摘要
BERT不能處理長文本,因為它的記憶體和時間消耗呈二次增長,解決這個問題的最自然的方法,如用滑動視窗對文本進行切片,或者簡化transformer,使用不充分的長范圍attention,或者需要定制的CUDA內核,,BERT的最大長度限制提醒我們人類作業記憶的容量是有限的(5個~9個區塊),那么人類是如何認知長文本的呢?本文提出的CogLTX 框架基于Baddeley提出的認知理論,通過訓練一個判斷模型來識別關鍵句子,并將其串接進行推理,并通過排練和衰減實作多步驟推理,由于相關性注釋通常是不可用的,我們建議使用干預來創建監督,作為一種通用演算法,CogLTX在不依賴于文本長度的記憶體開銷情況下,在各種下游任務上優于或獲得與SOTA模型相當的結果,
介紹
由BERT開創的Pretrained語言模型已經成為處理許多NLP任務(例如機器閱讀理解-問答和文本分類)的靈丹妙藥,研究人員和工程師可以輕松地按照標準精細化范式構建最先進的應用程式,但最終可能會失望地發現一些文本的長度超過BERT的限制(通常是512個符號),這種情況在標準化基準測驗中可能很少見,例如SQuAD【38】和GLUE【47】,但在更復雜的任務[53]或真實的文本資料中很常見,對于長文本,一個簡單的解決方案是滑動視窗【50】,BERT處理連續的512個標記跨度,這種方法犧牲相距過遠字符“相互映射(pay attention)”,這成為BERT在復雜任務(例如圖1)顯示其功效的瓶頸,因為問題的根源在高時間O (L2)和空間復雜性在transformers[46](L是文本的長度),另一條線的研究試圖簡化的結構transformers【20,37,8,42】,但目前他們已經成功地應用于BERT【35,4】,

BERT的最大長度限制很自然地提醒了我們有限容量的作業記憶[2]:一種人類的認知系統,用來存盤邏輯推理和決策的資訊,實驗【27,9,31】已經表明,在閱讀程序中,作業記憶僅能容納5個~ 9個條目/單詞,那么人類到底是怎么理解較長的文本的呢?正如Baddeley【2】在其1992年的經典著作中指出的那樣,“中央執行器——(作業記憶)系統的核心,負責協調(多模式)資訊”,然后,“功能類似于一個有限容量的注意力系統,能夠選擇和操作控制程序和策略”,后來的研究詳細說明了作業記憶中的內容會隨著時間的推移而衰減,除非是通過排演【3】來保存,即注意并重繪頭腦中的資訊,然后通過檢索比較【52】,用長期記憶中的相關條目不斷更新被忽略的資訊,在作業記憶中收集足夠的資訊進行推理,BERT和作業記憶之間的類比啟發我們用CogLTX框架像人類一樣認知長文本,CogLTX背后的基本哲學是相當簡潔的——對關鍵句子的串聯進行推理(圖2)——而緊湊的設計則需要在機器和人的推理程序之間架起橋梁,
CogLTX的關鍵步驟是MemRecall,即通過將文本塊視為情景記憶來識別相關文本塊的程序, MemRecall模擬了作業記憶的檢索競賽、預演和衰退,便于多步驟推理,另一個BERT,稱為judge,被引入來評分塊的相關性,并與最初的BERT reasoner一起訓練,此外,CogLTX還可以通過干預將面向任務的標簽轉換為相關性注釋,以訓練判斷人員,我們的實驗表明,CogLTX在包括NewsQA[44]、HotpotQA[53]、20個NewsGroups[22]和Alibaba在內的四個任務上優于或達到了相當的性能,無論文本長度如何,記憶體消耗都是恒定的,
背景
