CS224W筆記-第十一課:PageRank
第11課的重點是相對傳統的連接分析,核心是PageRank演算法,全講座分3個部分,
- 2000年時期的Web的一個連接概覽;
- PageRank演算法的核心思想和具體工程實作中的關鍵點;
- PageRank演算法的一個變體,
除了第一部分,關于PageRank的部分可以用講義的最后一頁做一個非常好的總結,如下:
 整個PageRank的演算法可以從一個圖的隨機游走的角度來理解,根據閃跳(Teleport)的目的地不同,分成了課程里介紹的3種,具體下面筆記里總結,
整個PageRank的演算法可以從一個圖的隨機游走的角度來理解,根據閃跳(Teleport)的目的地不同,分成了課程里介紹的3種,具體下面筆記里總結,
90年代的Web概覽
本課的第一部分講了一篇2000年左右的論文,對當時的Web的情況做了一個快照研究,
這里的研究把Web看成了一個有向圖,圖中的節點是一個網頁,邊是超鏈接,邊的方向是從一個包含超鏈接的網頁指向超鏈接的網頁,當然,這里面的網頁的定義需要簡化,對于當時的Web,其中不包括動態生成的網頁和那些防火墻內無法被訪問到的網頁,以及一些爬蟲無法觸及的Web內容,
依托于通過超鏈接構建的有向同構圖,這個研究關注的問題是:
- Web是如何連接的?
- 當時的Web是怎樣的一副圖景?
強連通元件(SCC)
Web是一個有向圖,而有向圖里面只有兩種型別的元件:
- 強連通元件(SCC):SCC里的節點都兩兩可達, I n ( A ) = O u t ( A ) In(A) = Out(A) In(A)=Out(A),
- 有向無環圖(DAG):其中,如果 u u u可以有通路連接 v v v,則沒有通路從 v v v連到 u u u,
SCC的定義:
一個節點集 S S S,其中的任意兩個節點可以有鏈路到達,而沒有更大的集合具有這種特性,
90年代的Web概覽
而有向圖則可以被簡化成以SCC為節點的DAG,基于這種思想,1999年Broder等人對當時的Web進行了鏈接的分析,通過使用網路爬蟲爬取了2億多個URL以及15億條鏈接所組成的網路,
研究的核心問題是:Web是如何簡化成SCC,以及由此形成的DAG是什么樣的,
計算SCC有一個計算問題,即如何才能獲得包括節點
v
v
v的SCC,相應地就是如何找到Web里的SCC,這里的計算方法是基于一個發現,包含
v
v
v的SCC是
v
v
v可達的節點和可到達
v
v
v的兩個節點集合的交集,:
S
C
C
w
i
t
h
v
=
O
u
t
(
v
)
∩
I
n
(
v
)
=
O
u
t
(
v
,
G
)
∩
O
u
t
(
v
,
G
′
)
SCC \ with \ v= Out(v) \cap In(v) = Out(v, G) \cap Out(v, G')
SCC with v=Out(v)∩In(v)=Out(v,G)∩Out(v,G′)
其中,
G
G
G是原有向圖,
G
′
G'
G′是把
G
G
G里所有邊方向變換的圖,也就相當于是把
I
n
(
v
)
