摘要:本次練習,采用了三個資料集,generate_data,breast cancer以及癲癇資料集,對于feature bagging ,使用breast cancer資料集,探索提高基分類器的個數,發現測驗集的precision @ n 的精度先升高后下降,后來針對基分類器的個數,畫出了breast cancer資料集的曲線,該開始沒有控制train_test_split的random_state,沒有單一變數,所以結果不對,但是后來發現,控制完以后,每次的結果也是不一樣的,但是大部分情況下,曲線是比較穩定的,偶爾會有一個小的上沖,隨后下降,基分類器的數目,只要影響的是訓練集的precision @ n所以,基本上,選擇默認的個數就可以了,也可能存在一定概率會有更好的可能性,random_state會影響最后的結果,尤其對于例外數目較少的資料,
目錄
- 1.筆記
- 1.1 簡介
- 1.1.1 維度詛咒
- 1.2 Feature Bagging
- 1.2.1簡介
- 1.2.2 基檢測器
- 1.2.3 組合方法
- 1.3 Isolation Forests
- 1.3.1 簡介
- 1.3.2 原理
- 1.3.3 步驟
- 2.練習
- 2.1 feature bagging
- 2.1.1 Generate data
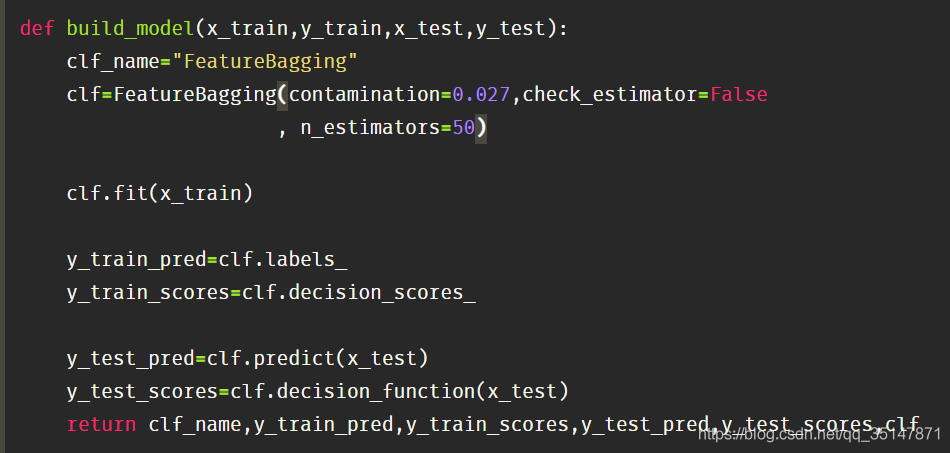
- 2.1.2 breast cancer(10 abnormal)
- 2.1.3 癲癇資料集
- 2.2 Isolation Forests
- 2.2.1 generate data
- 2.2.2 breast cancer(10 abnormal)
- 2.2.3癲癇資料集
- 2.3 思考題:feature bagging為什么可以降低方差?
- 2.4 思考題:feature bagging存在哪些缺陷,有什么可以優化的idea?
- 3.附件
1.筆記
1.1 簡介
