國際著名的咨詢公司Gartner在2013年總結出了一套資料分析的框架,資料分析的四個層次:描述性分析、診斷性分析、預測性分析、處方性分析,
Gartner于2020年中給出預測,到2024年底,75%的企業機構將從AI試點轉為AI運營,同期,Gartner發布了資料與分析領域的十大技術趨勢,首先映入眼簾的是:更智能、更高速、更負責的AI,也指出了儀表板的衰落,更青睞上層次和實用化的決策智能,
1. 前言
我們在設計資料分析產品和資料可視化的時候,依據是什么?怎樣設計資料分析產品才能給用戶更多的業務支撐?我們做趨勢預測、精準識別目的是什么?
最近,我有些感悟分享與讀者探討、研究,
對于設計資料分析產品和資料可視化,我們首先想到的是需求,然后是業務機理,但是,在大資料、新一代人工智能高速發展的今天,對比Gartner給出資料分析咨詢意見,我們不應拘泥于當前的業務場景,業務創新也可以通過新技術引領,
我們回到資料分析產品和資料可視化設計,除了需求和業務機理以外,我們不妨以金字塔思維模型來構建這樣的場景,
一、目的
我們的目的是實作經濟發展和利潤,解決未來或當下的問題,比如新零售業務核心是圍繞客戶展開,解決客戶發展和流速問題,是企業發展和利潤的基石,
二、分析需求和識別待解決問題
分析需求是深入業務機理,重塑業務模型,以發展的眼光識別問題,解決問題,仍以新零售客戶發展為例,客戶流失是難以解決的問題,要解決客戶流失問題,需要我們重塑客戶全生命周期管理模型,識別問題機理和影響因素,
三、以預設或假設結論先行
我們以需求和待解決問題為基準,經過理論聯系實際,設定解決問題目標,如果仍以客戶流失問題為基準,并按公司現狀和發展,我們設定客戶流失率控制目標是20%,挽回率為70%,預測準確度為80%等,
為此,我們先借鑒國際Kaggle大賽電信客戶流失題目為例,其資料為“WA_Fn-UseC_-Telco-Customer-Churn”,參照推演結論,
四、以上統下,逐層展開
我們有了結論目標,接著就是落地證明結論,分層分類展開,比如仍以客戶流失問題為例,先通觀全域,我們已經能做到預測客戶流失,預測客戶流失為26.54%,預測模型準確率達到80%,我們據此分類展開模型的影響因素分析,這也是資料分析、資料可視化內容,例如根據模型重要影響因素和相關性,給出個人特征、行為特征、服務特征三大類,
分層子觀點如下:
1、以動態規劃優化策略,通過優惠券方式降低流失客戶的客戶單價,實作減少流失客戶;
2、以客戶生命周期的時間序列預測客戶流失預警;
3、流失客戶的月消費金額(客單價)、在網時長等因素對客戶流失影響較大,
五、給出解決措施,逐層分解,體現資料分析更智能,
2. 電信客戶流失案例
2.1. 背景
電信行業關于用戶留存有這樣一個觀點[2],如果將用戶流失率降低5%,公司利潤將提升25%-85%,如今,高居不下的獲客成本讓電信運營商遭遇“天花板”,甚至陷入獲客難的窘境,隨著市場飽和度上升,電信運營商亟待解決增加用戶黏性,延長用戶生命周期的問題,因此,電信用戶流失分析與預測至關重要,因此做好“用戶流失預測分析”可以:
1、降低營銷成本,業界通用經驗,“新客戶開發成本”是“老客戶維護成本”的5倍,
2、獲得更好的用戶體驗,并不是所有的增值服務都可以有效留住客戶,
3、獲得更高的銷售回報,可以識別價格敏感型客戶和非價格敏感性客戶,
2.2. 客戶資料集及其流失預測分析
2.2.1. 資料集
| 欄位名稱 | 說明 | 資料解釋 |
|---|---|---|
| customerID | 用戶ID | |
| gender | 性別 | Female & Male |
| SeniorCitizen | 老年人 | 1表示是,0表示不是 |
| Partner | 是否有配偶 | Yes or No |
| Dependents | 是否經濟獨立 | Yes or No |
| tenure | 客戶已使用月份數 | 0-72月,0為新開戶 |
| PhoneService | 是否開通電話服務業務 | Yes or No |
| MultipleLines | 是否開通了多線業務 | Yes 、No or No phoneservice |
| InternetService | 是否開通互聯網服務 | No, DSL數字網路,fiber optic光纖網路 |
| OnlineSecurity | 是否開通網路安全服務 | Yes,No,No internetserive |
| OnlineBackup | 是否開通在線備份業務 | Yes,No,No internetserive |
| DeviceProtection | 是否開通了設備保護業務 | Yes,No,No internetserive |
| TechSupport | 是否開通了技術支持服務 | Yes,No,No internetserive |
| StreamingTV | 是否開通網路電視 | Yes,No,No internetserive |
| StreamingMovies | 是否開通網路電影 | Yes,No,No internetserive |
| Contract | 簽訂合同方式 | 按月,一年,兩年 |
| PaperlessBilling | 是否開通電子賬單 | Yes or No |
| PaymentMethod | 付款方式 | bank transfer,credit card,electronic check,mailed check |
| MonthlyCharges | 月費用 | |
| TotalCharges | 總費用 | |
| Churn | 該用戶是否流失 | Yes or No |
2.2.2. 資料預處理與特征提取
1、資料缺失處理
經過觀察,發現這11個用戶‘tenure’(入網時長)為0個月,推測是當月新入網用戶,根據一般經驗,用戶即使在注冊的當月流失,也需繳納當月費用,因此將這11個用戶入網時長改為1,將總消費額填充為月消費額,符合實際情況,
#'TotalCharges'存在缺失值,強制轉換為數字,不可轉換的變為NaN