長文本的挑戰,長文本的挑戰,對長文本的直接和表面障礙是在BERT[12]中預先訓練的最大位置嵌入通常為512,然而,即使提供了更大位置的嵌入,記憶體消耗也是難以承受的,因為所有的激活都存盤在訓練期間的反向傳播,例如,一個1500-token文本需要大約14.6GB的記憶體才能運行bert -即使批量大小為1,也很大,超過了普通gpu的容量(例如,1個token文本),11GB的RTX 2080ti),此外,O(L2)空間復雜度意味著隨著文本長度L的增加而快速增加,
相關的作業,如圖1所示,滑動視窗法缺乏遠距離關注,以前的作業[49,33]試圖通過均值池、max-池或額外的MLP或LSTM來聚合每個視窗的結果;但這些方法在長距離互動時仍然很弱,需要O(5122·L/512) = O(512L)空間,這在實踐中仍然太大,無法在批量大小為1的RTX 2080ti上訓練2500令牌文本的BERT-large,此外,這些晚聚合方法主要是對分類進行優化,而其他任務,如廣度提取,輸出L BERT值,需要O(L2)空間進行自注意聚合,
在對transformer進行長文本改造的研究中,很多只是壓碩訓重復使用了之前步驟的結果,無法應用到BERT中,如Transformer- xl[8]、compression Transformer[37],Reformer使用位置敏感的散列來實作基于內容的群組關注,但它對GPU不友好,仍然需要對BERT的使用進行驗證,BlockBERT[35]砍掉不重要的注意力頭,將BERT從512令牌提升到1024,最近的里程碑長前[4],定制CUDA內核,以支持視窗注意和全域注意的特殊令牌,然而,由于資料集大多在longformer視窗大小的4倍范圍內,對后者的有效性的研究還不夠充分,“輕量級BERTs”的方向很有前途,但與CogLTX是正交的,這意味著它們可以結合CogLTX來處理較長的文本,因此本文將不再對它們進行比較或討論,詳細的調查可以在[25]中找到,

方法
CogLTX方法:
CogLTX的這個基本假設是“對于大多數NLP任務來說,文本中的幾個關鍵句子存盤了足夠和必要的資訊來完成任務”,更具體地說,我們假設存在一個由長文本x中的一些句子組成的短文本z,滿足
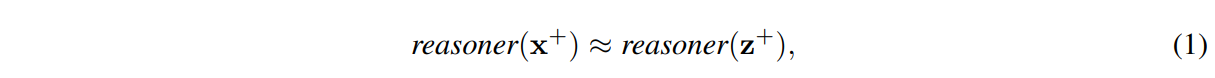
其中x+和z+是推理機BERT w.r.t的輸入,文本x和z如圖2所示,
我們通過動態編程(見附錄)將每個長文本分割成塊[x0 ... x(T-1],這將塊長度限制為最大B,在我們的實作中,如果BERT長度限制為L = 512,則B = 63,關鍵短文本z應該由x中的若干塊組成,即z = [xz0…xznn 1],滿足len(z+)≤L且z0 <…< znn 1,我們用zi表示xzi,z中的所有塊都會自動排序,以保持x中的原始相對順序,
關鍵塊假設與潛變數模型密切相關,潛變數模型通常用EM[11]或變分貝葉斯[19]求解,但是,這些方法估計z的分布,需要多次采樣,對BERTs來說不夠有效,我們將它們的精髓融入到CogLTX的設計中,并在§3.3中討論了它們之間的聯系,
在CogLTX中,MemRecall和兩個BERTs的聯合訓練是必不可少的,如圖2所示,MemRecall是利用判斷模型檢索關鍵塊的演算法,在推理程序中將關鍵塊送入推理機完成任務,
MemRecall
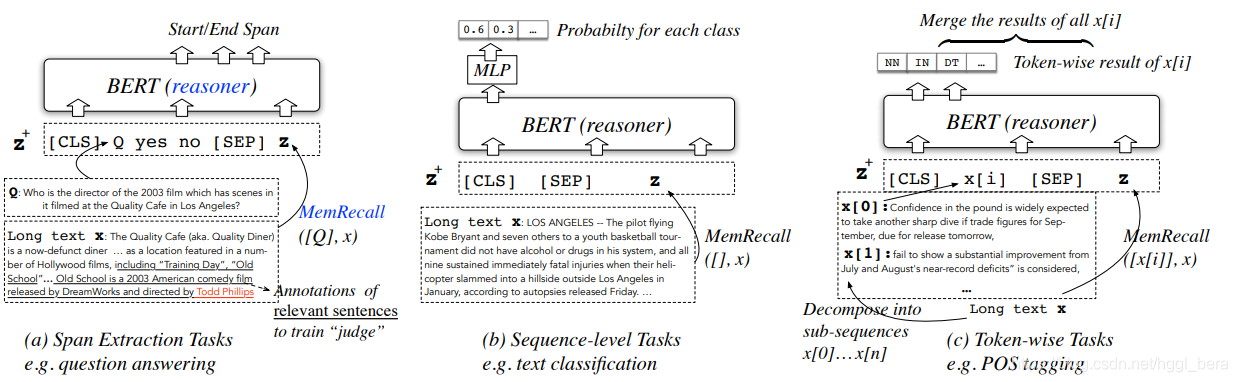
當大腦回憶與作業記憶中當前資訊相關的過去事件時,MemRecall的目的是從長文本x中提取關鍵塊z(見圖3),
輸入,盡管其目的是提取關鍵塊,但三種任務型別的具體設定有所不同,在圖2 (a) (c)中,問題Q或子序列x[i]作為查詢,用于檢索相關塊,但是,(b)中沒有查詢,相關性僅由訓練資料隱式定義,例如,包含“唐納德·特朗普”或“籃球”的句子在新聞話題分類方面比時間報道句子更相關,那么如何無縫地統一這些案例呢?
