文章目錄
- 1、ABSTRACT AND INTRODUCTION
- 2、ARCHITECTURE AND OPERATION
- 2.1 FL operation in Block FL
- 2.2 Blockchain operation in Block FL
- 2.3 One-epoch Block FL operation
- 3、END-TO-END LATENCY ANALYSIS
- 3.1 One-epoch Block FL latency model
- 3.2 Latency optimal block generation rate
- 4、NUMERICAL RESULTS AND DISCUSSION
- 5、REFERENCES
基于區塊鏈的聯邦學習體系架構
1、ABSTRACT AND INTRODUCTION
機器模型:
缺點:
1、 需要中央協調
?易受集中服務器故障影響
? 由此產生不準確的全域模型更新扭曲了區域模型更新,可能導致整個訓練崩潰
👇🏻👇🏻👇🏻
這就需要分布式FL體系結構
2、 需要大量的資料樣本,并且需要與其他設備進行資料樣本交換
?在沒有提供與樣本數量成比例的適當補償的情況下,這種設備不太愿意與擁有少量資料樣本的其他設備聯合
?補償機制帶來的副作用, 一些不誠實的設備偽造具有比實際樣本大小更多的資料樣本,從而在FL產生不準確的全域模型更新
👇🏻👇🏻👇🏻
為了解決私有交換和獎勵機制的問題,利用區塊鏈而不是中央物體
作者提出:block-chained federated learning(BLOCK FL)
?移動設備的本地學習模型更新通過利用區塊鏈來交換和驗證
?無中央協調通過交換本地資料來訓練每個設備的本地模型
challenges
※ 本地資料樣本歸每個設備所有
交換時對其他設備保密原始資料樣本
※本地設備的獎勵系統
具有大量資料樣本的設備對全域模型訓練更大,同時消耗更多的計算能力和時間
Google’FL Vanilla FL
? 每個設備可以交換其本地模型更新,即學習模型的權重和梯度引數
比原始資料模型更加注重隱私
? global model:通過中央服務器聚集所有區域模型更新并取總體平均值,產生全域模型更新
? local model:每個設備下載全域模型更新,并計算其下一個區域更新直到全域模型訓練完成
eg:通過分布式隨機梯度下降(SGD)
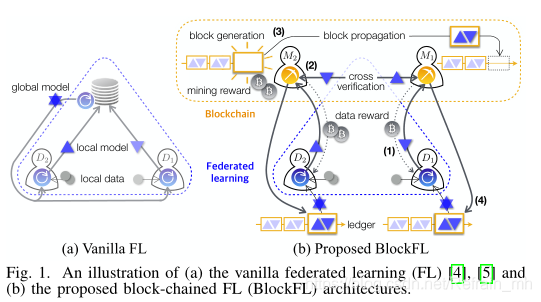
Block FL架構
?Block FL的邏輯結構由移動設備和礦工組成,礦工可以是隨機選擇的設備,也可以是獨立的節點,
?區塊鏈網路允許交換設備的本地模型更新,同時能夠驗證和提供他們相應的獎勵,
Block FL具體操作如下:
1、Block FL中每個設備計算本地模型更新并將其上傳到區塊鏈網路中與其關聯的礦工
同時作為回報,從礦工接受與其資料樣本數量成比例的資料獎勵
2、礦工交叉驗證所有本地模型更新,然后運行作業證明演算法(pow)
3、一旦礦工完成pow,它生成一個塊,在該塊中記錄已驗證的本地更新,并從區塊鏈網路中接收采礦獎勵