self.CData['TotalCharges']=pd.to_numeric(self.CData['TotalCharges'], errors='coerce') #astype('float64')
#將總消費額填充為月消費額
self.CData['TotalCharges'] = self.CData[['TotalCharges']].apply(lambda x: x.fillna(self.CData['MonthlyCharges']),axis=0)
#查看是否替換成功
print(self.CData[self.CData['tenure']==0][['tenure','MonthlyCharges','TotalCharges']])
2、特征編碼與特征增維
觀察資料型別,除了“tenure”、“MonthlyCharges”、“TotalCharges”是連續特征外,其它都是離散特征,
- 對于連續特征,采用標準化方式處理;
- 對于離散特征,特征之間沒有大小關系,采用one-hot編碼;
- 對于離散特征,特征之間有大小關聯,則采用數值映射,例如這的Yes與No,隱含有和無,既0與1的關系,
Pandas技術方案:
- pd.get_dummies()就是把離散字符或者其他型別編碼變成一串數字向量(縱向轉為橫向的資料列),也就是所謂的one-hot編碼,資料增維,
- pd.factorize()就是把離散字符或者其他型別編碼變成一列連續數字,通常轉變為0、1,或者,連續有一定意義的,
Cols = [c for c in self.CData.columns if self.CData[c].dtype == 'object' or c == 'SeniorCitizen']
Cols.remove('Churn')
# 對于離散特征,特征之間沒有大小關系,采用one-hot編碼;特征之間有大小關聯,則采用數值映射,
for col in Cols:
if self.CData[col].nunique() == 2:
self.CData[col] = pd.factorize(self.CData[col])[0]
else:
self.CData = pd.get_dummies(self.CData, columns=[col])
self.CData['Churn']=self.CData['Churn'].map({'Yes':1,'No':0})
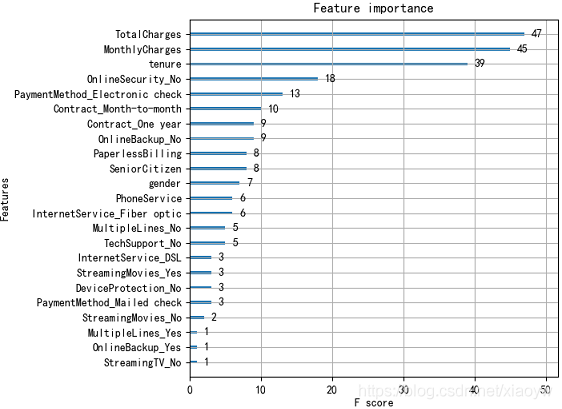
2.2.3. 影響流失特征重要程度排序
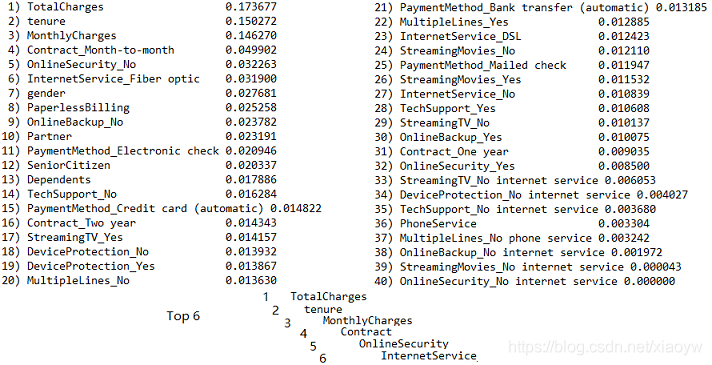
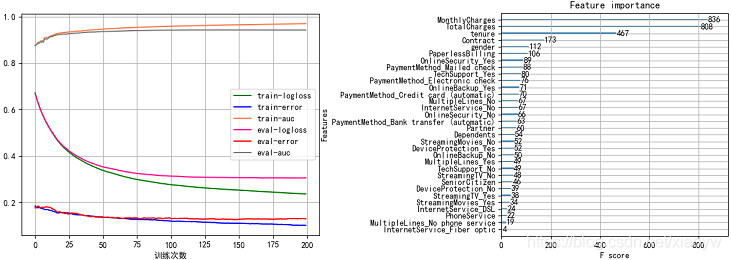
資料集原始特征為21個,在特征離散化及升維達到40個特征,通過隨機森林演算法擬合客戶流失,找出特征排序,實作代碼參考參考[3]詳細說明,
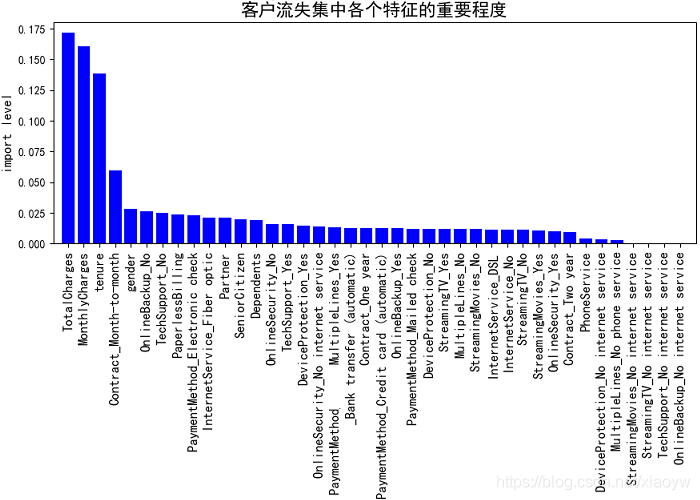
對排序結果數值進行分析,獲得重要前六項特征,以及考慮可以舍棄的特征,例如:PhoneService、StreamingTV等,
