LawsonAbs的閱讀與思考,還請各位讀者批判閱讀,
總結
- 分成三部分,part1先談背景知識,part2談論文內容,part3再談個人思考
- 一句話總結本文:將KG知識結合到詞義消歧(WSD)的任務中,從而可以讓單詞離散的釋義標注資訊更改成連續的embedding表示;同時使用監督學習的方法訓練模型,從而得到更好的泛化效果
- 原文出處:csdn+lawsonabs
在談這篇文章之前,為了更好的理解文章內容,先說幾個簡單但重要的概念,
1 詞義消歧
這一部分可以參考我的博客
2 知識圖譜
A Knowledge Graph is typically comprised of a set K of N triples (h; l; t), where head h and tail t are entities, and l denotes a relation.
簡單的說:知識圖譜是一個由物體+關系集,那么怎么將知識圖譜中的資訊表示出來呢?
傳統的知識圖譜表示方法是采用OWL、RDF等本體語言進行描述;隨著深度學習的發展與應用,我們期望采用一種更為簡單的方式表示,那就是【向量】,采用向量形式可以方便我們進行之后的各種作業,比如:推理,所以,我們現在的目標就是把每條簡單的三元組< subject, relation, object > 編碼為一個低維分布式向量,(什么是分布式向量?)
3 表示學習
表示學習: 表示學習旨在將研究物件的語意資訊表示為稠密低維實值向量,知識表示學習主要是面向知識圖譜中的物體和關系進行表示學習,使用建模方法將物體和關系表示在低維稠密向量空間中,然后進行計算和推理,簡單來說,就是將三元組表示成向量的這個程序就稱為表示學習,【TransE模型】就是【Trans系列】中的一個經典方法,
4 MFS
這是WSD 任務中一個常用的演算法名,其全稱是(Most-Frequent-sense),
MFS這種策略就是用訓練集中某個word最常用的sense來作為測驗集中這些word的sense,這個演算法的好處就是簡單直接,但顯而易見演算法存在明顯的不足,
5.lexical sample / all-words task
這兩個術語是對wsd任務的一個應用范圍的描述,
5.1 lexical sample
在Adam Kilgarriff 的論文《English Lexical Sample Task Description》中,對這個任務進行了一個描述:


5.2 all-words task
指的就是對應需要消歧的單詞全部做一下消歧(聽起來別扭),通常就是處理名詞,副詞,形容詞,動詞,
概括兩個任務,主要有兩個小點:
- 這兩個概念應該都是來自于semeval
- 二者應該只是在消歧詞語的資料范圍上有差別
6 discrete label
0 摘要
首先需要明白WSD的任務,上面已經敘述過,不再贅述,
為什么提出EWISE方法? 因為當前的WSD演算法都是基于 discrete label,為了提高效率,所以引出了這個基于word sense embdding 的演算法,從而解決只在測驗集中出現的sense無法被準確預測的難題,