這一節主要講的是,高維資料的例外檢測,包含三個部分:簡介維度詛咒,以及兩種方法(Feature Bagging和Isolation Forests)的詳細論述,
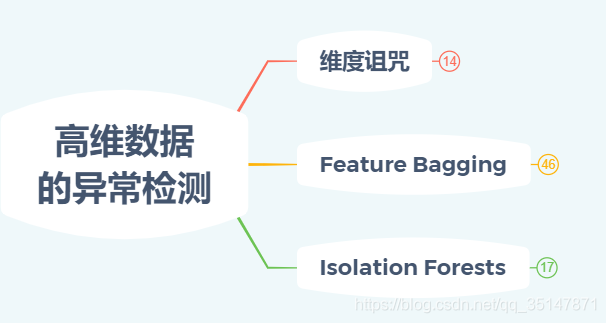
1.1.1 維度詛咒
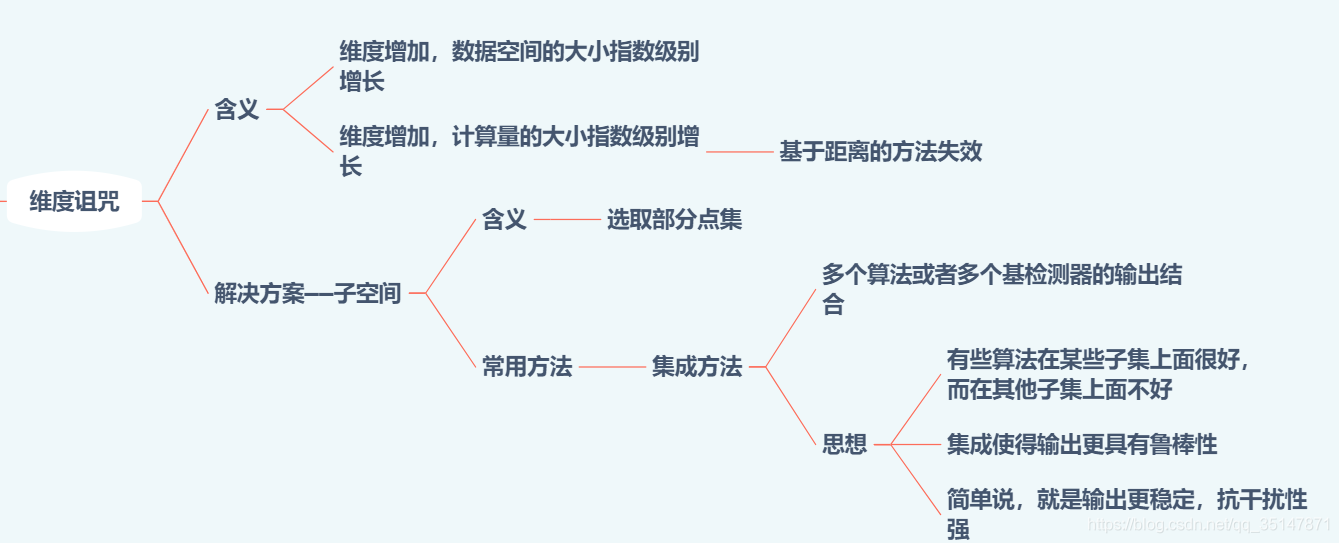
這部分講述了維度詛咒的含義,以及解決方案,
1.2 Feature Bagging
這部分主要講解了簡介、基檢測器以及組合的方法
1.2.1簡介
主要簡介集成方法的分類,方差與偏差
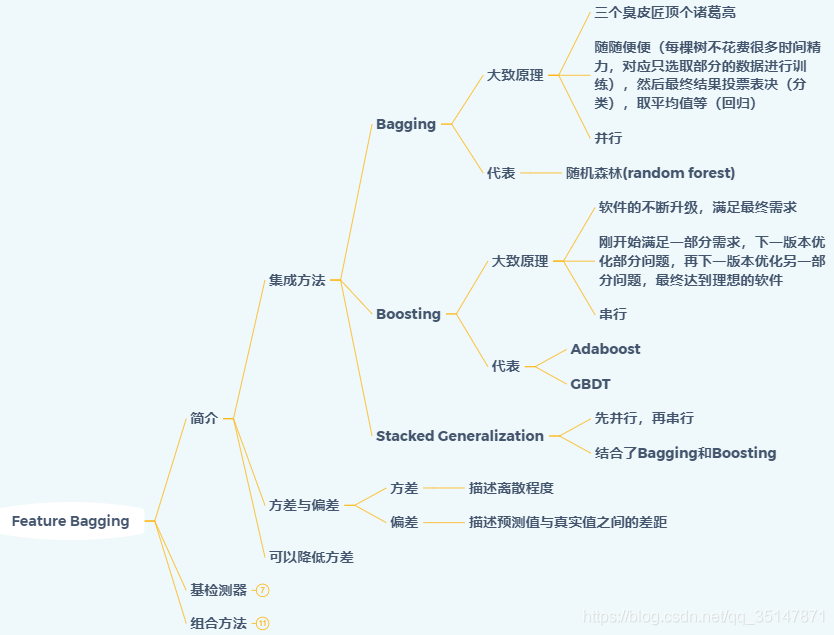
1.2.2 基檢測器
主要講述常用演算法以及通用演算法流程

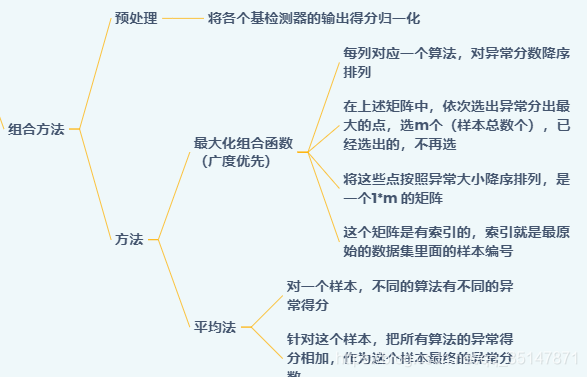
1.2.3 組合方法
主要有兩種方法,第一種是廣度優先的方法,第二種是平均法,第一種理解起來比較有難度,建議看原文,在本文最后附件里面,