2.2.4. 與客戶流失相關特征分析
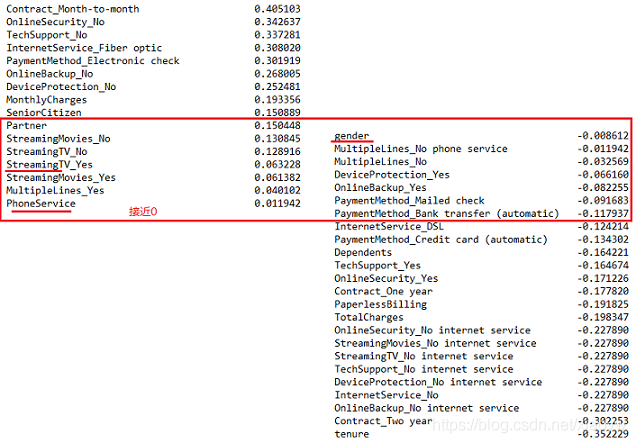
資料集原始特征為21個,在特征離散化及升維達到40個特征,通過皮爾森相關系數方法,找出能幫助理解特征和回應變數之間關系的方法,該方法衡量的是變數之間的線性相關性(詳細參加[3]說明),
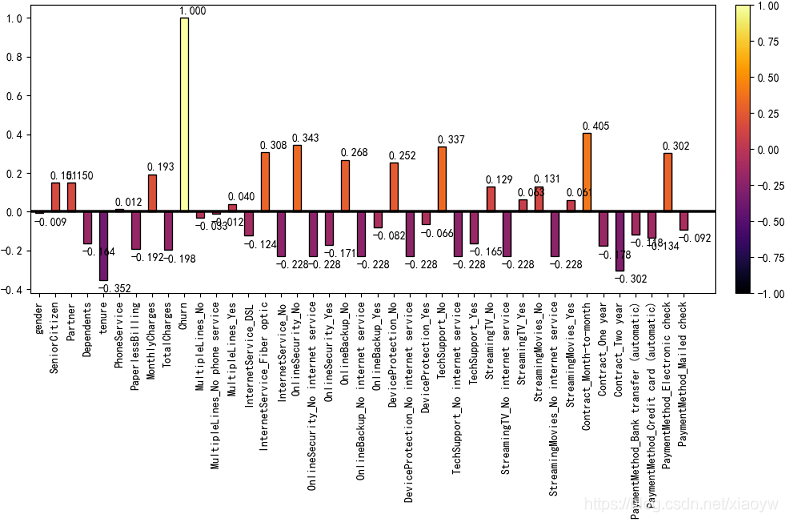
我們觀察關系系數接近于0的特征,有的和前面特征重要程度存在一定的穩合,例如PhoneService、StreamingTV,與流失關系系數接近0,
2.2.5. 資料不平衡處理
由于預測識別客戶流失屬于二分類的問題,而且流失占比較少,形成分類樣本不平衡問題,針對資料不平衡問題,采用欠采樣的方式進行處理,使用機器學習庫中的SMOTE,
pip install imblearn
#from imblearn.over_sampling import SMOTE
self.x_train,self.x_test, self.y_train, self.y_test = train_test_split(X,Y,test_size=0.3)
#利用SMOTE創造新的資料集 ,#初始化SMOTE 模型
oversampler=SMOTE(random_state=0)
#使用SMOTE模型,創造新的資料集
os_features,os_labels=oversampler.fit_sample(self.x_train,self.y_train)
#切分新生成的資料集
os_features_train, os_features_test, os_labels_train, os_labels_test = train_test_split(os_features, os_labels, test_size=0.2)
self.x_train,self.x_test, self.y_train, self.y_test = os_features_train, os_features_test, os_labels_train, os_labels_test
'''
#看看新構造的oversample資料集中0,1分布情況
#常用pandas的value_counts確認資料出現的頻率
os_count_classes = pd.value_counts(os_labels['Churn'], sort = True).sort_index()
os_count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")
plt.show()
'''
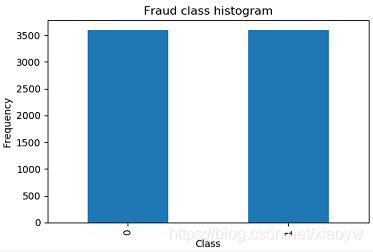
經過SMOTE欠采樣處理后,樣本資料集均衡,
基于均衡處理后的資料集進行預測,預測結果準確率由80%提升到87%(未做優化引數),
如果,使用原分離出來的30%樣本的做為測驗集,則模型預測準確率沒有得到明顯提升,為什么?