In(v)
In(v)變成了
O
u
t
(
v
)
Out(v)
Out(v),
在后續的Web概覽分析中,隨機選擇一個起點 v v v,然后BFS計算通過它可以訪問到的節點集合 O u t ( v ) Out(v) Out(v)和可以訪問到它的節點 I n ( v ) In(v) In(v),得到了下面的幾個結論:
1. 可觸達性(Reachability):
通過對
S
C
C
SCC
SCC的計算,可以得到每個節點可觸達的節點數,排序后可以得到下圖所示的可觸達性的結果,
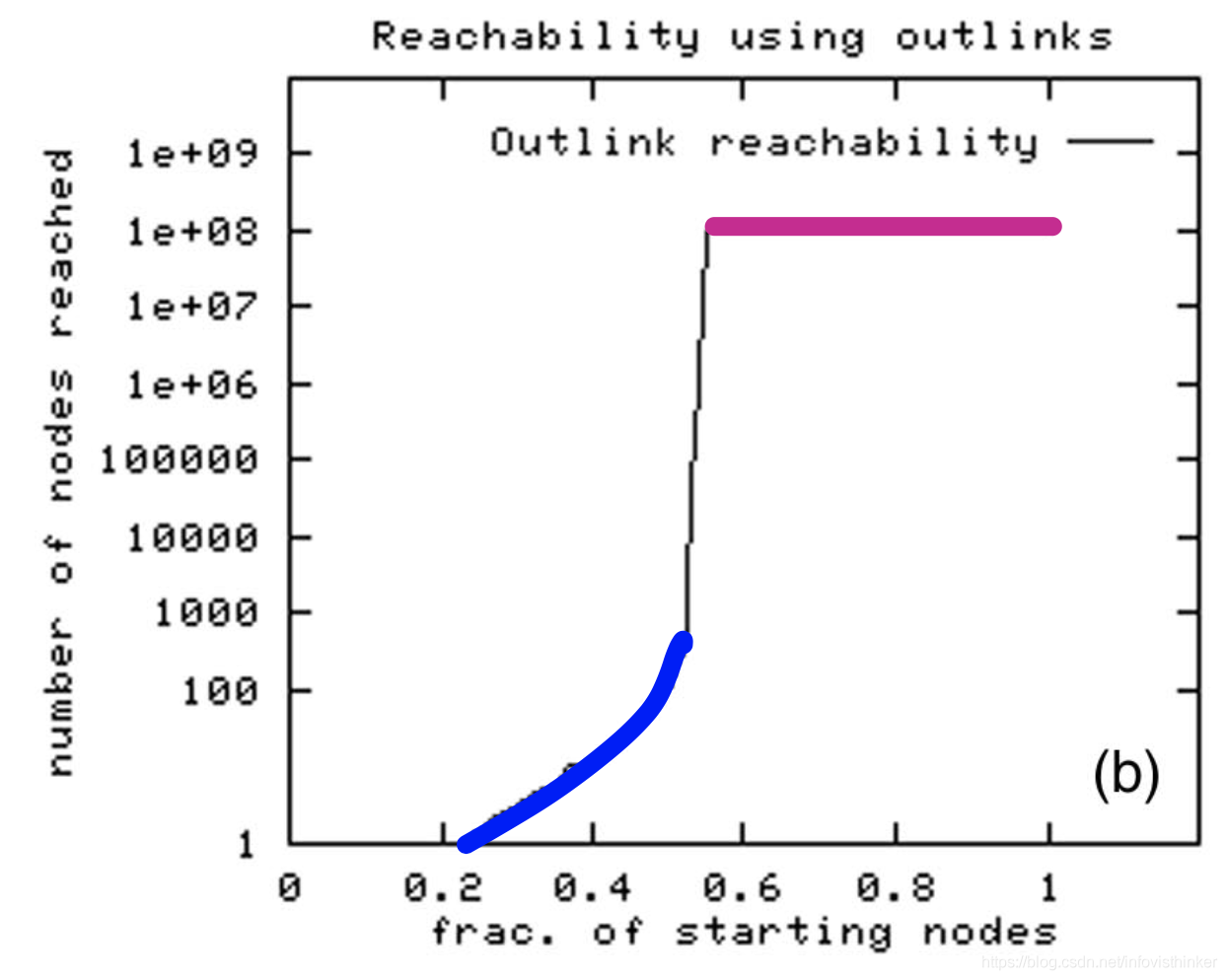 圖中的橫坐標是選擇的初始起節點的比例,按Jure的說法,是把節點按照可觸達節點的數量進行了排序,圖中的縱坐標是log后的可觸達節點的數量,
圖中的橫坐標是選擇的初始起節點的比例,按Jure的說法,是把節點按照可觸達節點的數量進行了排序,圖中的縱坐標是log后的可觸達節點的數量,
可以看到,當時的Web頁面的可觸達的頁面有一個明顯的跨越,50%的節點可觸達的節點不到1000,而另外的50%的節點則是可以觸達億級別的節點,
2. Web的SCC:
根據以上的統計,可以得到網頁(節點)可觸達和可被觸達的統計,并得到Web里的SCC的情況,
- O u t ( v ) = 100 M , 占 50 % 左 右 的 節 點 Out(v) = 100M,占50\%左右的節點 Out(v)=100M,占50%左右的節點
- I n ( v ) = 100 M , 占 50 % 左 右 的 節 點 In(v) = 100M,占50\%左右的節點 In(v)=100M,占50%左右的節點
- 最 大 的 S C C = 56 M , 占 28 % 左 右 的 節 點 最大的SCC = 56M,占28\%左右的節點 最大的SCC=56M,占28%左右的節點
3. Web概覽
上述的資料讓研究者勾勒出了90年代的Web的概覽,如下圖所示:
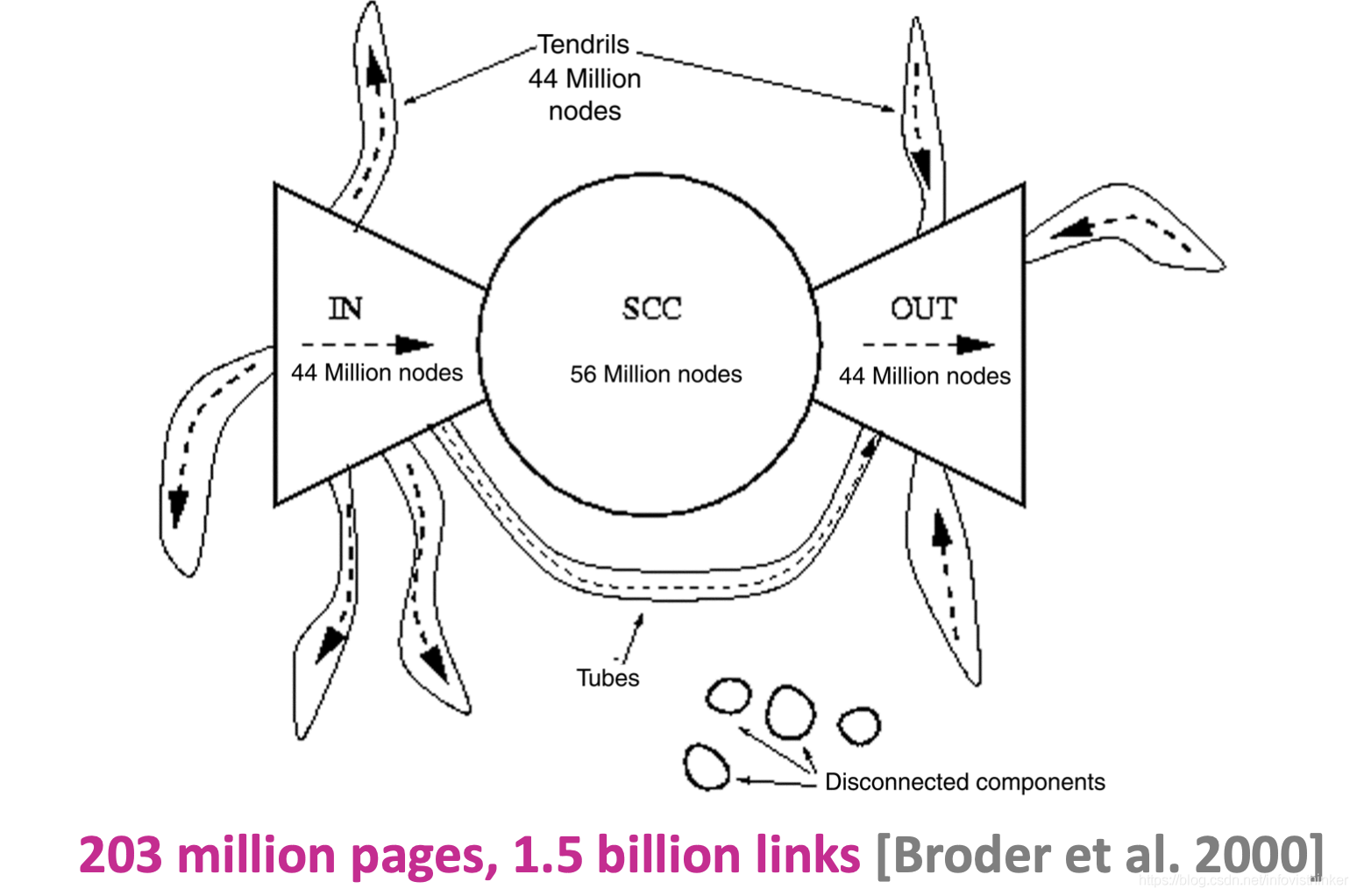
在90年代的Web就是中間一個巨大的SCC,包括5千6百萬個網頁,相互都有路徑可達;外加兩個單方向的大組件,各自包括大概4千4百萬個網頁,除此以外,就是一些突觸,包括一些小規模的單方向的網頁,
這個Web鏈接的概覽對于當時的互聯網而言是非常有意義的,對于當時野蠻生長的Web來收,這是第一次完整的刻畫,也為后來很多的基于鏈接關系進行搜索的演算法的產生帶來了靈感,最出名的是PageRank和HITS,二者的基本思想差不多,只是HITS的老師沒有創業,而PageRank則產生了谷歌,
PageRank
問題:PageRank和HITS需要解決的問題是一樣的,都是如何去衡量網頁的重要性,這是當時整個Web搜索的一個難題,通過關鍵字匹配進行資訊檢索的演算法在給出候選網頁后,無法更好地對結果進行排序,從而讓各種垃圾網頁回傳給搜索的用戶,
基本思路:
- 網頁的重要性可以通過指向它的鏈接(即投票機制)來衡量,畢竟別人認可你才會通過超鏈接來指向你,指向網頁的鏈接越多,重要性相對越高;