- 主要就是,某種演算法算出所有樣本的例外得分之后,是進行了排序的
- 然后依次選出例外得分最大的樣本(已經選出的,不再選),直到選出資料集樣本數目個樣本,也相當于把所有演算法得出的例外分數,進行降序排列,依次選擇,選過的樣本不再選,每一個例外得分都會對應一個例外的索引,索引到原始資料集里面的對應樣本,
- 字符有時候容易搞混,建議帶入具體數值進行理解
1.3 Isolation Forests
1.3.1 簡介

1.3.2 原理

路徑的計算,是在經過多少次分類的次數+調整值,調整值是如果樹的高度達到上限了,那么這個調整值代表的就是還沒有建立的樹所對應的路徑,
1.3.3 步驟

2.練習
2.1 feature bagging
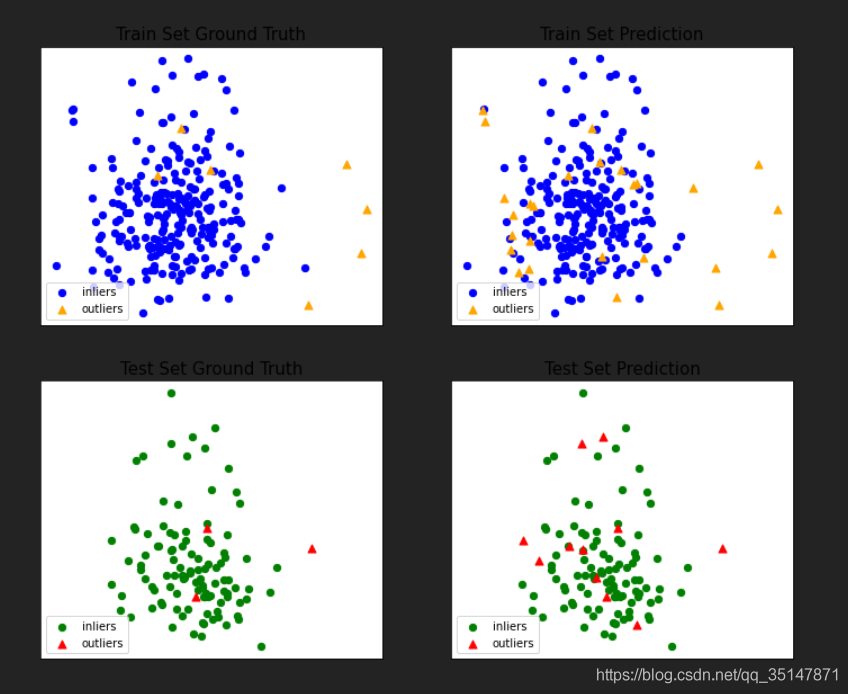
畫圖均采用前兩個維度的資料,因此,有的圖,可能有的奇怪
2.1.1 Generate data
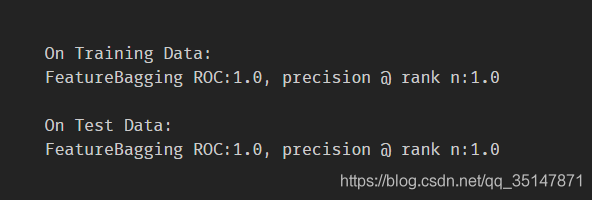