2.2.6. 結論
根據以上分析,我們可以大致得到高流失率用戶的特征:
- 用戶屬性:老年,未婚、沒有依賴關系;
- 服務屬性:開通光纖服務/光纖附加流媒體電視、電影服務;
- 行為屬性:在網時長小于一年,簽訂的合同期限較短,采用電子支票支付,使用電子賬單,月消費金額約在70-110元之間;
- 其它屬性對用戶流失影響較小,
2.3. 經驗總結
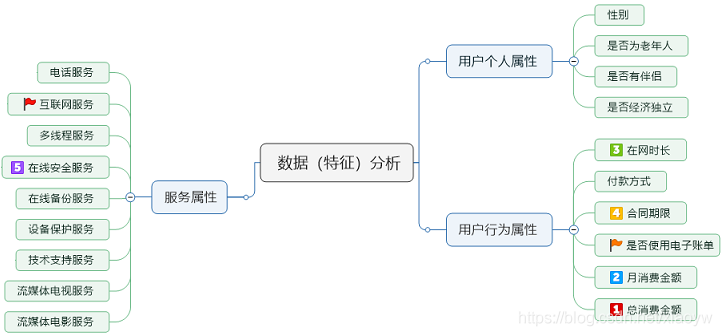
2.3.1. 特征分類層次化
總結預測客戶流失研究程序,我們將所有輸入原始特征分成了三個類別:客戶個人屬性、客戶行為屬性,客戶服務屬性,如下圖所示,分別對他們進行分析,
2.3.2. 特征離散化
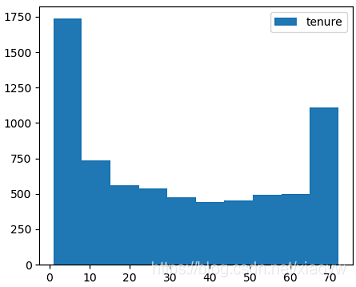
離散化后的特征對例外資料有更強的魯棒性,降低過擬合的風險,模型會更穩定,預測的效果也會更好,
例如“在網時長”特征,實際上的使用更多是表述時長的等級,我們參看如下資料分布直方圖,可以幾個級別,對比我們實際業務就是剛剛入網的客戶,多年的老客戶等等,
2.3.3. 離散特征 one-hot編碼
我們經常遇到資料特征,是對某些特征進行歸類管理,例如下圖的“付款方式”,每種付款方式都是獨立的,以是、否方式表示,而且有可能存在多種付款方式,對于這樣的特征我們應該采用one-hot方式編碼,相當于給資料集升維,
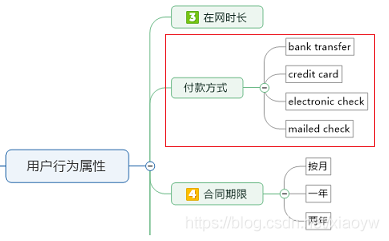
我們也經常遇到資料特征,是對數值資料使用的描述,而實際上是有數值大小意義的,例如圖中“合同期限”,按月描述就是:按月對應1(個月)、按一年對應12(個月)、按兩年對應24(個月),這樣更適合表述特征含義,
2.3.4. 特征與指標
我們通過程序中的輸出結果,逐步確立分析指標,設定參考標準,例如用戶在網時長,根據前面的資料分布圖,以及離散化策略,我們可以離散化出多個在網時長的區間,而且通常這樣的分析方法效果更好,也方便對標,
對于one-hot類編碼,往往是業務分類產生的,這也是產生指標的一個重要來源,而且可以根據重要程度而確立指標,
3. 根據預測結論設計資料分析產品
著名的咨詢公司Gartner在2013年總結、提煉出了一套資料分析的框架,資料分析的四個層次:描述性分析、診斷性分析、預測性分析、處方性分析,
我們雖然憑經驗直接給出處方分析是很難實作的,但是我們可以先從預測結論倒敘推理,自頂向下,根據預測結論及預測分析程序輸出核心結果,形成以重要影響因素、經營管理考核指標(需求)、特征相關性為主的層次子結論,逐層分類展開資料分析產品設計,
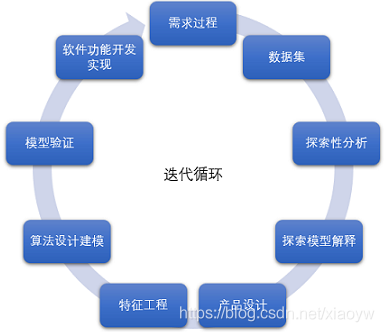
資料分析研發程序原則:
- 資料驅動、AI驅動,產品設計利用資料和AI技術