- 來自重要網頁的鏈接,它的重要性也更高,
基本公式:
定義網頁
j
j
j的排序值(重要性)
r
j
r_j
rj?如下:
r
j
=
∑
i
→
j
r
i
d
i
r_j = \displaystyle \sum_{i \to j} \frac{r_i}{d_i}
rj?=i→j∑?di?ri??
其中,
i
i
i是網頁
j
j
j的鄰居,并有鏈接指向它;
d
i
d_i
di?是網頁
i
i
i的出度值,
基本版PageRank
基本版PageRank的計算需要先構建一個隨機鄰接矩陣: M M M,方式如下:
- 對于包括 N N N個網頁的鏈接圖,構建 N × N N \times N N×N的鄰接矩陣,每行每列都表示一個網頁;
- 鄰接矩陣的每個節點的值 M ( i , j ) M_{(i,j)} M(i,j)?對應著 j j j列的平均出度 1 / d j 1/d_j 1/dj?,如果從網頁 j j j有一個鏈接到網頁 i i i,否則為 M ( i , j ) = 0 M_{(i,j)} = 0 M(i,j)?=0,
- 根據隨機鄰接矩陣的定義,每一列的和都是1.
再定義每個網頁 i i i具有重要性指標 r i r_i ri?,且約束所有網頁重要性 r r r的總和為1,即 ∑ i r i = 1 \sum_{i} r_i = 1 ∑i?ri?=1,按照上面的定義,并結合上面的基本公式的計算,則可以得到網頁重要性值 r r r和隨機鄰接矩陣 M M M的關系如下: r = M ? r r= M \cdot r r=M?r
熟悉矩陣計算的同學看到上的公式就可能會發現,這個公式和特征值的定義公式 ( A x = λ x ) (Ax=\lambda x) (Ax=λx)是非常像的,因為 M M M是一個方陣,即可分解出特征值和特征向量,所以上面的重要性 r r r就是隨機鄰接矩陣 M M M的特征值為 λ = 1 \lambda = 1 λ=1的特征向量,
雖然直接對 M M M進行特征分解就能獲得需要的 r r r,但是常規方法的計算復雜度是 O ( N 3 ) O(N^3) O(N3),對于Web的規模而言,這個計算量就無法承受了,不過基于 λ = 1 \lambda=1 λ=1這個優良的特征值的性質,可以看到 r = ( M ( M ( M . . . ( M ? r ) ) ) ) r= (M(M(M...(M\cdot r)))) r=(M(M(M...(M?r)))),因此 r r r就是 M ? r M \cdot r M?r的極限值,這樣的話就可以用迭代回圈的方法來得到 r r r,
課程視頻的順序和給出的PPT的順序在這里略微不同,Jure先從隨機游走的角度解釋了重要性 r r r就是在Web上進行無限隨機游走的靜態分布,也解釋了上面的極限計算的原理,和隨機游走的理解,以及為什么下面介紹的Power Iteration演算法的初始值設定的原因,這里會打破這個順序,先講Power Iteration和實際計算PageRank的方法,然后再仔細講講Web隨機游走,