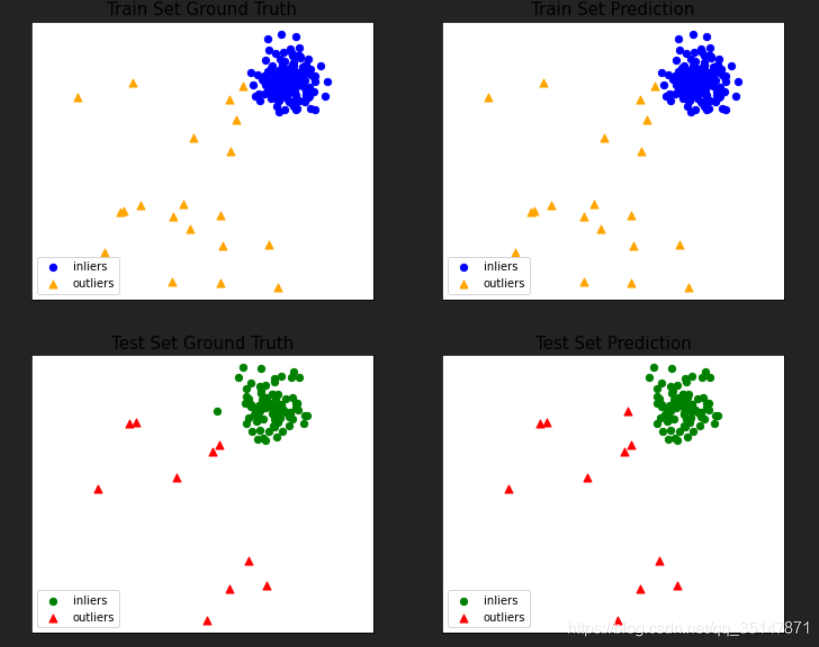
2.1.2 breast cancer(10 abnormal)
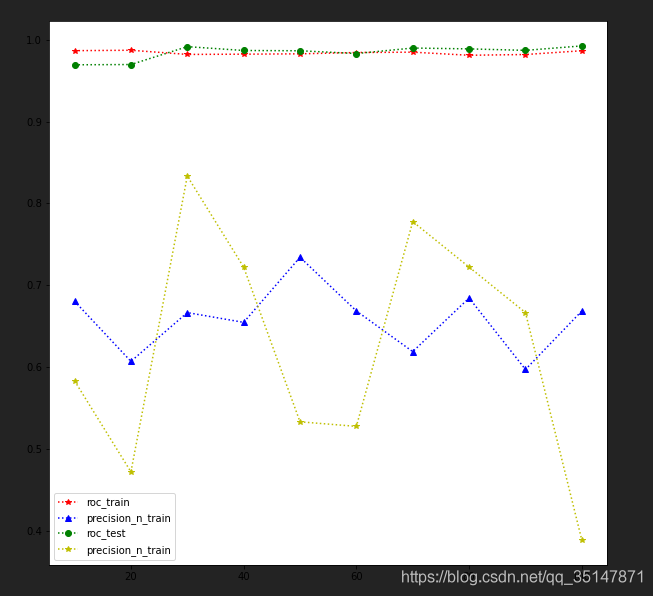
提高基分類器的個數,可以提高測驗集的精度,之前大概0.6左右,現在可以0.8,偶爾1.0(極端情況,測驗集就一個例外值),但是再增高的話,精度反而降低了
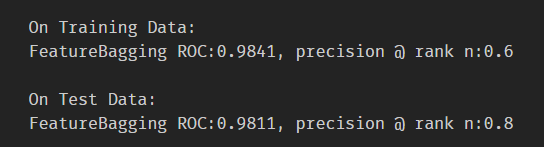
n_estimators 從10到100,間隔10,roc,precision @ n,在訓練集和測驗集上面的表現,每個estimator,做三次實驗,取平均值,發現取值為30的時候是precision @ n最好的時候,這次結果錯誤的原因是,沒有控制train_test_split的random_state,控制好以后,結果大致是穩定的,n_estimator=100做了兩次,小資料集,受到random_state的應先還是比較大的,尤其是例外的個數很少的時候,受到n_estimator影響較小,