- 產品設計界定研發邊界
- 研發邊界和深度依萊澩并受資源限制
- 提供模型可解釋性
- 研發程序遵循迭代回圈
接下來,我們仍以客戶流失為例,按上圖,根據“探索性分析”的結果和結論,展開“產品設計”程序,下圖是客戶全生命周期,其中客戶流失的拐點,流失預警期將是我們的重中之重,

3.1. 預測結論及分析(頂層)
我們所設計預測,是想提前知道未發生的事和預期結果對比,預測結果仍以資料描述方式表達,如果繼續以客戶流失預測為例,需要表達的內容如下:
1、客戶流失率、流失數量、流失客戶明細,預測流失與同期、上期、管理指標對標分析,包括同期比、環比,
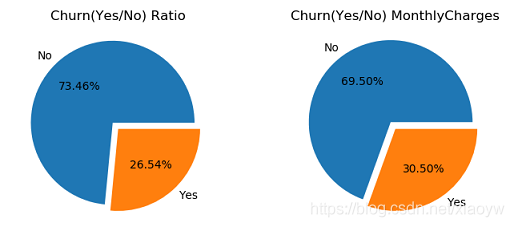
客戶流失造成月收入減少30.5%,
plt.rcParams['figure.figsize']= 12,6 #6,6
plt.subplot(1,2,1)
plt.pie(self.df['Churn'].value_counts(),labels=self.df['Churn'].value_counts().index,autopct='%1.2f%%',explode=(0.1,0))
plt.title('Churn(Yes/No) Ratio')
plt.subplot(1,2,2)
dd = self.df[['MonthlyCharges','TotalCharges','Churn']].groupby(['Churn'], as_index=False).sum()
plt.pie(dd['MonthlyCharges'],labels=dd['Churn'],autopct='%1.2f%%',explode=(0.1,0))
plt.title('Churn(Yes/No) MonthlyCharges')
plt.show()
2、流失客戶帶來的影響,流失客戶所引起減少的(月)收入,需要打新多少新用戶彌補及實作概率,
3、影響客戶流失重要因素、相關因素,并給出優化措施建議,
我們依據客戶流失集各個特征的重要程度,重點分析消費金額和在網時長,其實這些和我們實際經驗比較接近,大多數客戶最關心的就是錢,對價格比較敏感,
所以,我們的產品設計上,將傾向分析客戶價格敏感情況,建立客戶價格敏感畫像,以及相關支撐服務,
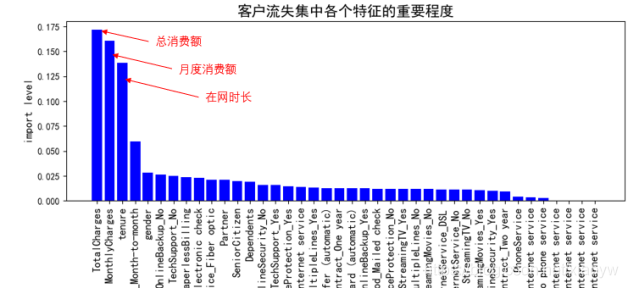
3.2. 分析重要影響因素
我們依舊預測程序中重要因素、相關因素等輸出,深入分析這些因素(為了簡便說明,此處只是使用了XGBoost演算法預測),例如:
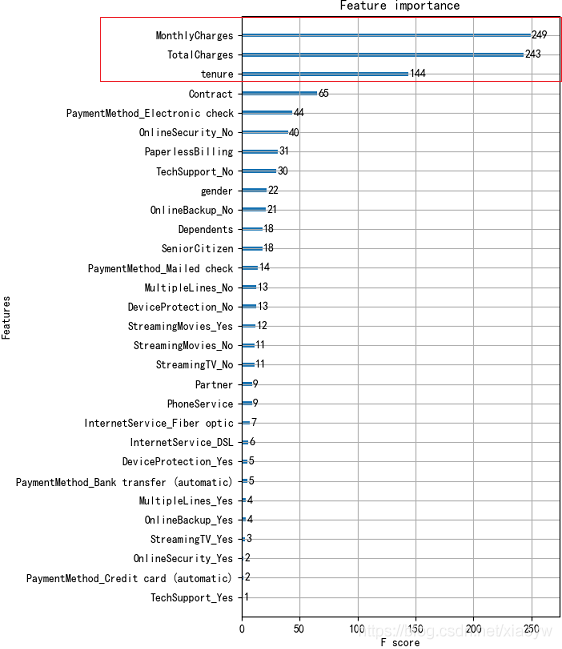
如上圖所示,位列三甲重要特征為月度消費金額、總消費金額、在網時長,與我們經驗認知一致,流失很大原因就是差錢!
