文章目錄
- 前言
- Merkle樹
- hash list(哈希串列)
- 兩者區別
前言
文章標題中提到的其實是兩種資料結構-Merkle樹與hash list,前者俗稱默克爾樹,有些小伙伴可能會說,這兩種資料結構以前怎么沒有聽說過呢?
其實這兩種資料結構就根本不是為了我們所熟知的http/https協議所設計的,相反,他們是為了p2p網路或者說是區塊鏈網路而設計運用的,接下來我們慢慢進入正題,
Merkle樹
有關上文提到的http/https協議和p2p網路的區別,這里不做多介紹,可以參考我上兩篇博客,這里直接介紹資料結構,
首先Merkle樹本質上就是一個樹,而且還是一個二叉樹,直接上圖:
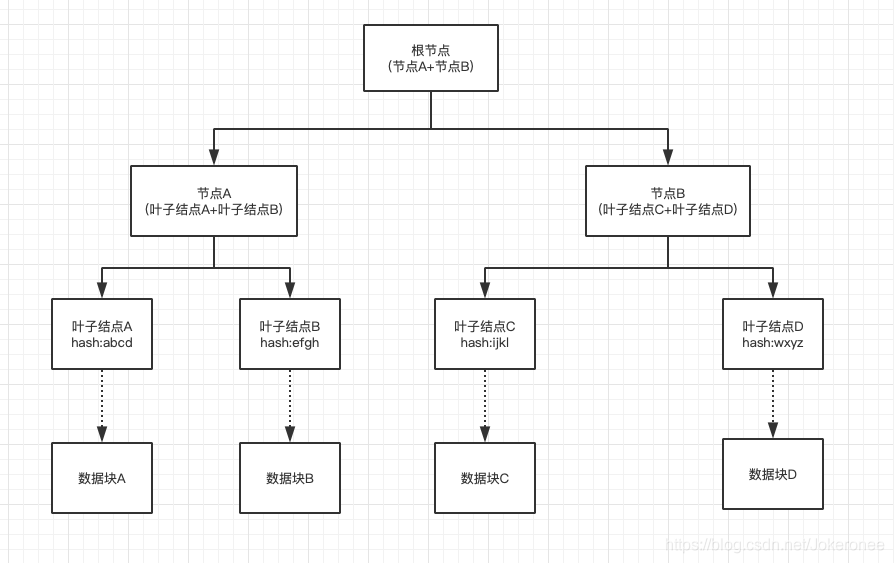
可以看到葉子結點下面居然還有一層資料塊,按理說葉子結點應該就是結束了,下面沒東西了,那么資料塊又是啥呢?
這里是這樣的,葉子結點存盤的是資料塊內的資料根據哈希演算法計算出來的哈希值(hash), 說白了就是存盤著哈希值,得到哈希值之后,在將相鄰的兩個結點合起來再計算一次哈希值,存盤在它們的父結點中,像上圖中的結點A存盤著葉子結點A與葉子結點B的哈希值結合,同理,結點A與結點B在結合進行一次哈希計算,得到根節點的哈希值,
在這里需要注意一下,如果葉子結點的個數是奇數怎么辦,那么就不能兩兩配對,進行結合哈希計算了,答案是也可以的,與自己配對進行結合哈希計算即可,
資料結構大致就是這個流程,不難理解,那么問題又來了,這樣子設計有什么好處呢?
在前言中就介紹到了,Merkle樹是運用在p2p或者區塊鏈網路中的,而IPFS就是里面的代表,有關這方面可以參考之前的博客《區塊鏈雜談—談談我所理解的IPFS》與《區塊鏈雜談—簡單記錄Fil是個啥?》,
我們知道在Fil網路中,主網會要求礦工提交復制證明,即證明礦工是真實且正確存盤了客戶所要的資料,而怎么驗證這個資料的正確性呢?就要用到我們所介紹的MerKle樹了,
我們知道哈希演算法,只要有一個位元組不一樣,那么最終計算出來的哈希值就會不相同,那么就可以直接比對根節點的哈希值,如果不一樣,那就說明沒有存盤到正確的資料,從而比對出了資料的完整性,
這里打個比方,簡單說明比對程序,還是上面那張圖:
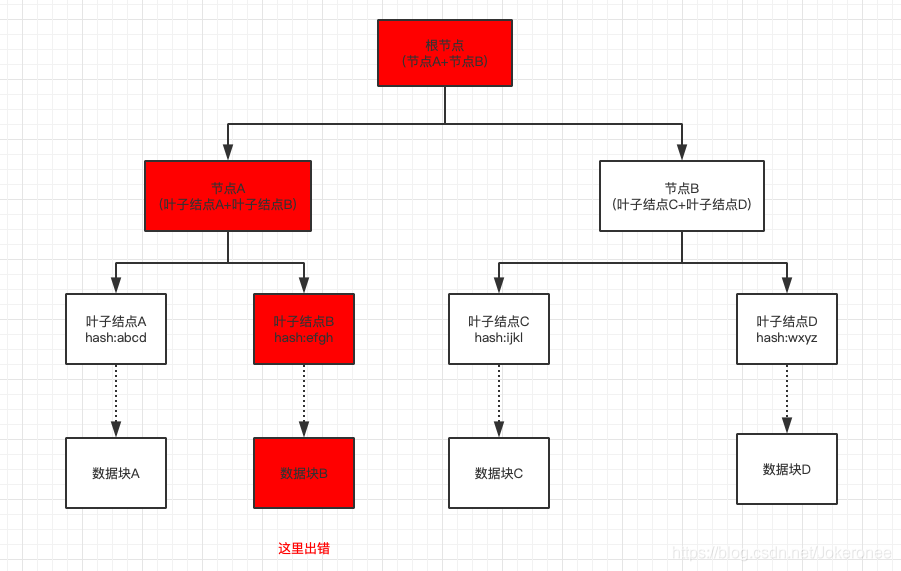