MemRecall通過接受初始的z+作為x之外的附加輸入來回答這個問題,z+是在MemRecall期間維護的簡短“關鍵文本”,用來模擬作業記憶,任務(a)(c)中的查詢成為z+中的初始資訊,以引發回憶,然后,判斷模型在z+的幫助下學習預測任務特定的相關性,
模型,MemRecall使用的唯一模型是上面提到的 judge,一個BERT來為每個標記評分相關性,假設z+ = [[CLS] Q [SEP]z0[SEP]…znn1),
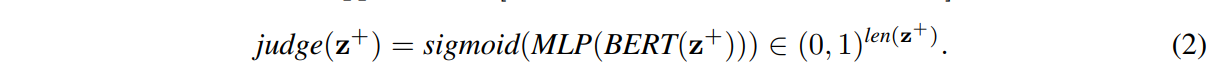
區塊zi的分數記為judge(z+)[zi],是該區塊中token分數的平均值,
程序,MemRecall始于一場檢索比賽,每個塊xi分配一個粗關聯評分judge([z+[SEP]xi])[xi],得分最高的“勝者”塊插入z, len(z+)≤l,向量空間模型[40]優于向量空間模型[40]的優勢在于xi通過變壓器與電流z+完全相互作用,避免了嵌入程序中的資訊丟失,
接下來的排演衰減期賦予每個zi一個良好的相關性評分judge(z+)[zi],只有得分最高的區塊會被保存在z+中,就像作業記憶中的排演衰減現象一樣,細分值的動機是,沒有分塊之間的互動和比較,粗分值的相對大小不夠準確,類似于重新計算[7]的動機,
MemRecall本質上支持多步驟推理,通過使用新的z+重復這個程序,CogQA[13]強調了迭代檢索的重要性,因為在多跳閱讀理解中,答案句不能被問題直接檢索,值得注意的是,如果z+中新塊的更多資訊證明它們的相關性不夠強(得分較低),上一步保留的塊也會衰減,而之前的多步推理方法忽略了這一點[13,1,10],
訓練
下流式任務的多樣性對在CogLTX訓練BERTs提出了挑戰,
演算法1總結了不同設定下的解,
Algorithm 1: The Training Algorithm of CogLTX (演算法1:CogLTX的訓練演算法)

對judge進行監督培訓,,《自然》中的跨度提取任務(圖2(a))建議使用相應的答案塊,即使是多跳資料集,例如HotpotQA[53],通常也會對支持句進行注釋,在這些情況下,judge自然是在監督下接受訓練的:
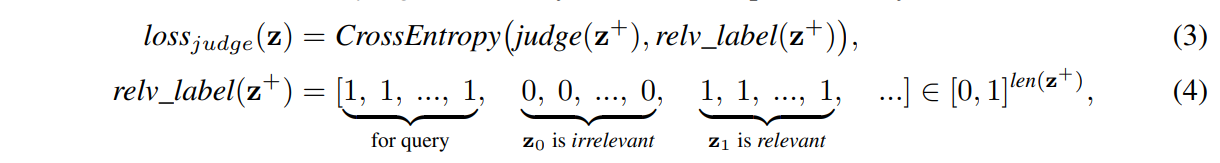