Power Iteration演算法:
給定一個Web圖,其中包括 N N N個節點(頁面),頁面里的超鏈接構成了節點間的邊,并按照出度值構建了隨機鄰接矩陣構建 M \mathsf{M} M,
Power Iteration演算法分三步計算網頁的重要性 r r r:
- 初始化: r 0 = [ 1 / N , 1 / N , … , 1 / N ] T \mathsf{r}^0 = [1/N, 1/N, \dots, 1/N]^{\rm{T}} r0=[1/N,1/N,…,1/N]T
- 迭代計算: r ( t + 1 ) = M ? r ( t ) \mathsf{r}^{(t+1)} = \mathsf{M} \cdot \mathsf{r}^{(t)} r(t+1)=M?r(t)
- 終止條件: ∣ r ( t + 1 ) ? r ( t ) ∣ 1 < ε |\mathsf{r}^{(t+1)} - \mathsf{r}^{(t)}|_1 \lt \varepsilon ∣r(t+1)?r(t)∣1?<ε
在滿足終止條件或者最大迭代次數后,獲得的 r r r就是每個網頁的重要性值,這樣的話,計算量就近似是線性的,
PageRank的實際計算方法:
上述的Power Iteration演算法在實際的Web計算的時候會存在兩種情況,造成重要性計算的失效,從而不能完成對網頁實際排序的任務,
- 問題1: 如上面的Web概覽圖里所示,有大量的網頁會存在有進無出的情況,即死路,在隨機鄰接矩陣 M M M里,這些網頁節點的列的所有值都是0,
- 問題2: 蜘蛛陷阱問題,即所有的出度都在一組網頁內,這種情況下,所有的重要性都會最終傳導到這些節點里,
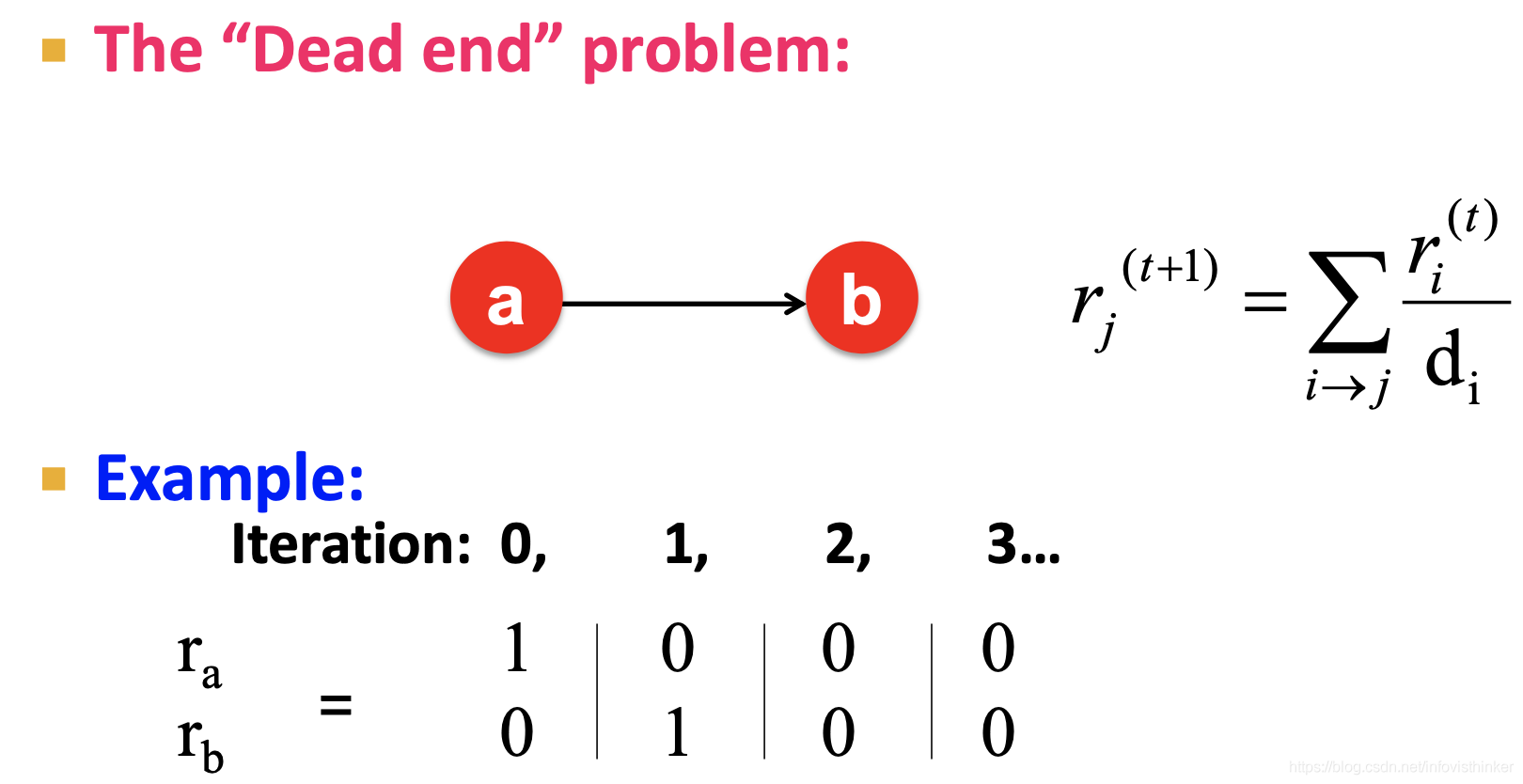
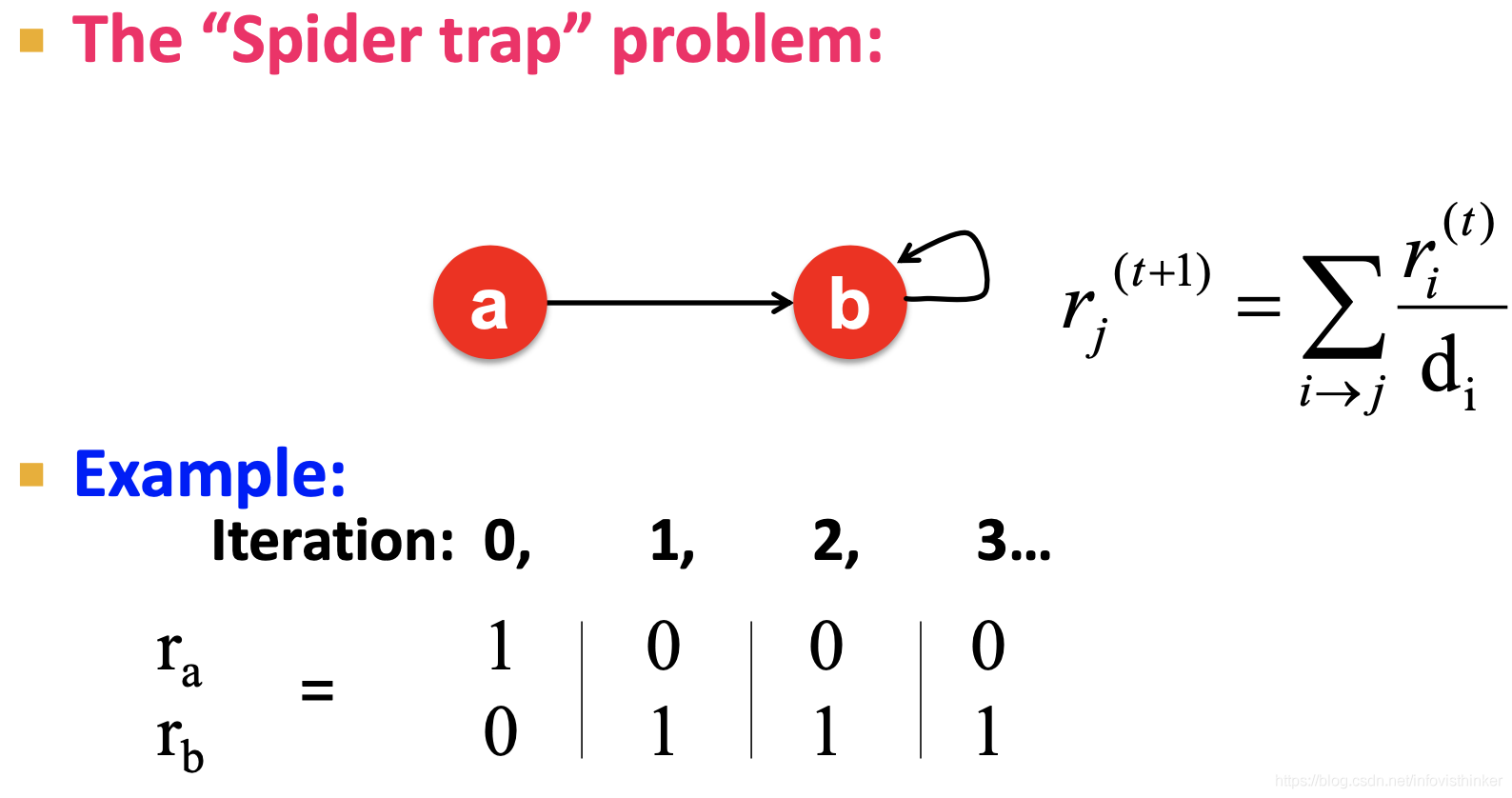
上面兩個例子演示了,存在死路節點,會讓所有節點的 r r r最終都變成了0;而那些蜘蛛節點則會把整個網路的重要性都匯聚到自己這里,最終只有它的 r r r成1,別人都是0,
隨機游走的概念和在PageRank里的應用
這兩種情況對應的原因是一致的,就是重要性沿著超鏈接傳播到這里,然后就消失或者困住了,如果用鏈接投票的概念來理解這個問就不是很直觀,這種情況下使用隨機游走的概念就好理解了,
隨機游走:
- 對于某個Web(包括 N N N個網頁),我們考慮有一個網路瀏覽者,它從一個網頁開始,沿著網頁里的超鏈接跳到(游走)其他的網頁上去,隨機的含義是指當從網頁跳出的時候,它會從所有的超鏈接里面等概率得隨機地選擇一個,
- 在某個時刻 t t t,這個瀏覽者處在某個網頁 i i i,當下一刻 t + 1 t+1 t+1,它通過超鏈接跳轉到網頁 j j j,
- 一直重復上述程序,不停止,
隨機游走概率分布
那么設定
p
(
t
)
∈
R
N
p(t) \in \R^{N}
p(t)∈RN為時刻
t
t
t的概率向量,其中第
i
i
i個元素是瀏覽者在此時刻處于網頁
i
i