4、最終,存盤聚合本地模型更新的生成塊被添加到區塊鏈,也稱為分布式賬本,并由設備下載,每個設備從最新的塊計算全域模型更新,這是下一個本地模型更新的輸入,
※Block FL全域模型更新是在每個設備本地計算的
因此,礦工/設備在全域模型更新中的故障不會影響其他設備的區域全域模型更新,從而確保整體訓練的健壯性,
但與普通FL相比,Block FL需要支付區塊鏈網路產生的額外延遲
為了解決這個問題,Block FL的端到端的延遲模型是通過考慮FL模型和區塊鏈操作期間的通信,計算和POW延遲來制定,通過調整區塊生成速率(即POW難度),最大限度減少延遲
2、ARCHITECTURE AND OPERATION
2.1 FL operation in Block FL

Di的本地模型更新被上傳到其相關聯的礦工Mi
If ?礦工在物理上與設備相同 M=D,否則M!=S
Then ?通過礦工驗證和交換本地模型更新的總數ND
Finally 聚集的本地模型更新從每個礦工下載到其相關聯的設備
方便起見,分布式模型訓練集以并行方式解決線性回歸問題

為了解決上述回歸問題,與[4]中谷歌的普通FL一樣
(1)設備Di學習模型通過隨機方差消減梯度演算法(SVRE) 用其資料樣本所設定的Si進行局本訓練
(2)使用分布式擬牛頓法(DANE)方法聚合所有設備的區域模型更新,產生全域模型更新
2.2 Blockchain operation in Block FL
?在BlockFL的區塊鏈網路中,區塊及其M中礦工的驗證旨在通過分布式帳本真實是的交換本地模型更新,
賬本中的每個塊都分為它的區塊頭和區塊體部分,
在傳統的區塊鏈結構中[9],區塊體部分包含一個經過驗證的交易串列,在BlockFL中,區塊體存盤了D中設備的本地模型更新,即為??????
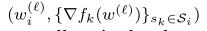
?按照[7]的結構,區塊頭部分包含前一個塊的指標資訊,塊生成率λ和POW演算法的輸出值(nonce),
為了存盤所有設備的本地模型更新,每個塊大小設為
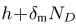
↓ ?↓
頭部和模型更新大小
?每一個礦工都有一個候選塊,該塊按照到達的順序提供了來自其關聯設備或者其他礦工的本地模型更新,
?填充程序一直持續到它到達塊的大小或者每個周期開始測量的最大等待時間,簡單起見,假設最大等待時間足夠長,以便每塊總是被所有設備的本地模型更新填滿,
?之后,按照PoW演算法 [7],礦工繼續生成亂數,直到該亂數nonce變得小于目標值,一旦礦工M1成功地找到這個亂數,它的候選塊就被允許生成為新塊
?如圖2所示,這里,可以通過調整pow難度來控制塊生成速率λ,
? eg:pow目標值越低,λ越小,
?接下來,將生成的塊傳播給所有其他礦工,以便同步他們所有的分布式帳本,為此,正如在[7]中所做的那樣,所有接收生成塊的礦工都被迫停止他們的PoW操作,并將生成塊添加到他們的本地賬本中,
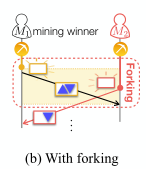