其中訓練樣本z要么是從x中采樣的連續塊Zrand序列(對應檢索比賽的資料分布),要么是所有相關和隨機選擇的不相關塊Zrelv的混合(近似于排練的資料分布),
對reasoner進行監督培訓,reasoner面臨的挑戰是如何在訓練和推理程序中保持資料分布的一致性,這是監督學習的一個基本原則,理想情況下,reasoner的輸入也應該由MemRecall在訓練期間生成,但并不能保證所有相關塊都能被檢索到,例如在回答問題時,如果MemRecall漏掉了答案塊,訓練就不能進行,最后,近似地發送檢索競賽中所有相關塊和“優勝者”塊來訓練reasoner,
對judge進行無監督培訓,不幸的是,許多任務(圖2 (b)(c))沒有提供相關性標簽,因為CogLTX假設所有相關的塊都是必要的,所以我們通過干預推斷出相關標簽:通過從z中洗掉塊來測驗塊是否是不可缺少的,
假設z是“oracle relevant blocks”,根據我們的假設,
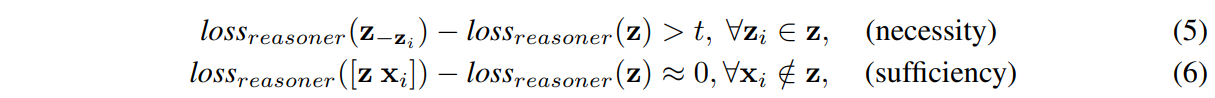
其中Z-zi是z去除了zi的結果,t是一個閾值,在訓練reassoner的每一次迭代后,我們切割z中的每個塊,根據損失的增加調整其關聯標簽,不顯著的增加表明區塊是不相關的,它可能不會再次“贏得檢索比賽”來訓練推理機在下一個時代,因為它將被貼上不相關的標簽來訓練裁判,然后真正相關的塊可能進入z下一個紀元并被檢測出來,在實踐中,我們將t分為up和down兩部分,留出緩沖區域,以防止頻繁更換標簽,我們在圖4中的20News文本分類資料集上展示了一個無監督訓練的示例,
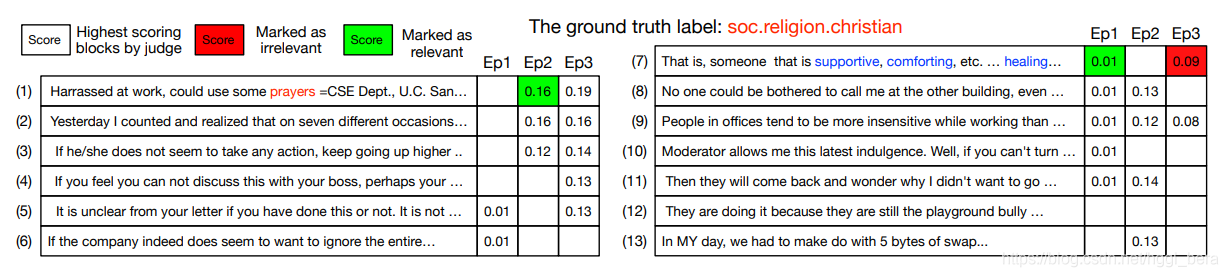
在第一階段,judge幾乎沒有經過訓練,隨機選擇一些方塊,其中,(7)對正確分類貢獻最大,標記為“relevant”,
在第二個時代,經過訓練的judge發現(1)有強有力的證據證明“prayers”和(1)立刻被標記為“relevant”,那么在下一個時代,(7)就不再是分類的必要條件,被標記為“irrelevant”,