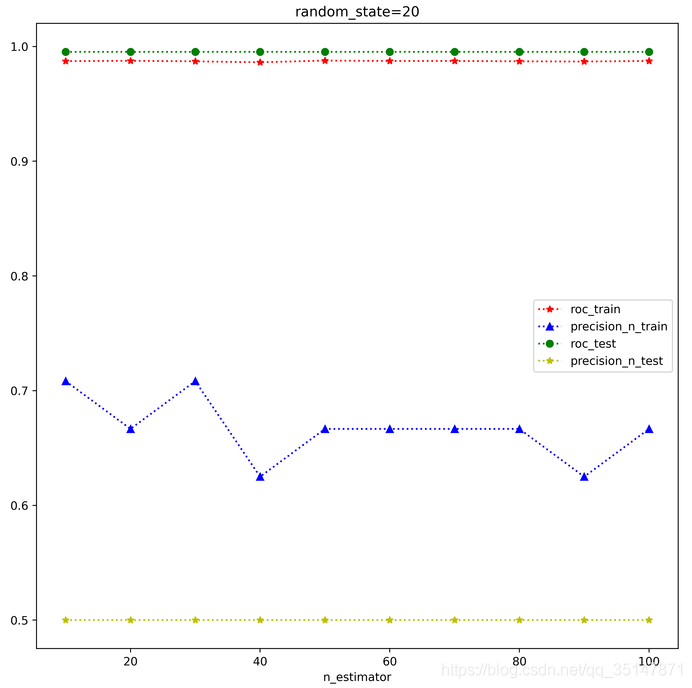
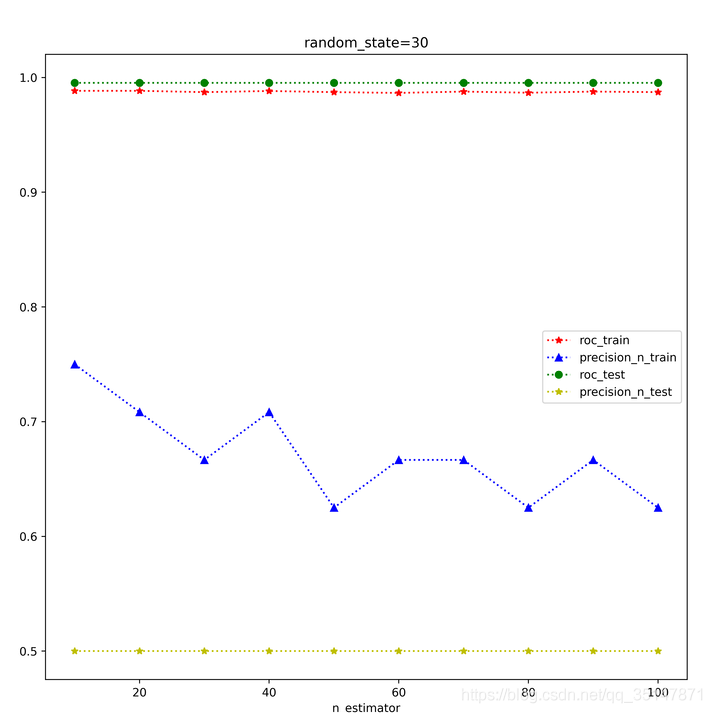
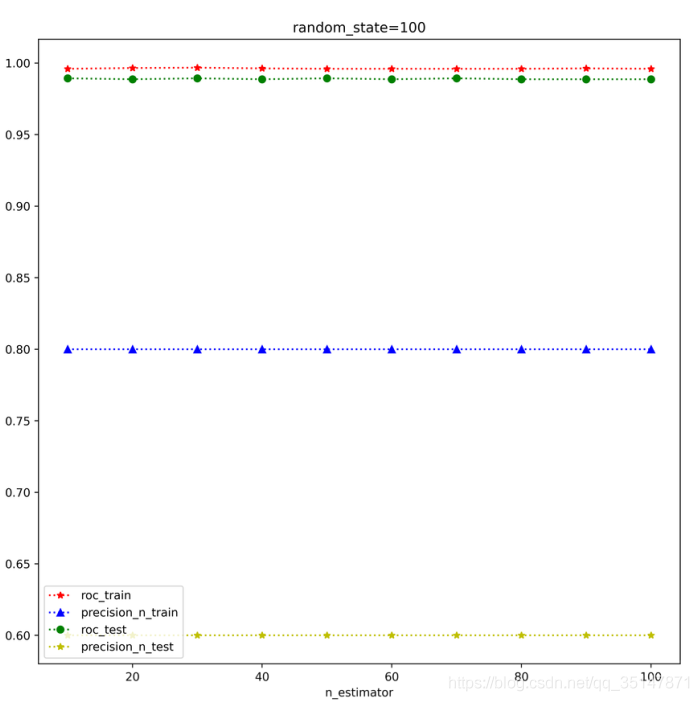
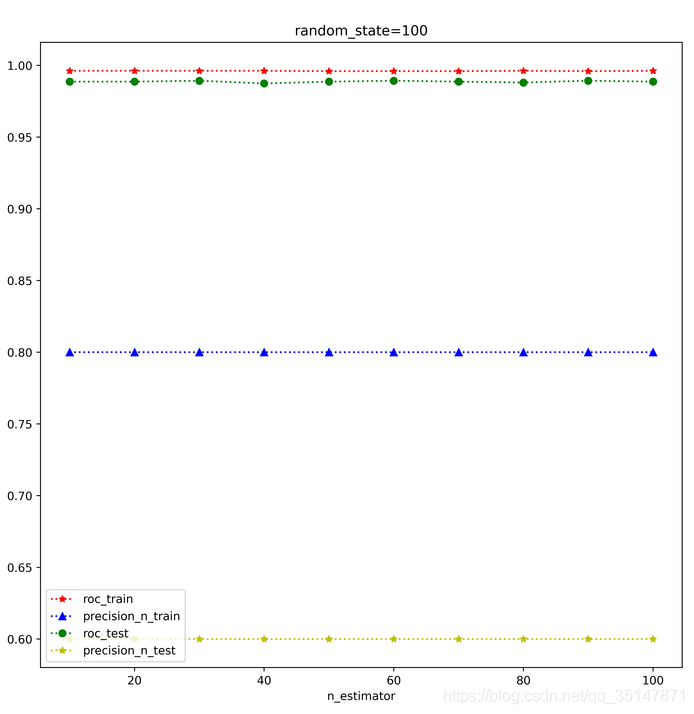
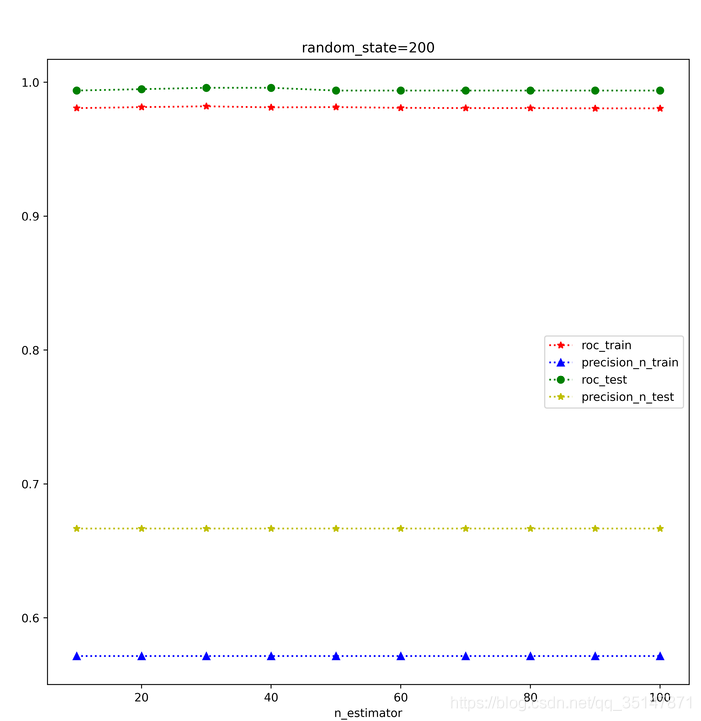
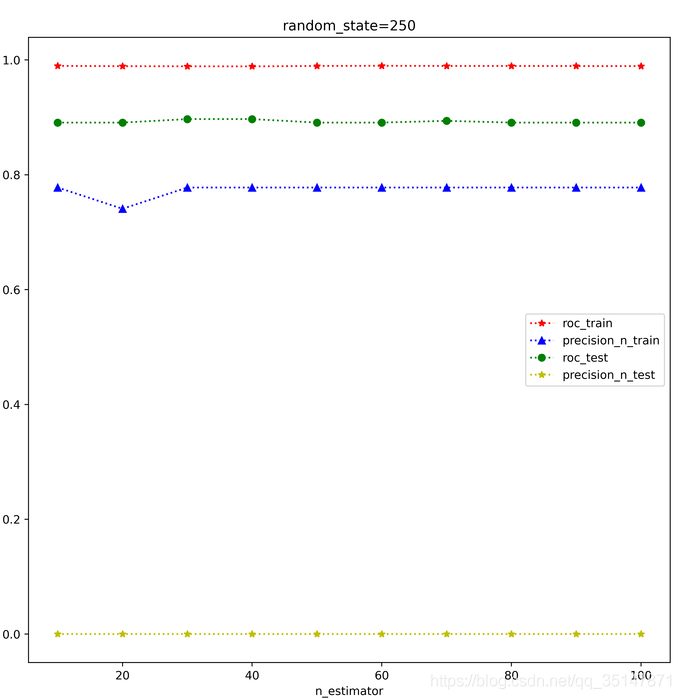
2.1.3 癲癇資料集
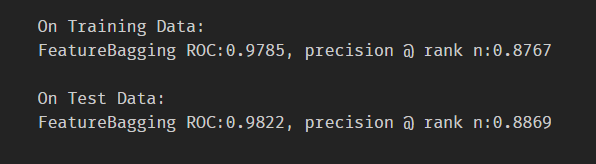
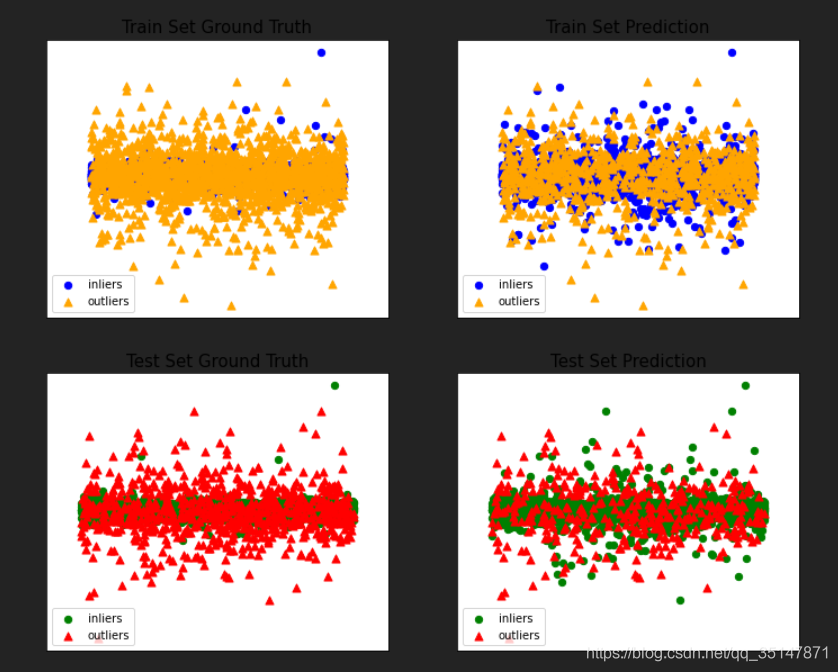
2.2 Isolation Forests
2.2.1 generate data
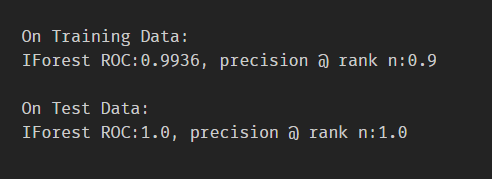