i的概率,概率的總和為
1
1
1,那么對于隨機游走的情況下,
p
(
t
+
1
)
p(t+1)
p(t+1)的值會是:
p
(
t
+
1
)
=
M
?
p
(
t
)
p(t+1) = M \cdot p(t)
p(t+1)=M?p(t)
因為, p ( t + 1 ) p(t+1) p(t+1)的概率是由 p ( t ) p(t) p(t)和隨機鄰接矩陣 M M M共同決定的,這和公式 r j = ∑ i → j r i d i r_j = \displaystyle \sum_{i \to j} \frac{r_i}{d_i} rj?=i→j∑?di?ri??是一樣的,
假如, 在某個Web里,隨機游走可以達到一個狀態, p ( t + 1 ) = M ? p ( t ) = p ( t ) p(t+1) = M \cdot p(t) = p(t) p(t+1)=M?p(t)=p(t),這個時候就可以認為 p ( t ) p(t) p(t)是此Web里的隨機游走的穩態概率分布,從這個公式可以看出,上面PageRank的基本公式 r = M ? r r = M \cdot r r=M?r 里的 r r r就是隨機游走的穩態概率分布,
用隨機游走對上述2個問題進行理解
- 對于死路節點的問題,這相當于瀏覽者來到了這個網頁后,沒法再繼續游走了,雖然它停留在了這里,但是對于整個 p ( t ) p(t) p(t)來說,就不可能達到 p ( t + 1 ) = M ? p ( t ) = p ( t ) p(t+1) = M \cdot p(t) = p(t) p(t+1)=M?p(t)=p(t)的狀態,也就相當于這個概率分布無法收斂到一個固定值,
- 對于陷阱的問題,瀏覽者就被限制到了這個地方,在 p ( t + 1 ) p(t+1) p(t+1)的時刻,它處在陷阱的概率就是確定的1,所以這也不是我們想要達到的穩態概率分布,
從隨機游走的思路來解決上述問題
從隨機游走的角度理解了問題的根源,那么就可從隨機游走的角度來解決這兩個問題,解決方案很簡單,即讓瀏覽者在任何網頁上都有一定的概率直接瞬移(Teleport)到網路里的任意一個網頁,這也就相當于我們瀏覽網站的時候,不是按照里面的超鏈接來瀏覽,而是選擇一個新網站來瀏覽,
有了這個瞬移的方法,隨機游走就不會被限定到某個網頁里,從而讓 p ( t + 1 ) p(t+1) p(t+1)可以繼續收斂到某個穩態概率分布,
實際PageRank的演算法
根據上述的跳出的思想,基礎的PageRank的演算法修改成如下的方式:
r
j
=
∑
i
→
j
β
r
i
d
i
+
(
1
?
β
)
1
N
(1-單節點計算)
\tag{1-單節點計算} r_j = \displaystyle \sum_{i \to j} \beta \dfrac{r_i}{d_i} + (1-\beta) \dfrac{1}{N}
rj?=i→j∑?βdi?ri??+(1?β)N1?(1-單節點計算)
r
=
A
?
r
,
a
n
d
A
=
β
M
+
(
1
?