?如果另一個礦工M2在第一個生成的塊的傳播延遲內成功地生成了它的區塊,那么一些礦工可能會錯誤地將第二個生成的塊添加到它們的本地賬本中,這被稱為forking(分叉),在BlockFL中,forking使一些設備將不正確的全域模型更新應用到它們的下一個區域模型更新,forking頻率隨著λ和塊傳播延遲的增加而增加,其級訓會產生額外的延遲,
?除了本地模型更新交換操作外,區塊鏈網路還對設備的資料樣本提供獎勵,對礦工的驗證程序提供獎勵,分別稱為資料獎勵和采礦獎勵,設備Di的資料獎勵從其關聯的礦工接收,其數量與資料樣本大小Ni成正比,當礦工Mj生成一個塊時,它的采礦獎勵由區塊鏈網路獲得,就像傳統的區塊鏈結構[7]一樣,
采礦獎勵的數量與其所有關聯設備的資料樣本總量成正比,即
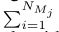
?其中NMj表示與礦工 Mj關聯的設備數量,這促使礦工收集更多的本地模型更新,同時補償他們的資料獎勵支出,
?作為獎勵系統的一個副作用,一些不誠實的設備可能通過夸大用于本地模型資料的實際樣本大小或者在不進行本地學習計算的情況下生成任意的本地模型更新來欺騙礦工,礦工在將本地模型更新存盤在其候選塊中之前,會驗證真實的本地更新,
?驗證是通過將樣本大小Ni 與其相應的本地計算時間Tloacl進行比較來執行的,這被認為是真實的,在例如Intel的SGX技術[14]下,經過時間的證明[13],
2.3 One-epoch Block FL operation
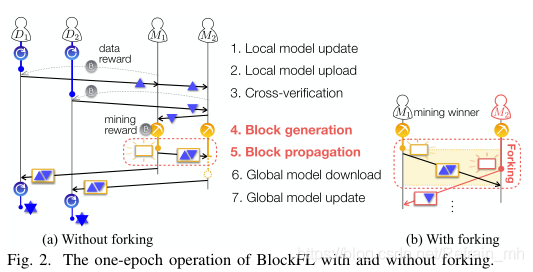
設備Di在每一輪周期Block FL的7個步驟
0.初始化:初始引數從預定義的范圍均勻隨機選擇,對于一個常數,區域模型和全域模型權重
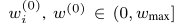
以及全域梯度
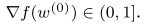
1.本地模型更新:設備Di用Ni的迭代次數計算(2)
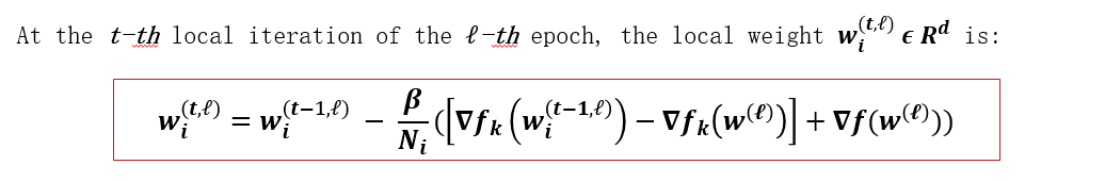
2.本地模型上傳:設備Di 與礦工Mi 均勻隨機關聯
If M=D, 則從 M\Di 中挑選Mi
設備上傳本地模型更新 及相應的本地計算時間Tlocal,i 到其相關聯的礦工
3. 交叉驗證:礦工廣播從其相聯設備獲得的本地模型更新,同時,礦工按照到達的順序驗證從他們相關聯的設備或其他礦工接收到的本地模型更新,
4.
如果區域模型計算時間Tlocal,i與資料樣本大小Ni成正比, 區域模型更新的真實性得到驗證,
已驗證的本地模型更新記錄在礦工的候選區塊中,直到其達到區塊大小 或最大等待時間Twait,
5. 塊生成:每個礦工運行POW,直到找到亂數nonce或從另一個礦工收到生成塊,
6. 塊傳播:首次找到nonce的礦工的候選塊被作為新塊并傳播給其他礦工,礦工從區塊鏈網路上獲得挖礦獎勵(mining reward),為了避免鏈分叉,一旦每個礦工接收到新的塊或當每個礦工沒有檢測到分叉事件時,就發送一個ACK確認信號,包括是否發生forking,