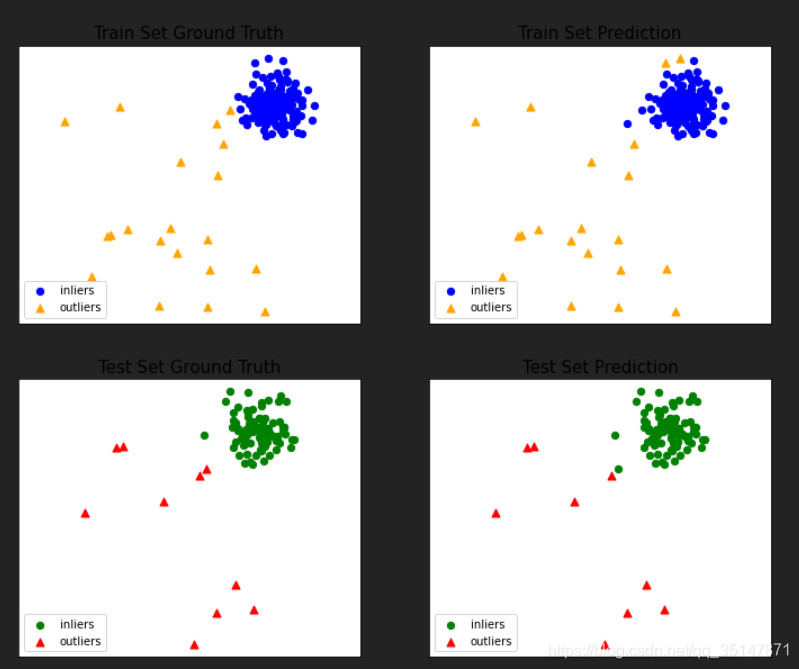
2.2.2 breast cancer(10 abnormal)
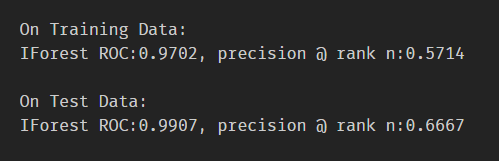
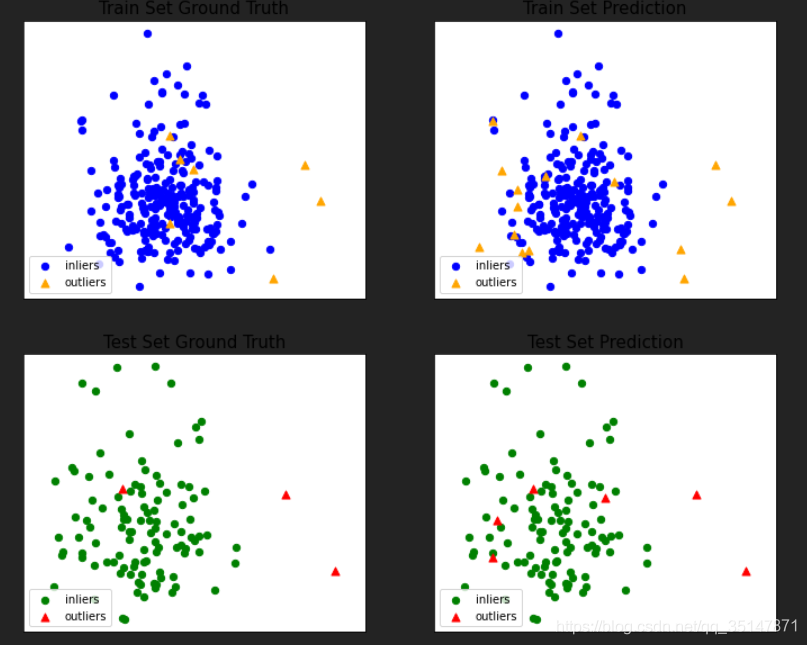
2.2.3癲癇資料集
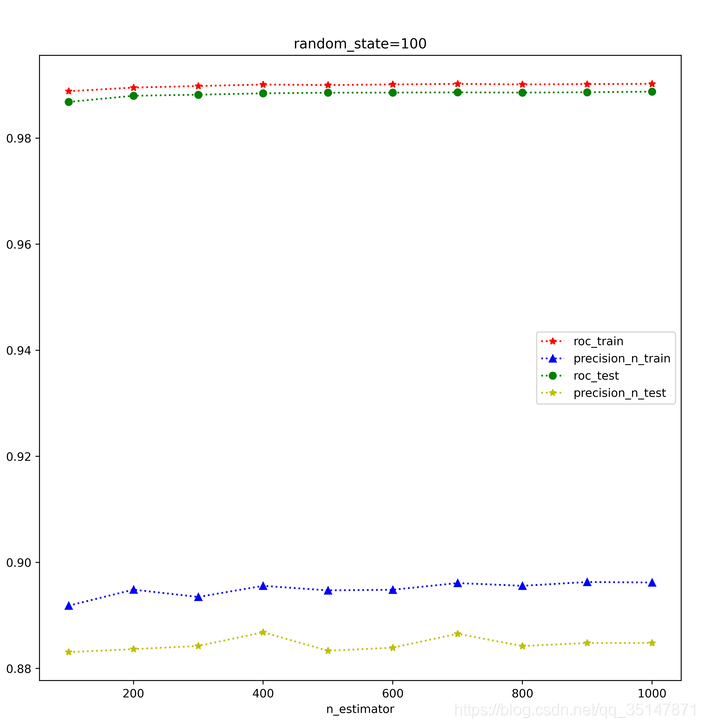
n_estimators影響很小,從100-1000間隔100
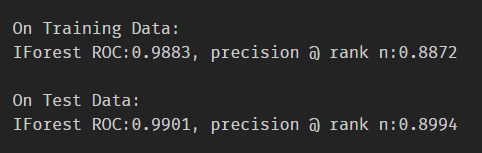
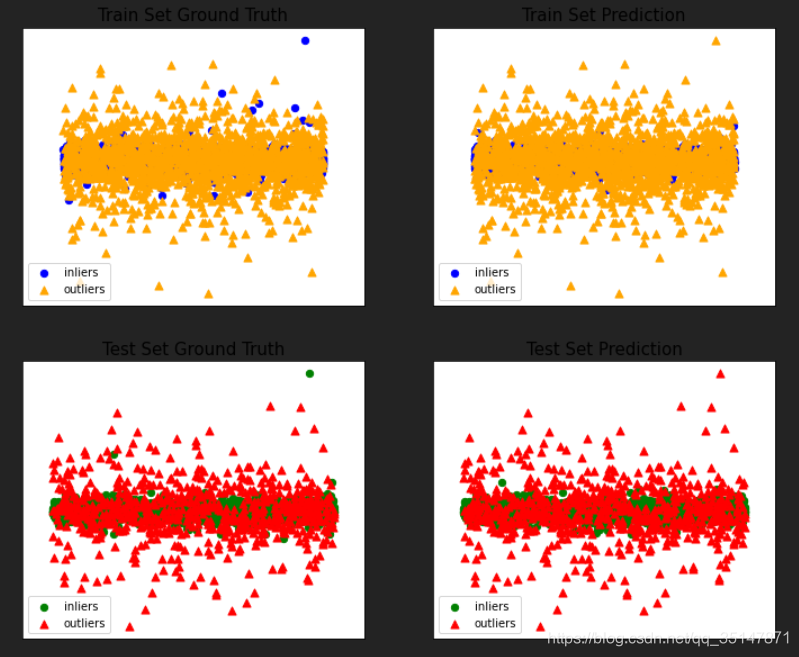
2.3 思考題:feature bagging為什么可以降低方差?
因為變數之間具備相關性,不是完全獨立的
為什么說bagging是減少variance,而boosting是減少bias? - 過擬合的回答 - 知乎
2.4 思考題:feature bagging存在哪些缺陷,有什么可以優化的idea?
超高維度的話,有些維度,也可能是一直不被選中的;
從d/2到d-1之間不再是隨機的了,采用二分法進行
評估的演算法,沒有規定,
可以使用不同型別的演算法,也可以針對資料集,采取某些演算法
3.附件
特征選擇原文(英文)
孤立森林原文(英文)
思維導圖.xmind
feature bagging jupyter 代碼
iForest jupyter 代碼
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/253156.html
標籤:區塊鏈
上一篇:FIL幣到底是買礦機還是屯幣?Filecoin挖礦亮點在哪里?如何評估挑選挖礦設備/IPFS礦商?
下一篇:解決git clone出現“error: RPC failed; result= 18,HTTP code = 20018. 00 KiB/s”報錯的五個網址(個人用)