β
)
[
1
N
]
N
×
N
(2-矩陣計算)
\tag{2-矩陣計算} r = A * r, and \ A = \beta M + (1-\beta) {\genfrac [ ] {1pt}{1}1{N}}_{N \times N}
r=A?r,and A=βM+(1?β)[N1?]N×N?(2-矩陣計算)
這里的 β \beta β是一個是否不跳出的概率,即在每個網頁上,瀏覽者都有 1 ? β 1-\beta 1?β的可能性不按照出鏈接來游走,而是隨機的跳到整個Web的任何一個網頁上,這樣就帶走了 1 ? β 1-\beta 1?β的重要性的值,平均分配給所有節點,
這個從公示1里可以看出,每個節點接收來自直接領居的重要性,但是被打了折扣,被扣除的重要性會從整個Web的跳出重要性里獲取一份均值,
這個方法如果改進成可迭代的矩陣模式就是公式(2),要注意的是這里公式1和2是在一定條件下才完全等價,因為公式(2)里面每個隨機鄰接矩陣的元素都被加了 1 ? β N \dfrac{1-\beta}{N} N1?β?,在和 r r r相乘后相加,變成了 ( 1 ? β N ) ∑ j r j (\dfrac{1-\beta}{N})\sum_j r_j (N1?β?)∑j?rj?,如果我們的Web里面沒有死路,那么 r r r的和是 1 1 1,就和公式(1)一樣了,但是由于死路節點的存在, r r r的和會小于 1 1 1,這樣兩個公式就不等價了,
矩陣
A
A
A計算的問題
使用上面所說的Power Iteration的方法,可以對
r
=
A
×
r
r = A \times r
r=A×r進行迭代計算出PageRank的值,但是在實際的計算中會遇到無法計算的問題,
核心的問題是把
(
1
?
β
)
[
1
N
]
N
×
N
(1-\beta) {\genfrac [ ] {1pt}{1}1{N}}_{N \times N}
(1?β)[N1?]N×N?加入到隨機鄰接矩陣后,原本非常稀疏的隨機鄰接矩陣
M
M
M變成了稠密的矩陣
A
A
A,這樣的矩陣對記憶體的要求是例外的大,以至于在MapReduce這樣的分布式技術出現前是無法處理的,所以谷歌就把矩陣
A
A
A的迭代計算修改回了公式1的方式,變成了:
r
=
β
M
?
r
+
(
1
?
β
)
[
1
N
]
N
(3)
\tag{3} r = \beta M \cdot r + (1-\beta) {\genfrac [ ] {1pt}{1}1{N}}_{N}
r=βM?r+(1?β)[N1?]N?(3)
這里的計算就可以用稀疏矩陣的乘法來對
M
M
M和
r
r
r進行存盤和運算,而
(
1
?
β
)
[
1
N
]
N
(1-\beta) {\genfrac [ ] {1pt}{1}1{N}}_{N}
(1?β)[N1?]N?是一個
N
N
N維的向量,所需的存盤很小,課堂上Jure說是計算這個版本刺激了谷歌開發出了MapReduce,可見計算量依然很大,
完整的PageRank演算法
根據公式(3),完整的PageRank演算法如下:
輸入:
- 有向圖 G G G,有 N N N個節點,其中可以包括死路節點和陷阱節點,
- 引數 β \beta β,一般取 0.8 ∽ 0.9 0.8 \backsim 0.9 0.8∽0.9間的一個值,通常為0.85,
輸出:PageRank向量 r n e w r^{new} rnew
- 初始設定 r j o l d = 1 N r_j^{old} = \dfrac{1}{N} rjold?=N1?
- 遞回回圈,直到
∑
j
∣
r
j
n
e
w
?
r
j
o
l
d
∣
<
ε
\sum_j |r_j^{new}-r_j^{old}|< \varepsilon
∑j?∣rjnew??rjold?∣<ε
- 對于每個網頁 j , ? j ′ n e w = ∑ i → j β r i o l d d i j, \ \forall j^{\prime new} = \sum_{i \to j} \beta\dfrac{r_i^{old}}{d_i} j, ?j′new=∑i→j?βdi?riold??,如果網頁 j j j沒有入度,則 r j ′ n e w = 0 r_j^{\prime new}=0 rj′new?=0