與潛在變數模型的連接,無監督CogLTX可以看作是(條件)潛變數模型p(y|x;θ)∝p (z | x) p (y | z;θ),EM[11]推斷z的分布為后驗p(z|y, x;E-step中的θ),而變分bayes方法[19,3]使用一個估計友好的q(z|y, x),然而,在CogLTX中z是一個離散分布,其可能值高達Cnm,其中n, m分別是塊數和z的容量,在某些情況下,為了訓練BERTs,可能需要進行數百次抽樣,其昂貴的時間消耗迫使我們轉向z的點估計2,例如,我們基于干涉的方法,
干預解決方案維護每個x的z估計,本質上是一個特定于CogLTX的本地搜索,z是通過比較附近的值(替換不相關塊后的結果)而不是Bayesian規則來優化的,Judge采用歸納判別模型來幫助推斷出z,
實驗
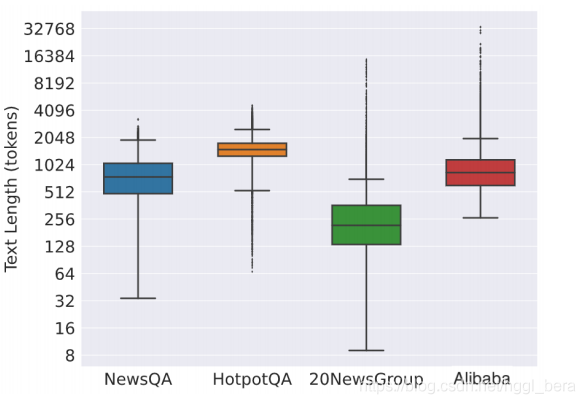
我們在四個不同任務的長文本資料集上進行了實驗,token-wise(圖2 (c))任務不包括從相鄰的句子,因為他們大多僅僅需要資訊并最終轉化為多個sequence-level山姆 pl,圖5中的箱線圖顯示了資料集中文本長度的統計資訊,
在所有實驗中,judge和reasoner由Adam[18]優化,學習速率分別為4×1005和1004,在前10%的步驟中,學習率開始升溫,然后線性衰減到最大學習率的1/10,常用的超引數為batch size = 32, strides= [3, 5], tup = 0.2,當count =0.05,
在本節中,我們將分別介紹每一項任務以及相關的結果、分析和消融研究,
閱讀理解
資料集和設定,給定一個問題和一段話,任務是預測在這段話中的回答跨度,我們評估了CogLTX在NewsQA[44]上的性能,NewsQA[44]包含119,633個人工生成的問題,在12,744篇長新聞文章中提出,3由于之前的SOTA[43]在NewsQA中不是基于BERT的(由于文本較長),為了保持相同的引數規模進行公平比較,我們在CogLTX中對RoBERTa[26]的基礎版本進行了4個時期的調整,
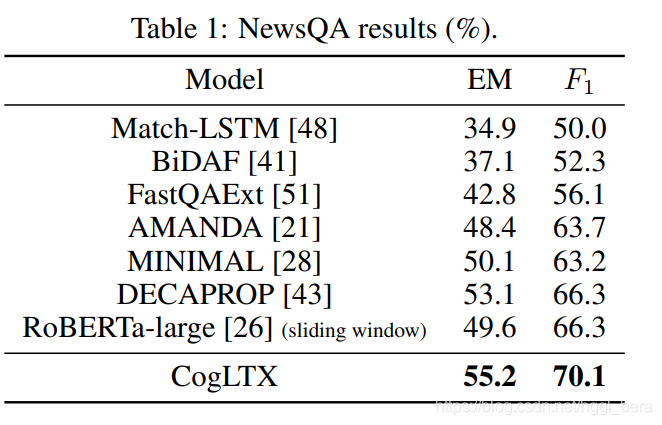
結果,表1顯示,CogLTX-base優于已經建立的QA模型,例如BiDAF [41] (+17.8% F1),先前的SOTA DECAPROP[43](包含精心的自我注意和RNN機制(+4.8%F1),甚至是帶滑動視窗的RoBERTa-large (+4.8%F1),我們假設第一句話(導語)和最后一句話(結論)通常是新聞文章中資訊量最大的部分,CogLTX可以聚合它們進行推理,而滑動視窗不能,