1 介紹
1.1 wsd
不再介紹~
1.2 傳統方法
-
傳統的監督演算法

discrete label是針對wsd任務中的傳統監督、半監督演算法而言的,我查閱相關資料,得出的結論是:discrete label指的就是one-hot向量, -
半監督演算法

但無論是之前的哪種演算法,只要是使用了discrete label,那么就存在問題(This leads to poor performance on rare and unseen senses.),為了解決這個問題,從而引入了當前的這個EWISE方法,該方法的創新點是:使用word sense definition 的embedding 作為target,從而達到一個比較好的泛化效果,
2.相關作業
分成監督WSD,半監督WSD,但是這些演算法都依賴于 釋義標注 的資料,同時使用沒有標注的語料庫,
2.1 Lexical resources
lexical resource 為words以及它們的含義提供重要的支持,所以 EWISE 就是利用了字典定義去捕獲單詞的含義,但是這并非字典釋義第一次用于WSD任務上,早在Lesk演算法,字典定義就已經被使用在WSD上了,那么EWISE 和這些方法有什么區別呢?主要有兩點:
EWISE使用定義的embedding 作為target embedding,這是一個監督學習訓練程序,- 不依賴于任何重疊假設(指:某個單詞的釋義與其背景關系有很大的重疊),而是僅靠WordNet 提供的單個釋義
當然也有其它的一些方法用于獲取這個 continuous representations for definition,文中會評判這些方法(包括像elmo,bert等)的效果
2.2 Structural Knowledge
我不清楚這是指什么樣的知識,
文中先說有數種方法使用 structural knowledge 來做WSD,基于圖的技術被用于匹配word 成最相關的sense,但是EWISE 與其不同的點是:
- use structural knowledge to learn better representations of definitions
2.3 主要貢獻
- predicting in an embedding space(key claim)
- allowing generalized zero shot learning capability【因為沒有再使用標注的資料了,而是直接是用wordnet中的釋義資訊】
- incorporating definitions and structural knowledge
3.演算法
3.1 主要框架
每篇論文中最主要的就是演算法框架了,那么我們來看看這個框架,
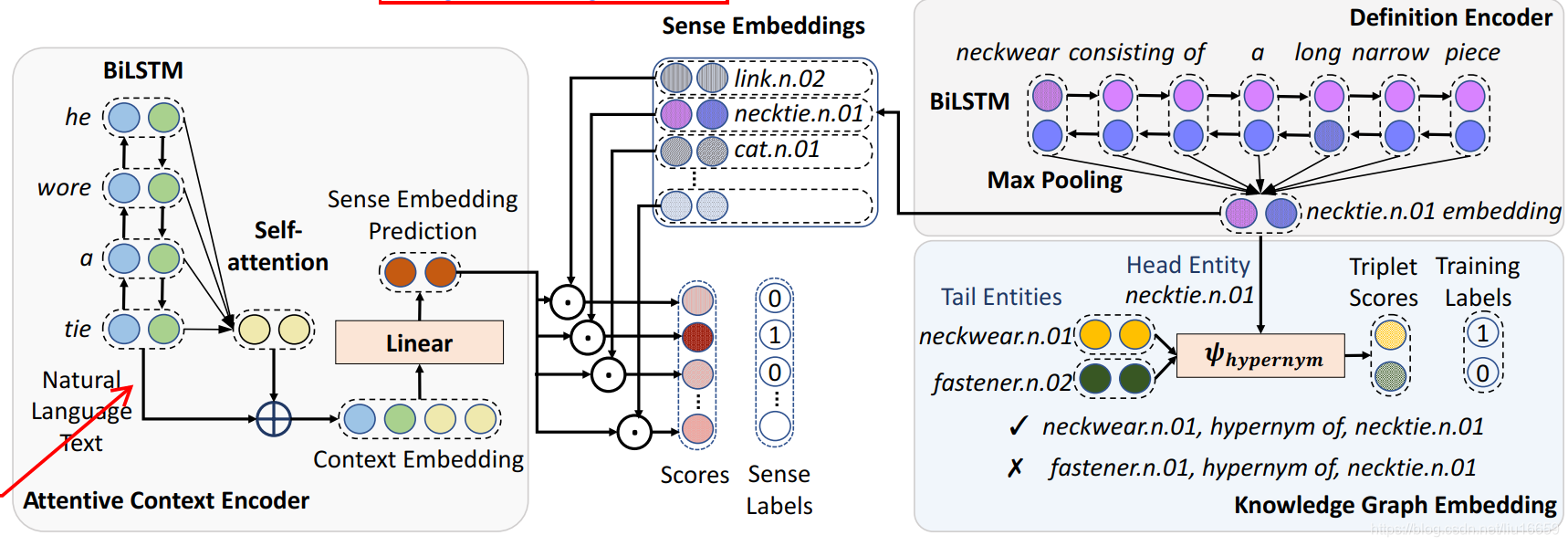
這個框架主要分成兩部分:
- Attentive Context Encoder
- Definition Encoder
3.2 Attentive Context Encoder
也就是獲取某個單詞帶有背景關系的表示(也就是融合了背景關系的資訊),用的是 BiLSTM + self-Attention 方法,
3.3 Definition Encoder
獲取某個word sense definition 的embedding表示,作為一個target embedding,
3.4 訓練
3.4.1 KG部分啥作用?
根據上述的輸入資料,就可以開始訓練整個模型,那么問題來了:Knowledge Graph Embedding 這個部分是干什么的?我們在得到target embedding 的時候,不一定能夠得到自己滿意的embedding,所以需要結合KG來獲取這個embedding,這個KG 也就是WordNet,具體的互動細節是什么?下面慢慢說,
TransE 和 ConvE 方法,可以借鑒博文學習,簡要說一下這些演算法那就是:二者都是在三元組<h,l,t>上定義了一個打分函式,用于表示h和l的某種操作到t的距離,然后二者使用不同的距離函式和損失函式,在訓練的程序中來減小損失,從而達到一個比較好的效果,從而能夠將一個知識圖譜降維表示成帶有強關系的向量,
3.4.2 訓練步驟
整個訓練程序可以用下面的一段話來描述:
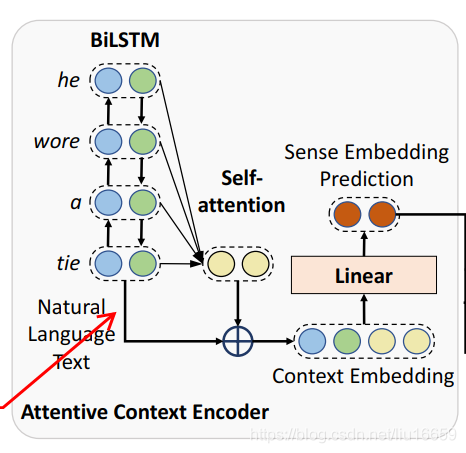
- 有一句文本,使用BiLSTM 得到需要消歧詞(假設這個詞是A)的embedding表示
- 把這個embedding做一系列的處理(依次是:同其他詞做self-attention => 拼接 => 線性投影),然后就得到了最終的一個向量
u
i
u^i
ui,也就是圖中的
sense embedding prediction,我們記其為x,
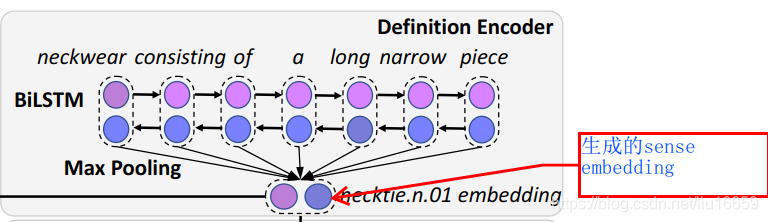
- 通過wordNet 獲取某個單詞的sense inventory,通過訓練好的Definition Encoder 將這些sense 分別轉換成sense embedding,這個sense embedding就是文中說到的target embedding,也就是模型中資料的“標簽”,記其為y
- 將x和y做一個點乘操作,對結果取softmax操作,然后使用交叉熵損失函式計算損失,從而迭代更新引數
4.資料&實驗
這部分沒啥好說的,主要是圍繞EWISE的 key claim — the abilitiy of disambiguate unseen and rare words來設計實驗,
- WSD on Rare Words【如果測驗集中出現的單詞沒有在訓練集中出現該怎么處理?】
- WSD on Rare Senses【如果測驗集中出現的單詞的含義沒有在訓練集中出現該怎么處理?】
因為本演算法的特性,所以可以直接處理上述兩種情況而不用使用其他演算法(如MFS)來處理特殊情況,
5.個人思考
- 資料越多,訓練效果越好,這句話仿佛就是黃金準則,但是資料并不一定要完全靠標注而來,能否依靠其它的資源呢?比如:詞典,陳述句自身的結構資訊?
可以看到有很多作業都是在充分利用這些資訊從而達到一個較好的效果,
7.參考資料
- https://blog.csdn.net/weixin_40871455/article/details/83341561 【用于介紹TransE演算法,不錯的入門資料】
- https://www.aclweb.org/anthology/P19-1568/ 【論文地址】
- https://www.aclweb.org/anthology/S01-1004.pdf 【lexical sample task的介紹】
- https://zhuanlan.zhihu.com/p/54657158 【介紹lexical sample task 和 wordNet中常見的一些概念】
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/224339.html
標籤:區塊鏈
上一篇:BSV上的一種可替換token的新方案:Oracle方案
下一篇:海戰游戲環境配置