- 然后, ? j n e w = j ′ n e w + 1 ? S N \forall j^{new}=j^{\prime new} + \dfrac{1-S}{N} ?jnew=j′new+N1?S?,其中, S = ∑ j j ′ n e w S=\sum_j j^{\prime new} S=∑j?j′new
- r o l d = r n e w r^{old} = r^{new} rold=rnew
這里的演算法和上面的公式(3)還有所區別,就是并沒有對每個網頁加上 1 ? β N \dfrac{1-\beta}{N} N1?β?,而是 1 ? S N \dfrac{1-S}{N} N1?S?,這樣計算就直接避免了死路節點帶來的 r r r和小于1 的問題,
下面會采用課程里的一個例子圖來按上面的不同的公式來計算PageRank的值進行理解,
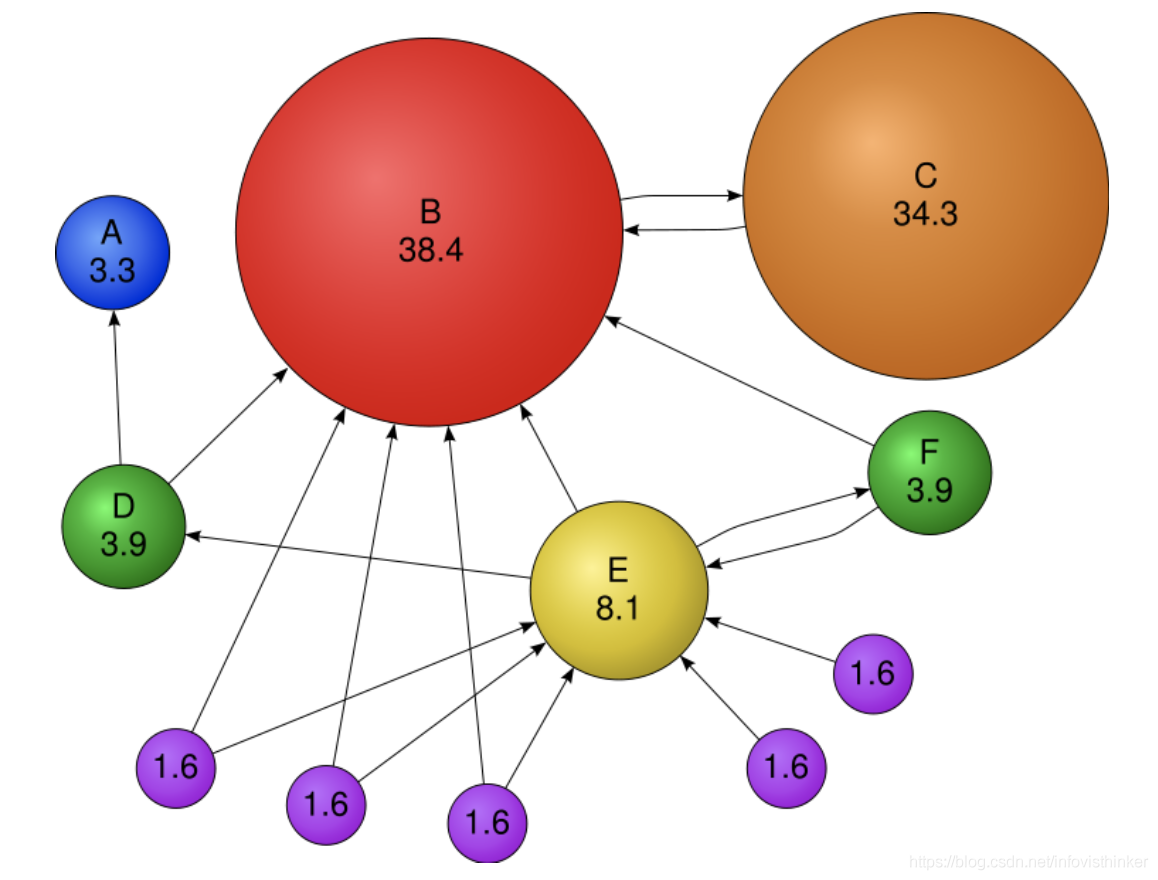
對應的隨機鄰接矩陣如下:
M
=
0.
0.
0.
0.5
0.
0.
0.
0.
0.
0.
0.
0.
0.
1.
0.5
0.333
0.5
0.5
0.5
0.5
1.
1.
0.
1.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.333
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.5
0.5
0.5
0.5
0.
0.
0.
0.
0.
0.
0.333
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
0.
M = \begin{array}{cc} 0. & 0.& 0.& 0.5& 0.& 0. & 0.& 0.& 0.& 0.& 0. \\ 0.& 0.& 1.& 0.5& 0.333 & 0.5 & 0.5& 0.5& 0.5& 1.& 1. \\ 0.& 1.& 0.& 0.& 0.& 0. & 0.& 0.& 0.& 0.& 0. \\ 0.& 0.& 0.& 0.& 0.333 & 0. & 0.& 0.& 0.& 0.& 0. \\ 0.& 0.& 0.& 0.& 0.& 0.5 & 0.5& 0.5& 0.5& 0.& 0. \\ 0.& 0.& 0.& 0.& 0.333 & 0. & 0.& 0.& 0.& 0.& 0. \\ 0.& 0.& 0.& 0.& 0.& 0. & 0.& 0.& 0.& 0.& 0. \\ 0.& 0.& 0.& 0.& 0.& 0. & 0.& 0.& 0.& 0.& 0. \\ 0.& 0.& 0.& 0.& 0.& 0. & 0.& 0.& 0.& 0.& 0. \\ 0.& 0.& 0.& 0.& 0.& 0. & 0.& 0.& 0.& 0.& 0. \\ 0.& 0.& 0.& 0.& 0.& 0. & 0.& 0.& 0.& 0.& 0. \\\end{array}
M=0.0.0.0.0.0.0.0.0.0.0.?0.0.1.0.0.0.0.0.0.0.0.?0.1.0.0.0.0.0.0.0.0.0.?0.50.50.0.0.0.0.0.0.0.0.?0.0.3330.0.3330.0.3330.0.0.0.0.?0.0.50.0.0.50.0.0.0.0.0.?0.0.50.0.0.50.0.0.0.0.0.?0.0.50.0.0.50.0.0.0.0.0.?0.0.50.0.0.50.0.0.0.0.0.?0.1.0.0.0.0.0.0.0.0.0.?0.1.0.0.0.0.0.0.0.0.0.?
這里面節點A是一個死路,它的隨機鄰接矩陣的向量是全0,使用Google Matrix,即公式(2),計算PageRank就會發生PageRank泄漏的情況,計算模擬(迭代50次, β \beta β取0.8)后得到的PageRank是 [ 0.01212338 , 0.14942966 , 0.12985629 , 0.01260778 , 0.02068081 , 0.01260778 , 0.00694528 , 0.00694528 , 0.00694528 , 0.00694528 , 0.00694528 ] [0.01212338, 0.14942966, 0.12985629, 0.01260778, 0.02068081, 0.01260778, 0.00694528, 0.00694528, 0.00694528, 0.00694528, 