- 首先比對根節點的哈希值,發現不一樣,
- 接著往下走先比較結點A是否一致,發現不一致,再往下走,
- 葉子結點A一致,比較葉子結點B的哈希,發現不一致,找到資料塊B不一致,
這里就定位出了具體哪一個資料塊受損或者被攥改,由于每次比對它的規模都減半,所以在Merkle樹中,它的比對時間復雜度為O(logn),可以看到,效率還是很快的,
Merkle樹還被用于在分布式的資料庫中,一個檔案在分布式資料庫中可能會有多個備份,要確保備份之間的一致性,就可以用到默克爾樹了,
hash list(哈希串列)
接下來記錄一下另外一種資料結構—hash list(哈希串列),它和Merkle樹很像,可是又不一樣,先上圖:
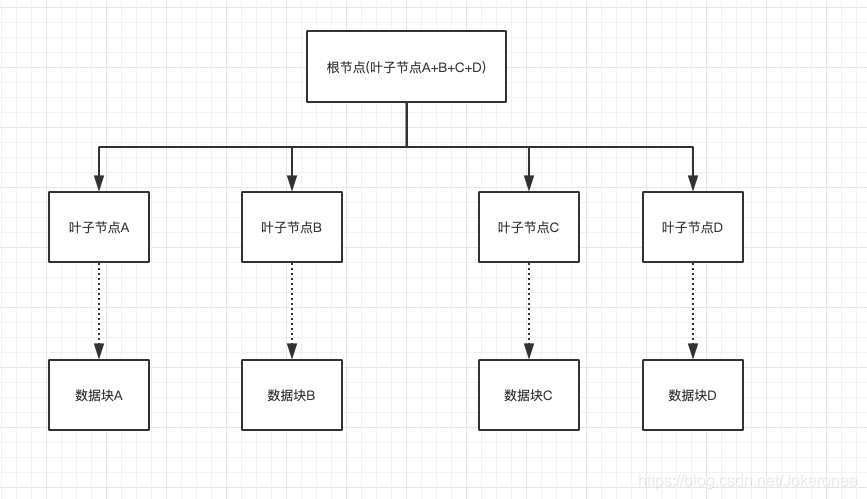
大家可以看一下,它比Merkle樹少了什么?沒錯,哈希串列根節點下面就直接一層葉子節點,而葉子結點存盤的是資料塊資料進行哈希運算得到的值,
這一段是我在網上看到的:
在點對點網路中資料傳輸的時候,為了提高效率往往會同時從多個機器下載資料的不同部分,
即,不是從一臺機器下載整個資料,而是將完整資料分成不同的部分,
分別同時從不同的機器獲取完整資料的不同組成部分,
這樣分塊傳輸不但可以同時從多臺機器下載資料,另一個好處是如果這一小塊資料傳輸程序中損壞了,
只要重新下載這一小資料塊就可以了,不用重新下載整個資料,
在這種環境下,怎么確保資料的完整性呢?
我們可以在下載前,對每一個資料塊進行一次哈希運算,然后在對這些資料塊哈希進行一次結合哈希運算,得到根哈希,從而得到一個哈希串列,這個串列我們自己存著,
之后就可以下載資料了,下載完成后,直接比對根哈希,如果一致,則說明沒有損壞,如果不一致,像上面Merkle樹一樣,去比對那個資料塊受損或者被攥改,
兩者區別
大家發現,兩個資料結構都有相似的功能,那么怎么選呢?
哈希串列比對資料時,是直接進入葉子節點來比較,而不像Merkle樹那樣,有個二叉樹分出去,所以它的時間復雜度為O(n),
因此,在資料量大,資料塊多的時候,Merkle樹的效率會更高,
感謝您的觀看🙏
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/250277.html
標籤:區塊鏈