Multi-hop question answering
資料集和設定,在復雜的情況下,答案是基于多個段落,以前的方法通常利用段落中關鍵物體之間的圖結構[13,36],然而,如果我們可以使用CogLTX處理較長的文本,那么通過將所有段落作為BERTs的輸入連接起來,就可以很好地解決這個問題,
HotpotQA[53]是一個包含112,779個問題的多跳QA資料集,其distractor設定為每個問題提供了2個必要的段落和8個distractor段落,答案和支持性事實都是評估所需要的,在CogLTX中,我們將每個句子視為一個塊,并直接輸出分數最高的2個塊作為支持事實,
結果,表2顯示,CogLTX優于之前的大多數方法和排行榜上的所有7個BERT變體解決方案,
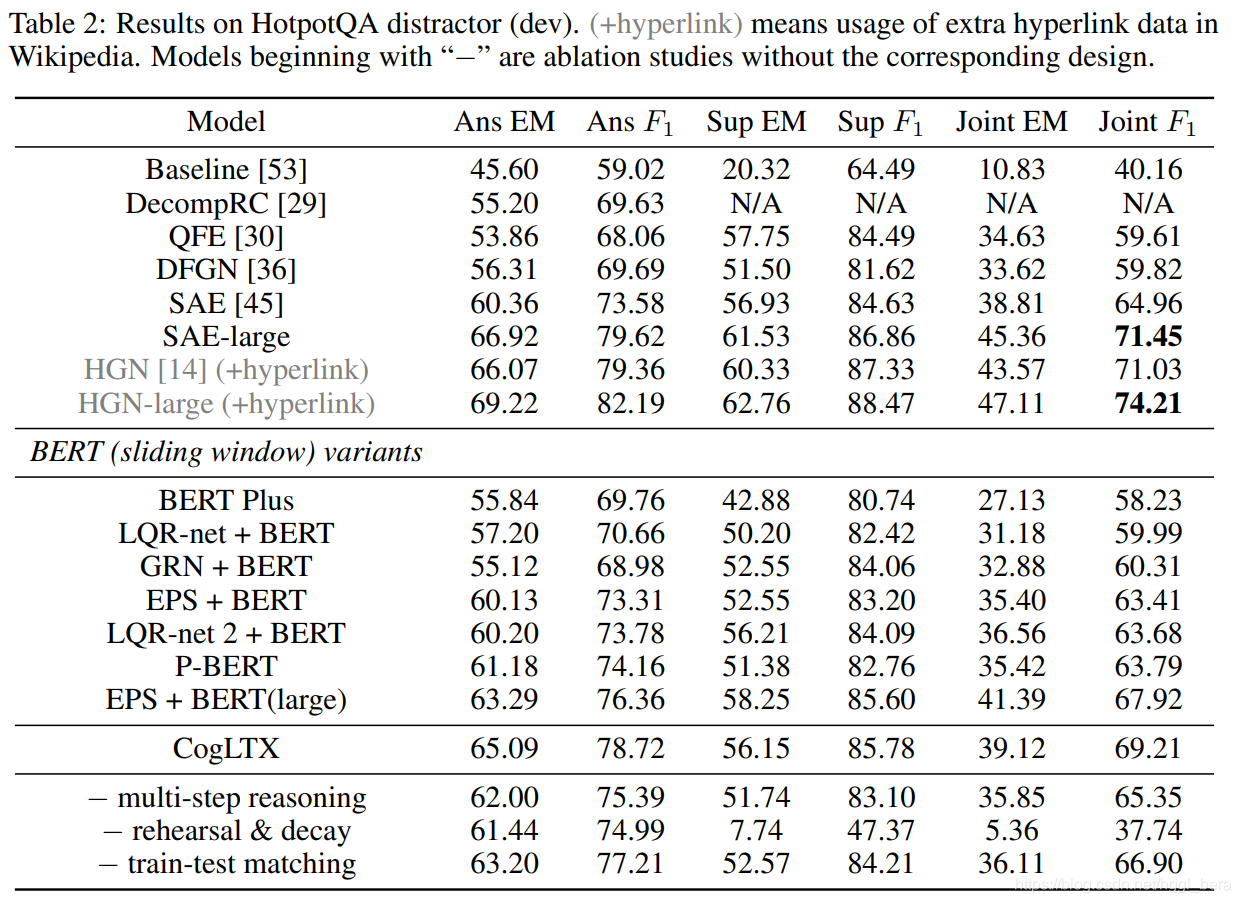
SOTA模型HGN[14]利用了維基百科中額外的超鏈接資料,資料集是基于這些超鏈接資料構建的,SAE[45]的思想與CogLTX類似,但不太通用,它通過BERTs的注意層對段落進行評分,選擇得分最高的兩段,并將它們一起提供給BERT,支持事實是由另一個復雜的圖表注意模型決定的,由于定向設計良好,SAE比CogLTX(2.2%聯合F1)更適合HotpotQA,但不能解決較長段落的記憶體問題,CogLTX像普通QA一樣直接解決多跳QA問題,得到sota可比的結果,無需額外努力就能解釋支持事實,
Ablation的研究,我們還總結了表2中的消融研究,表明
(1)多步推理確實有效(+3.9%關節F1),但不是必要的,可能是因為HotpotQA中的許多問題本身與第二跳句子足夠相關,可以檢索它們,
(2)在未進行預演的情況下,支持事實的指標顯著下降(-35.7% Sup F1),這是因為最高句之間的相關性得分不具有可比性,
(3)如§3.3所述,如果推理機采用隨機選擇的塊進行訓練,則訓練和測驗程序中資料分布的差異會影響性能(-2.3%聯合F1),
文本分類
資料集和設定,文本分類是自然語言處理中最常見的任務之一,它對主題、情感、意圖等進行分析是必不可少的,我們在經典的20個新聞組[22]上進行實驗,該新聞組包含來自20個類的18,846個檔案,我們給羅伯塔安排了6個時代的CogLTX,
