Enhancing deep neural networks via multiple kernel learning
發表于 pattern recognition 2020
代碼:https://github.com/IvanoLauriola/MKLpy
doi : 10.1016/j.patcog.2020.107194
另搭配 Sci-Hub 食用更佳
Sci-Hub 實時更新 : https://tool.yovisun.com/scihub/
公益科研通文獻求助:https://www.ablesci.com/
Highlights:
?We introduce KerNET, which combines Deep Neural Networks and Multiple Kernel learning;
?The framework optimally aggregates the hidden representations of a Deep Neural Network.
?KerNET enables to boost the predictive accuracy of individual Deep Neural Networks.
?KerNET allows to relieve the overfitting problem in deeper architectures.
多核學習:
存在一個函式 φ:X→K,它將資料從輸入空間X映射到內核空間K,從而 k(x,z)= {φ(x),φ(z)} ,其中 x,z∈X,
處理內核方法時,最重要的步驟是選擇內核函式,通常,使用驗證程序從一組預定義函式中為給定任務選擇最合適的內核,最近提出了幾種直接從資料中學習核函式的方法,流行的內核學習范例是多內核學習(MKL),其目的是將內核作為基本(或弱)內核的原則組合來學習內核,該文已經考慮了基本核的凸組合,即權重向量具有固定1范數(fixed 1-norm)的線性非負組合,即等式1,
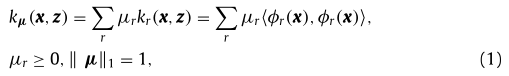
其中 k r 是基于第 r 個映射 φr 的核函式,μ 是演算法學習的權重向量,
深度神經網路依賴于非線性映射的堆疊序列,該序列提供了越來越復雜的輸入資料表示,這種模型執行的計算可以用非線性函式 φnet:X→Y 來描述,該函式將輸入資料從輸入空間 X 映射到輸出空間 Y,在一般深度前饋神經網路FFNN的情況下,該函式可以將 φnet 定義為基本映射函式的組成:
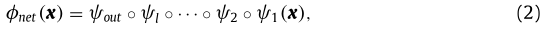
其中ψ1將輸入映射到第一個隱藏層,每個后續ψr對從隱藏層 r ? 1 到隱藏層 r 進行非線性變換,即:ψr(x)= g(W r x + b),其中 W r 是權重矩陣,b 是偏差矢量,g 是非線性函式,該概念可以輕松地擴展到更復雜的層型別,例如卷積層,其中矩陣乘法由卷積運算子代替,最后,ψout 將表示形式從最高層映射到輸出,符號 l 表示架構中的隱藏層數,(普通卷積操作
設 φnet 為 ψ1,… ,ψl 的FFNN基本映射,基于等式2中描述的網路定義,可將 x 在隱藏層 r 的隱藏表示定義為前 r 個基本映射函式的組成,即:
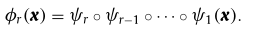
or
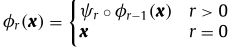
φ0(x)= x 表示輸入,圖1上部的箭頭指示由神經體系結構中的連續隱藏層實作的基本映射功能的操作,即 ψ1,…,ψl,其后是輸出映射 ψout,這樣的映射函式由權重矩陣 W 來引數化,通過基本映射的連續應用執行的計算確定了隱藏層的內部神經表示的發展,如圖1下部所示,即 φ1, ,φl 以及初始輸入表示 φ0,
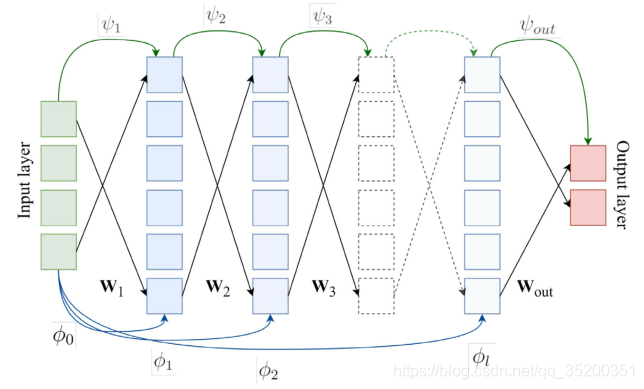
圖1:神經網路的體系結構描述為將輸入與輸出層相關聯的非線性函式的組合, φr是第r個隱藏層的內部表示,它是通過非線性變換ψ1,…,ψr的堆疊序列形成的, W是定義轉換的權重矩陣,
在KerNET框架中,中間表示 φr 通過多核學習(MKL)組合,
通常,深層前饋神經網路(FFNN)僅通過使用架構的最后一個隱藏層中計算出的表示(即 φl(x))來執行分類,但是,在輸出計算階段先前的中間表示通常被忽略,我們旨在有效利用輸入資料上的不同觀點,
不是最后一個隱藏層的表示,而是所有隱藏層的表示組合,可以提高神經網路的性能和泛化能力,(改變網路連接方式
首先訓練一個深度FFNN,該階段包括模型選擇步驟,以選擇最佳的超引數配置,然后,每個中間表示 φr 包括輸入 φ0,用于構建基本核k
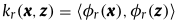
最后根據等式1,通過MKL演算法將基本內核合并.
結果表示依賴于更豐富的特征空間,根據組合中的貢獻,第一層和最后一層都涉及分類,

CNN卷積層的輸出不是像以前的體系結構那樣的單個矢量,而是一個張量,其形狀取決于輸入影像的尺寸乘以濾波器的數量,這樣,在訓練了網路之后,中間表示便被展平以構建內核,去除影像的結構和空間資訊的這種平坦化操作不是限制性的,實際上,通常在堆疊的卷積序列之后將平整層應用于網路,
與經典體系結構的主要區別在于,所有層都同時連接到輸出,這對應于在輸出之前放置的“虛擬”密集層,它由所有先前層(包括輸入層)的串聯組成,這樣,保留了具有不斷增加的復雜性表示的深層體系結構,但允許輸出計算(即最終預測)利用來自整個網路的資訊,
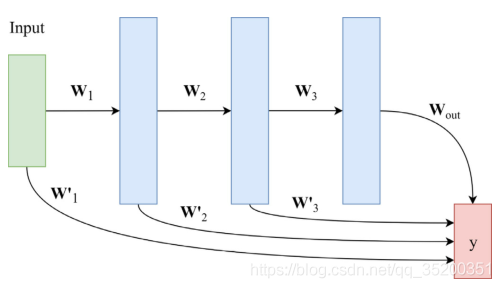
(與語意分割的FCN結構類似
與FCN之間存在一些差異,首先,FCN通過逐元素加法而不是級聯來組合層,其次,FCN結合了池化層而不是flatten的卷積,最后,雖然最初是針對語意分割性質的任務引入FCN方法的,但在此我們考慮一般分類任務的情況,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/249809.html
標籤:區塊鏈