每個礦工等待,直到收到所有礦工的確認信號;否則,操作從步驟1重新開始,
7. 全域模型下載:設備Di從其相關聯的礦工下載生成的區塊
8. 全域模型更新:設備Di在(3)中通過使用存盤在生成區塊的聚合區域模型更新來計算全域模型更新,
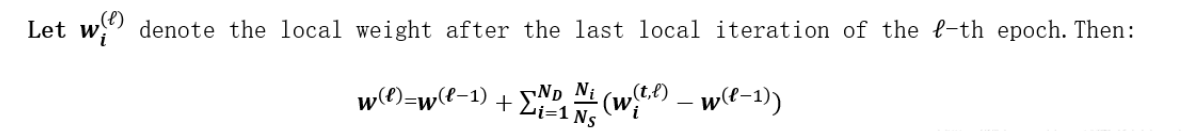
當全域權重W 滿足
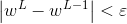
周期程序停止,
?集中式FL結構容易收到服務器故障的影響,以至于扭曲所有設備的全域模型更新,
?與此相比,Block FL中每個設備都在本地計算它的全域模型更新,因此對于取代服務器物體的礦工的故障來說更加健壯,
3、END-TO-END LATENCY ANALYSIS
3.1 One-epoch Block FL latency model

3.2 Latency optimal block generation rate
單周期延遲運算式,目標是為了推匯出最優塊生成速率 λ *,使設備D0第l 個周期pow程序的平均延遲最小,

?pow程序會影響塊生成延遲,快傳播延遲以及分叉forking發生的數量,這些因礦工中成功者M0相互依賴,
?為了避免上述困難,所有礦工通過調整Twait同步啟動他們pow行程
使得
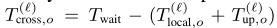
?在這種情況下,即使是較早完成交叉驗證的礦工也會一直等待到Twait,從而提供了性能的下界,即延遲的上界,
4、NUMERICAL RESULTS AND DISCUSSION
用數值方法評估了所提出的Block FL的平均學習完成延遲
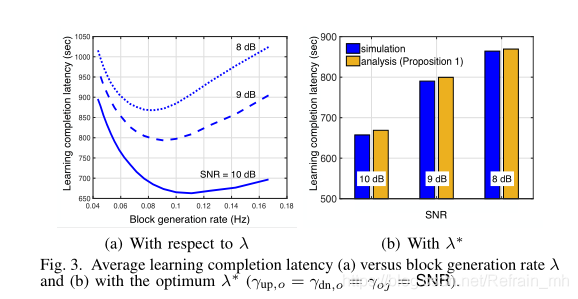
圖3顯示了塊生成速率 λ 對Block FL 的平均學習完成延遲的影響
?在圖3-a中,我們觀察到延遲影像在 λ 上呈凸形,并且隨著信噪比(SNR)的增加而減少,
?在圖3-b中,對于最佳塊生成速率 λ *,從 Proposition 1中獲得的最小平均學習完成延遲時間總是比在沒有近似情況下模擬的最小延遲時間長1.5%,
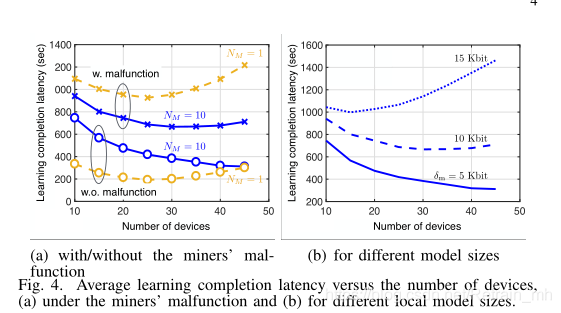
圖4分別說明了BlockFL在礦工和設備的數量NM和ND方面的可擴展性,
?
- 在圖4-a中,計算了在NM= 1和NM= 10條件下,無論礦工是否發生故障,平均學習完成延時,
- 故障時可以通過添加高斯噪聲N(?0.1,0.01)到每個礦機的本地模型更新的聚合概率為0.5來捕捉,
- 在沒有任何故障的情況下,礦工較多時會由于它們的交叉驗證和塊傳播延遲的增加而增加延遲,
- 在礦工的故障情況下,這一點并不總是成立,
- 在BlockFL中,每個礦工的故障只會扭曲其關聯設備的全域模型更新,這種扭曲可以通過與礦工正常作業的其他設備聯合來恢復,由于這個原因,礦工數量較多時能實作更短的延遲,正如觀察到的故障時NM=10,