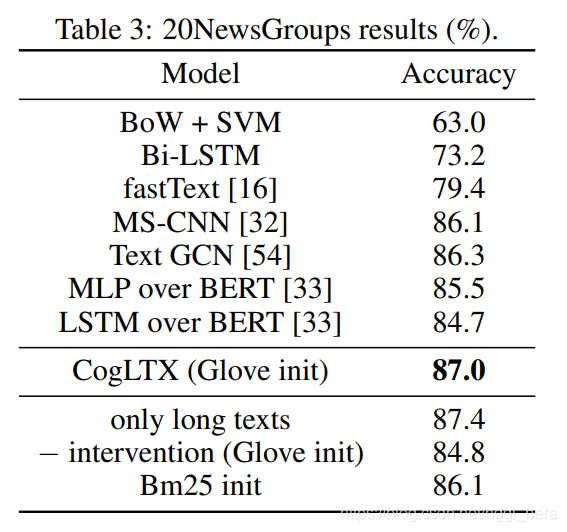
結果,表3表明,CogLTX的相關性標簽是由Glove[34]初始化的,它的性能優于其他基線,包括先前嘗試從滑動視窗[33]聚合[CLS]池結果的結果,此外,基于MLP或LSTM的聚合既不能對長文本進行端到端訓練,
Ablation的研究,
(1)由于20個新聞組中的文本長度差異很大(見圖5),我們只在大于512的文本上進一步測驗性能
(2)基于Glove的初始化雖然提供了較好的相關性標簽,但由于沒有進行干預調整,仍然導致準確率下降了2.2%,
(3) Bm25初始化基于常用語,由于標簽名較短,只初始化了14.2%的訓練樣本,如sports.baseball,通過干預和逐步訓練推理器推斷相關句子,準確率達到86.1%,
Multi-label classifification
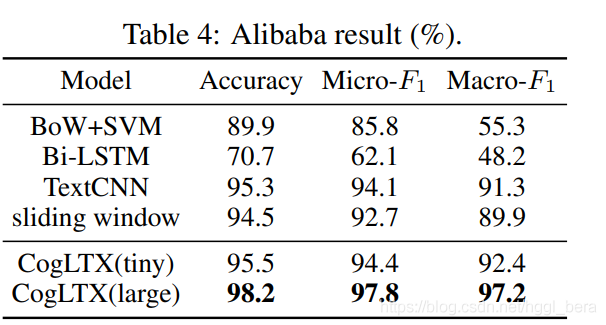
資料集和設定,在許多實際問題中,每個文本可以同時屬于多個類別,多標簽分類通常通過為每個標簽訓練一個單獨的分類器來轉化為二分類,由于BERT容量大,我們共享所有標簽的模型,方法是在檔案開頭添加標簽名作為輸入,即[[CLS] label [SEP] doc],用于二進制分類,阿里巴巴是從一個大型電子商務平臺的行業場景中提取的3萬篇文章的資料集,每篇文章都有67個類別的幾個專案的廣告,上述類別的檢測被完美地建模為多標簽分類,為了加快實驗速度,我們分別抽樣8萬對和2萬對標簽-條目對進行訓練和測驗,為了完成這個任務,我們在CogLTX找到了RoBERTa,
結果,表4顯示了CogLTX優于普通的強基線,TextCNN[17]和Bi-LSTM使用的單詞embeddings來自RoBERTa,為了公平比較,即使CogLTX-tiny (7.5M引數)也優于TextCNN,但是,RoBERTa-large滑動視窗的max-pooling結果卻不如CogLTX (7.3% Macro-F1),我們假設這是由于在max-pooling中傾向于給非常長的文本分配更高的概率,突出了CogLTX的效力,
記憶體和時間消耗
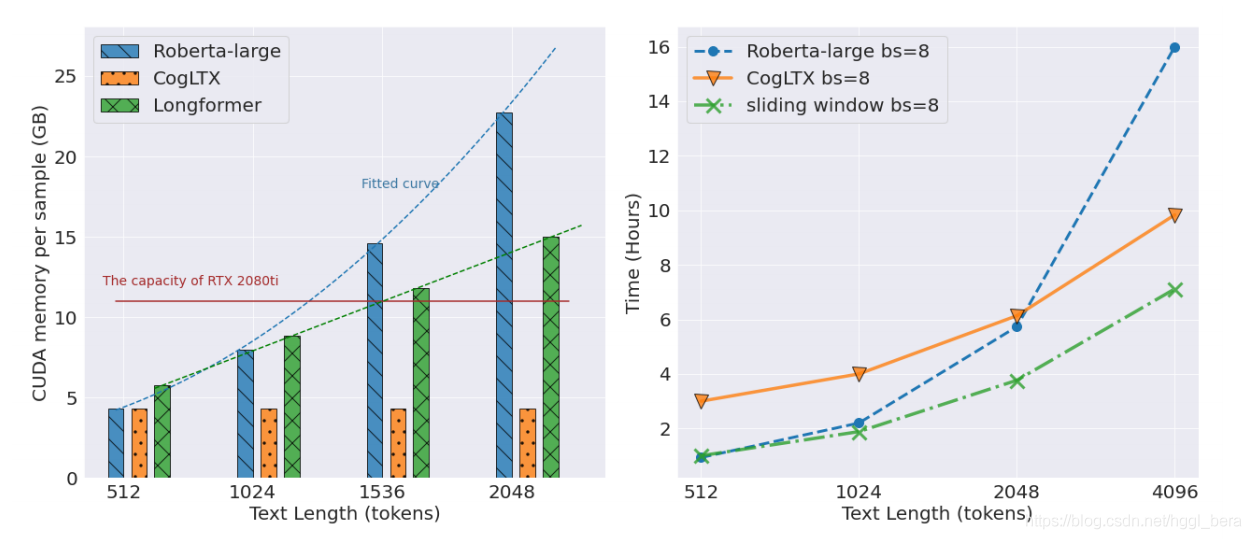