0.00694528] [0.01212338,0.14942966,0.12985629,0.01260778,0.02068081,0.01260778,0.00694528,0.00694528,0.00694528,0.00694528,0.00694528],總和是 0.372 0.372 0.372,出現了明顯的泄漏情況,所以需要在每輪迭代的時候,把PageRank的和擴展到1,再次計算,使用這個方法,得到的新PageRank是 [ 0.03258693 , 0.40189786 , 0.34880602 , 0.03388896 , 0.05558877 , 0.03388896 , 0.0186685 , 0.0186685 , 0.0186685 , 0.0186685 , 0.0186685 ] [0.03258693, 0.40189786, 0.34880602, 0.03388896, 0.05558877, 0.03388896, 0.0186685, 0.0186685, 0.0186685, 0.0186685 , 0.0186685 ] [0.03258693,0.40189786,0.34880602,0.03388896,0.05558877,0.03388896,0.0186685,0.0186685,0.0186685,0.0186685,0.0186685]
使用公式3進行計算,只需要進行一次矩陣乘法,剩下的都是向量計算,得到的PageRank是 [ 0.03551728 , 0.39001296 , 0.33644825 , 0.03688094 , 0.06043515 , 0.03688094 , 0.02076489 , 0.02076489 , 0.02076489 , 0.02076489 , 0.02076489 ] [0.03551728, 0.39001296, 0.33644825, 0.03688094, 0.06043515, 0.03688094, 0.02076489, 0.02076489, 0.02076489, 0.02076489, 0.02076489] [0.03551728,0.39001296,0.33644825,0.03688094,0.06043515,0.03688094,0.02076489,0.02076489,0.02076489,0.02076489,0.02076489],同時和為1,
到這里就結束了PageRank的核心思路和演算法的介紹,課程的最后是對兩種隨機游走場景的介紹,
重新開始的隨機游走和個性化PageRank
重新開始的隨機游走(Random Walk with Restart)
這個演算法針對的是二分圖的場景,目的是針對某個節點,計算出和其他節點和它的關系,它的基本思想也很簡單,就是針對某個查詢節點,其他節點和它的相似性可以通過從它開始的隨機游走所經過的節點的次數來衡量,但是在游走程序中,經過每個節點時,都有一定個概率
α
\alpha
α會跳回初識的查詢節點,重新開始游走,在一定的游走次數后,經過的其他節點的計數就可以作為和查詢節點的相似度,演算法的代碼和例子如下圖所示:
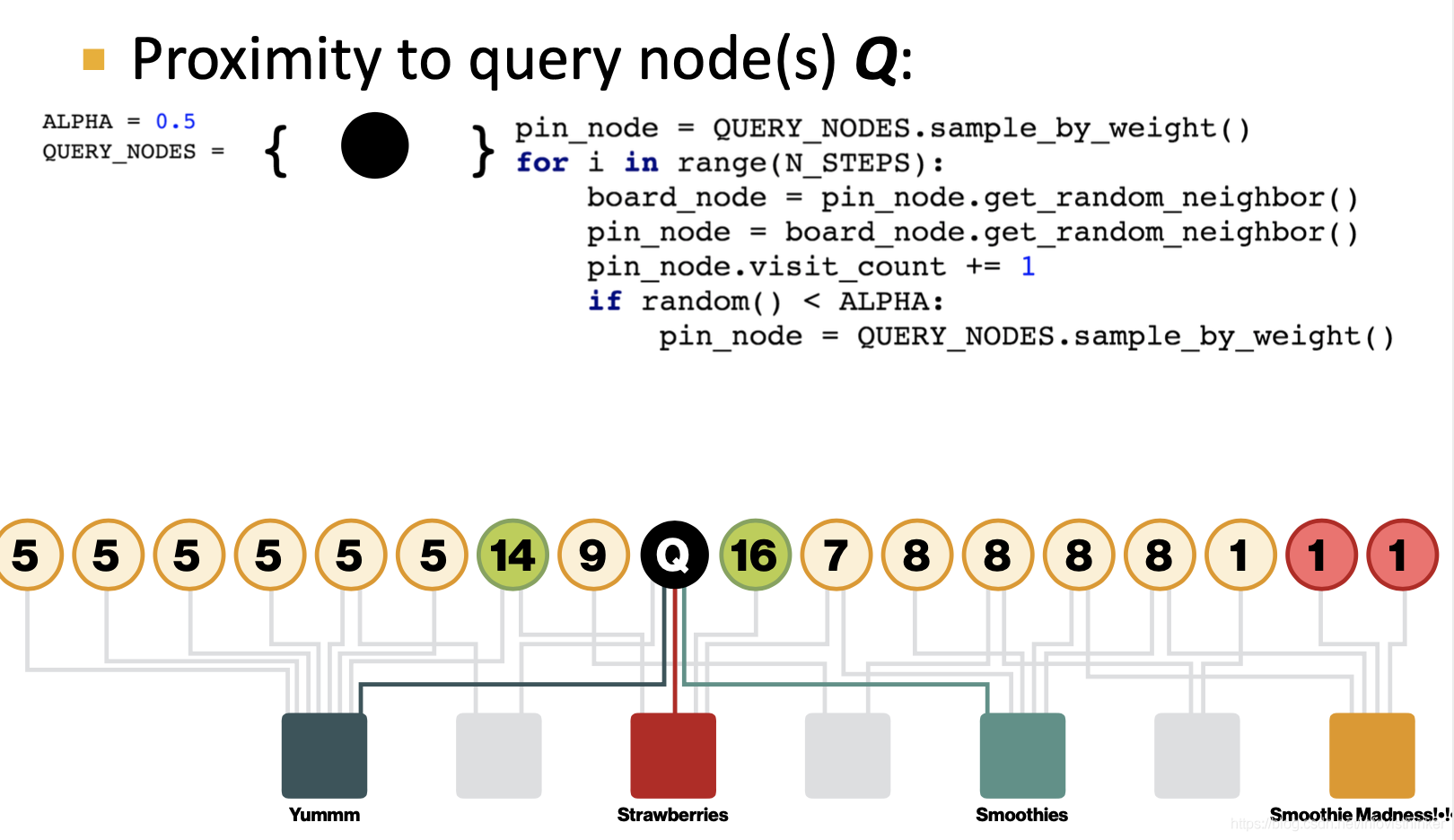
這個演算法雖然簡單,但是卻能充分利用圖的結構資訊,而且可以很容的并行執行,不需要做矩陣運算,所以很實用,
個性化PageRank
上面的重新開始的隨機游走和PageRank所代表的隨機游走的區別是,PageRank里,游走著閃跳的目標節點是圖里的所有節點,而重新開始的隨機游走總是要閃跳會初始的查詢節點,
而個性化PageRank則是在這兩種情況的中間,即游走閃跳的目標是圖里面的一部分節點,通過這個方法可以計算一批節點和其他節點的相似度,
至此第十一課的內容就全部結束了,對最后的三種演算法的總結已經在筆記的最開始部分,這里不再重復,
從開始寫第十一課到結束,前后有2個多月,也是很辛苦,中間作業繁忙,家里事情也很多,但是PageRank是當年的一個非常重要且常見的圖演算法,所以一定要搞懂,下面繼續第12和13課,將的都是圖結構里的事件傳播,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/243905.html
標籤:區塊鏈
上一篇:【TensorFlow 2 gpu 安裝】步驟2 - ubuntu 20.04 安裝 NVIDIA Container Toolkit Nvidia Docker 2