?更多的設備數量ND可能由于使用了更多的資料樣本而降低了學習完成延遲,
?與此同時,增加了每個區塊的大小,即通信有效載荷,從而導致更高的塊交換延遲,從而導致相對于ND的延遲模型呈凸形,
?在這方面,適當的設備選擇有可能減少延遲,如[5],[10]所研究的,
?最后,從圖4-b可以看出,隨著每個設備的本地模型尺寸δm的增加,延遲增加,
5、REFERENCES
[1] P . Popovski, J. J. Nielsen, C. Stefanovic, E. de Carvalho, E. G. Str?m,
K. F. Trillingsgaard, A. Bana, D. Kim, R. Kotaba, J. Park, and R. B.
S?rensen, “Wireless Access for Ultra-Reliable Low-Latency Communi-
cation (URLLC): Principles and Building Blocks,” IEEE Netw., vol. 32,
pp. 16–23, Mar. 2018.
[2] M. Bennis, M. Debbah, and V . Poor, “Ultra-Reliable and Low-Latency
Wireless Communication: Tail, Risk and Scale,” [Online]. Available:
https://arxiv.org/abs/1801.01270.
[3] J. Park, D. Kim, P . Popovski, and S.-L. Kim, “Revisiting Frequency
Reuse towards Supporting Ultra-Reliable Ubiquitous-Rate Communica-
tion,” in Proc. IEEE WiOpt Wksp. SpaSWiN, Paris, France, May 2017.
[4] J. Koneˇ cn′ y, H. B. McMagan, D. Ramage, “Federated Optimization:
Distributed Machine Learning for On-Device Intelligence,” [Online].
Available: https://arxiv.org/abs/1610.02527.
[5] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A.y Arcas,
“Communication-Efficient Learning of Deep Networks from Decentral-
ized Data,” in Proc. AISTATS, F ort Lauderdale, FL, USA, Apr. 2017.
[6] J. Chen, R. Monga, S. Bengio, and R. Jozefowicz, “Revisiting Dis-
tributed Synchronous SGD,” in Proc. ICLR, San Juan, Puerto Rico,
May 2016.
[7] S. Nakamoto, “Bitcoin: A Peer-to-Peer Electronic Cash System,” [On-
line]. Available: https://bitcoin.org/bitcoin.pdf.
[8] C. Decker, and R. Wattenhofer, “Information Propagation in the Bitcoin
Network,” in Proc. IEEE P2P , Trento, Italy, Sep. 2013.
[9] S. Samarakoon, M. Bennis, W. Saad, and M. Debbah, “Distributed
Federated Learning for Ultra-Reliable Low-Latency V ehicular Commu-
nications,” [Online]. Available: https://arxiv.org/abs/1807.08127.
[10] T. Nishio, R. Y onetani, “Client Selection for Federated Learning
with Heterogeneous Resources in Mobile Edge,” [Online]. Available:
https://arxiv.org/abs/1804.08333., 2018.
[11] R. Johnson and T. Zhang, “Accelerating Stochastic Gradient Descent
Using Predictive V ariance Reduction,” in Proc. NIPS, Lake Tahoe, NV ,
USA, Dec. 2013.
[12] O. Shamir, N. Srebro, and T. Zhang, “Communication-Efficient Dis-
tributed Optimization Using An Approximate Newton-Type Method,”
in Proc. ICML, Beijing, China, Jun. 2014.
[13] L. Chen, L. Xu, N. Shah, Z. Gao, Y . Lu, and W. Shi, “On Security
Analysis of Proof-of-Elapsed-Time,” in Proc. SSS, Boston, MA, USA,
Nov. 2017.
[14] V . Costanand, and S. Devadas, “Intel SGX Explained,” Cryptologye
Print Archive Report 2016/086, 2016.
[15] 3GPP TS 36.300 v13.4.0, “E-UTRA and E-UTRAN; Overall Descrip-
tion; Stage 2,” Tech. Rep., 2016.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/254810.html
標籤:區塊鏈