記憶體,CogLTX的記憶體消耗在訓練期間是恒定的,優于香草BERT的O(L2)復雜性,我們還比較了longformer[4],如果全域注意令牌的數量相對于L較小且不依賴于L,則其空間復雜度大致為O(L),圖6(左)總結了詳細的比較,
時間,為了加快推理機的訓練,我們可以在訓練判斷時快取分塊的分數,這樣每個epoch只需要2倍的單bert訓練時間,由于CogLTX和滑動視窗在訓練中直到收斂的epochs數目相似,CogLTX主要關注推理的速度,圖6(右)顯示了處理10萬例不同文本長度的合成資料集的時間,CogLTX的時間復雜度為O(n),在L > 2048之后比香草BERT快,并隨著文本長度L的增長接近滑動視窗的速度,
結論與討論
我們提出了CogLTX,一種將BERT應用于長篇文本的認知啟發框架,在訓練中,CogLTX只需要固定的記憶,可以在遙遠的句子之間進行關注,類似的想法也在DrQA[6]和ORQA[23]的檔案級進行了研究,之前也有以非監督方式提取重要句子的作業,如基于結構[24]的元資料,在4個不同的大資料集上的實驗表明了該演算法的有效性,CogLTX有望成為許多復雜NLP任務的一個通用的、強有力的基線,
CogLTX在“關鍵句子”假設下定義了一個用于長文本理解的管道,非常困難的序列級任務可能會違反它,因此高效的變分貝葉斯方法(估計z分布)與負擔得起的計算仍然值得研究,此外,CogLTX在塊前遺漏前件的缺點是,在我們的HotpotQA實驗中,在每個句子前添加物體名稱來緩解這一問題,未來可以通過位置感知檢索競賽或共指決議來解決,
備注:請結合原論文踐行閱讀,本博客僅涉及翻譯,初次讀論文可能有些地方翻譯的不正確,請提出來呢,論文詳解會在后續進行補充
論文地址:http://keg.cs.tsinghua.edu.cn/jietang/publications/NIPS20-Ding-et-al-CogLTX.pdf
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/241389.html
標籤:區塊鏈
下一篇:E: Failed to fetch http://ppa.launchpad.net/jonathonf/python-3.6/...