應 Web服務器決議請求,定位請求資源,服務器將資源復本寫到TCP套接字,由客戶端讀取,一個回應由狀態行、回應頭部、空行和回應資料4部分組成, 4、釋放連接TCP連接 若connection 模式為close,則服務器主動關閉TCP連接,客戶端被動關閉連接,釋放TCP連接;若connection 模式為keepalive,則該連接會保持一段時間,在該時間內可以繼續接收請求; 5、客戶端瀏覽器決議HTML內容 客戶端瀏覽器首先決議狀態行,查看表明請求是否成功的狀態代碼,然后決議每一個回應頭,回應頭告知以下為若干位元組的HTML檔案和檔案的字符集,客戶端瀏覽器讀取回應資料HTML,根據HTML的語法對其進行格式化,并在瀏覽器視窗中顯示, 例如:在瀏覽器地址欄鍵入URL,按下回車之后會經歷以下流程: 1、瀏覽器向 DNS 服務器請求決議該 URL 中的域名所對應的 IP 地址; 2、決議出 IP 地址后,根據該 IP 地址和默認埠 80,和服務器建立TCP連接; 3、瀏覽器發出讀取檔案(URL 中域名后面部分對應的檔案)的HTTP 請求,該請求報文作為 TCP 三次握手的第三個報文的資料發送給服務器; 4、服務器對瀏覽器請求作出回應,并把對應的 html 文本發送給瀏覽器; 5、釋放 TCP連接; 6、瀏覽器將該 html 文本并顯示內容;
七、HTTP協議關鍵性總結
#1、簡單快速 客戶向服務器請求服務時,只需傳送請求方法和路徑,請求方法常用的有GET、HEAD、POST,每種方法規定了客戶與服務器聯系的型別不同,由于HTTP協議簡單,使得HTTP服務器的程式規模小,因而通信速度很快, #2、靈活 HTTP允許傳輸任意型別的資料物件,正在傳輸的型別由Content-Type加以標記, #3、無連接 HTTP無連接說的是:當某個客戶機在短時間多次次請求同一個資源,服務器并不能區別是否已經回應過用戶的請求, 于是我們每次發送http請求,都需要事先發起一個到服務器的TCP請求,經歷“三次握手”的程序,這針對大流量的的服務器來說,開銷是相當大的,這是http無鏈接帶來的缺點 針對http無連接,人們設計了非持久連接和持久連接,實際上關于http協議非持久連接和持久連接是針對tcp協議的,當客戶機/服務器的互動運行于TCP協議上時,應用程式的每個請求/回應對是經不同的TCP連接時,則該應用程式使用非持久連接,而當應用程式的每個請求/回應對是經相同的TCP連接發送,則該應用程式使用持久連接, 非持久連接 請求一個HTTP請求/回應需要的總時間=客戶端發出建立連接+發生請求報文+服務器傳輸HTML檔案的時間 持久連接 服務器在發送回應后,保持該TCP連接打開,在相同的客戶機與服務器之間的后續請求和回應報文通過相同的連接進行傳送,不需要再次建立tcp連接 #4、無狀態 所謂http是無狀態協議,言外之意是說http協議沒法保存客戶機資訊, 無狀態的優點是: 在服務器不需要先前資訊時它的應答就較快, 無狀態的缺點是: 缺少狀態意味著如果后續處理需要前面的資訊,則它必須重傳,這樣可能導致每次連接傳送的資料量增大 關于http無狀態阻礙了互動式應用程式的實作,比如記錄用戶瀏覽哪些網頁、判斷用戶是否擁有權限訪問等,于是,兩種用于保持HTTP狀態的技術就應運而生了,一個是Cookie,而另一個則是Session, #5、支持B/S及C/S模式,
八、自定義套接字分析HTTP協議
<h1>hello</h1> <p style="color:red;">你好呀</p>a.html
自定義服務端:
#服務端
import socket s = socket.socket() s.bind(('127.0.0.1', 8090)) s.listen(5) while True: conn, addr = s.accept() print('===============>',addr) data = conn.recv(1024) print(data.decode('utf-8')) conn.send("HTTP/1.1 200 OK\r\nContent-Type: text/html;charset=utf-8\r\n\r\n".encode('utf-8')) with open('a.html', mode='rb') as f: for line in f: conn.send(line) """ HTTP/1.1 200 OK k1:v1 k2:v2 k3:v3 hello """ conn.close() s.close()
瀏覽器相當于客戶端 ,可以直接在瀏覽器上輸入ip+埠號,也可以自己寫個瀏覽器客戶端
ps:每個瀏覽器決議不同,輸入格式要求不同,需要按照所用瀏覽器要求格式
#客戶端
import socket client=socket.socket() client.connect(('127.0.0.1',8080)) client.send("hello".encode('utf-8')) data=client.recv(1024) print(data.decode('utf-8')) client.close()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/8400.html
標籤:Html/Css