原始碼位置:
/src/atomicBlock/dataProcessorWrapper3D.hh
首先就為我們展示了applyProcessingFunctional,
template<typename T, template<typename U> class Descriptor>
void applyProcessingFunctional (
LatticeBoxProcessingFunctional3D<T,Descriptor>* functional,
Box3D domain,
std::vector<BlockLattice3D<T,Descriptor>*> lattices )
{
std::vector<AtomicBlock3D*> atomicBlocks(lattices.size());
for (pluint iLattice=0; iLattice<lattices.size(); ++iLattice) {
atomicBlocks[iLattice] = dynamic_cast<AtomicBlock3D*>(lattices[iLattice]);
}
executeDataProcessor( BoxProcessorGenerator3D(functional, domain), atomicBlocks );
}
它是根據不同區塊屬性而執行對應代碼,有LatticeBoxProcessing3D,ScalarFieldBoxProcessing3D,TensorFieldBoxProcessing3D等,
而integrateProcessingFunctional與applyProcessingFunctional的不同在于它是通過
addInternalProcessor( BoxProcessorGenerator3D(functional, domain),
atomicBlocks, level );
實作集成,
而apply是執行一次,
executeDataProcessor( BoxProcessorGenerator3D(functional, domain), atomicBlocks );
根據不同屬性的區塊,我們可以看到BoxProcessing3D_L,BoxProcessing3D_S,BoxProcessing3D_T等引數,
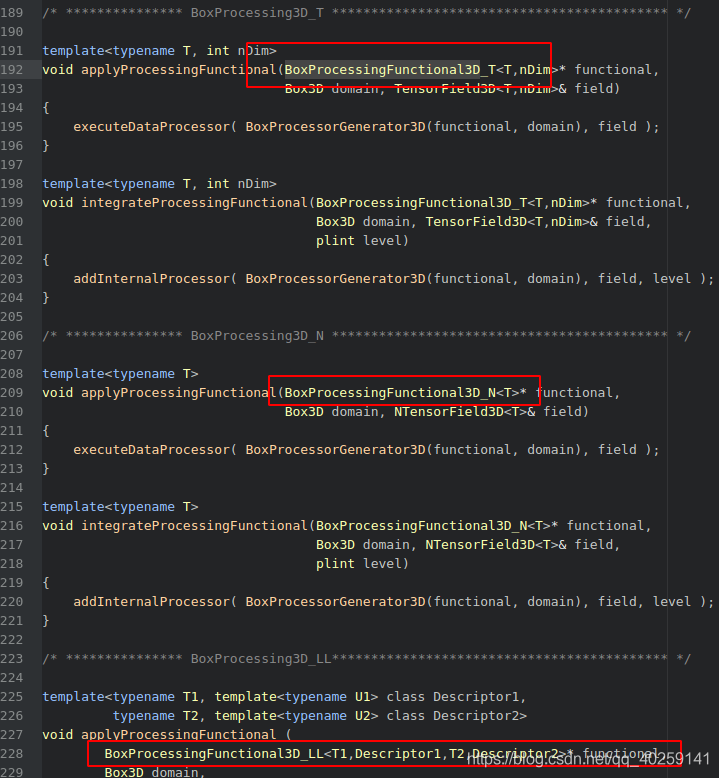 可以用作撰寫資料處理器的參考,
可以用作撰寫資料處理器的參考,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/241396.html
標籤:區塊鏈
下一篇:彈性布局(flex布局)