1、分類對比流失客戶與未流失客戶的月消費金額(客單價),分類對比流失客戶與未流失客戶的在網時長,
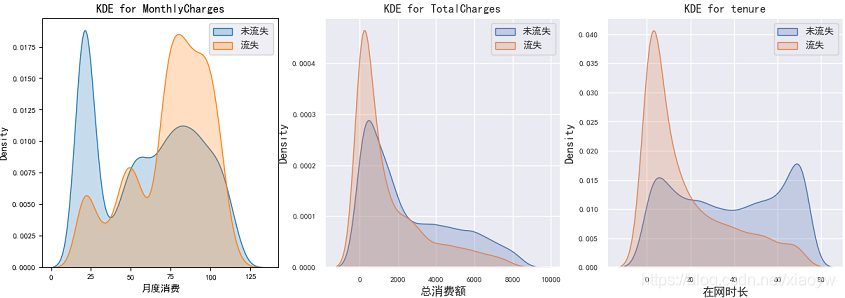
def kdeAnalysis(self):
plt.rcParams['font.sans-serif']=['SimHei'] #顯示中文標簽
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(18, 5))
plt.subplot(1,3,1)
kdeplot('MonthlyCharges','月度消費',self.df,'Churn')
plt.subplot(1,3,2)
kdeplot('TotalCharges','總消費額',self.df,'Churn')
plt.subplot(1,3,3)
kdeplot('tenure','在網時長',self.df,'Churn')
plt.show()
# Kernel density estimaton核密度估計
def kdeplot(feature,xlabel,data,tag='Churn'):
plt.title("KDE for {0}".format(feature))
plt.yticks(fontsize=8)
plt.xticks(fontsize=8)
sns.set(font='SimHei') #, font_scale=0.8) # 解決Seaborn中文顯示問題
sns.set_style({'font.sans-serif':['simhei', 'Arial']})
ax0 = sns.kdeplot(data[data['Churn'] == 'No'][feature], label= '未流失', shade='True',legend=True)
ax1 = sns.kdeplot(data[data['Churn'] == 'Yes'][feature], label= '流失',shade='True',legend=True)
plt.xlabel(xlabel)
plt.rcParams.update({'font.size': 10})
plt.legend(fontsize=10)
2、分析月消費金額、在網時長等重要特征的相關因素
在給定電信客戶流失資料集中,各個特征獨立性較強,如下圖所示,沒有必要深入分析其他特征的相關性,
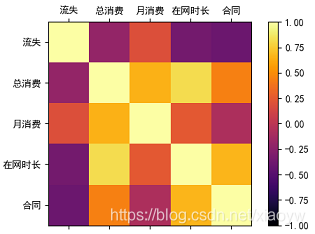
3、選擇影響重要因素分析
如下圖所示,只分析重要影響因素,而對于類似“PhoneService”特征,影響靠后的可以略去,不予以分析,
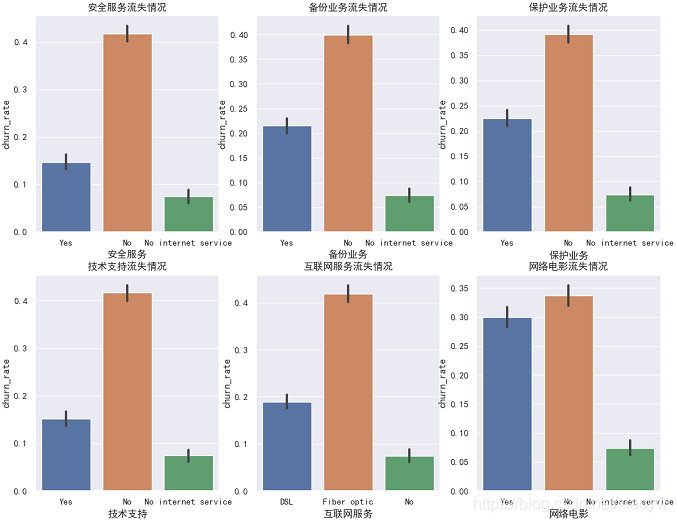
def serviceAnalysis(self):
plt.rcParams['font.sans-serif']=['SimHei'] #顯示中文標簽
plt.rcParams['axes.unicode_minus']=False
sns.set(font='SimHei') #, font_scale=0.8) # 解決Seaborn中文顯示問題
sns.set_style({'font.sans-serif':['simhei', 'Arial']})
self.df['churn_rate'] = self.df['Churn'].replace("No", 0).replace("Yes", 1)
items=['OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','InternetService', 'StreamingMovies']
items_name=['安全服務','備份業務','保護業務','技術支持','互聯網服務','網路電影']
def get_order(items_index):
if items_index == 4:
return ['DSL','Fiber optic','No']
else:
return ['Yes','No','No internet service']
fig,axes=plt.subplots(nrows=2,ncols=3,figsize=(8,12))
for i,item in enumerate(items):
plt.subplot(2,3,(i+1))
ax=sns.barplot(x=item,y='churn_rate',data=self.df,order=get_order(i))
plt.rcParams.update({'font.size': 12})
plt.xlabel(str(items_name[i]))
plt.title(str(items_name[i])+'流失情況')
i+=1
plt.show()
3.2. 確立分析指標
如何確立分析指標呢?一般情況下,我們從兩個方面考慮:一是業務原理和需求所規定的,屬于剛需,也可能不合理,我們可以試探打破;二是資料驅動、AI驅動所邏輯推理給出的,
3.2.1. 基于業務機理提煉指標
例如客戶指標:
- 客單價:銷售額/客戶數,反映客戶的質量、消費水平,
- 件單價:銷售額/銷售量,反映客戶的購買商品的平均單價;
- 客單件:銷售量/客戶數,反映客戶的購買力,購買多少商品的數量;
- 連帶率:銷售量/成交單量,也叫作購物籃系數,連帶率和人、場有關,
- 新增會員數:新增會員數=期末會員數-期扯訓員總數
- 會員增長率:會員增長率=某短時間新增會員數/期初有效會員數
- 會員貢獻率:會員貢獻率=會員銷售總額/總銷售額
- 有效會員占比: 有效會員占比=有效會員總數/累計會員總數
- 會員流失率:會員流失率=某段時間內流失的會員數/期初有效會員總數
- 會員活躍度: 會員活躍度=活躍會員數量/會員總量
- 平均購買次數:平均購買次數=某個時間段內訂單總數/會員總數
- 會員平均年齡: 會員平均年齡=某個時間段店內會員年齡總和/有效會員總數
3.2.2. 資料驅動、AI驅動邏輯給出
1、資料增維,產生新的特征,例如新增“月平均消費”,月平均消費=總消費/在網時長,如下圖所示,屬于重要特征,我們可以建議設定為分析指標,

2、聚類,例如對流失客群分類,其實我們也不知道怎么分,那么可以先試探聚類演算法看結果,初步來看是和平均消費額大小關系更為密切,
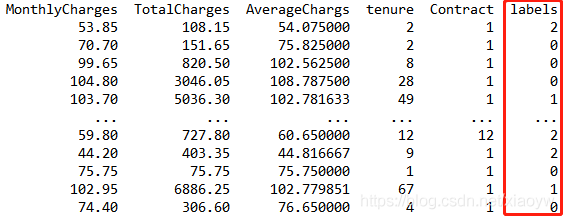
def clusteringAnalysis(self):
data = self.df[self.df['Churn']==1].reset_index(drop=True)#重設索引
samples = data[['MonthlyCharges','TotalCharges','AverageChargs','tenure','Contract']]
#標準化
scaler=StandardScaler()
kmeans=MiniBatchKMeans(n_clusters=3,random_state=9,max_iter=100)
pipeline=make_pipeline(scaler,kmeans)
pipeline.fit(samples) #訓練模型
labels=pipeline.predict(samples)#預測
samples['labels'] = labels #合并資料集
強化學習構建聚類指標,通過獎勵大,最終建立一個Q值表?
3、對現有特征資料項轉化,例如one-hot編碼所轉換出來的,在預測模型中表現比較重要的離散資料項,也可能升格為分析指標,
3.3. 可視化
資料可視化,正如本文開始所說的,和資料分析的四個層次密切相關,資料可視化可以分為描述性分析、診斷性分析、預測性分析、處方性分析,
我們通常我看到的圖表,主要是通俗化數學統計范疇的內容,大多數人都能看懂,其實,我們還需要專業化圖表,為專業化服務,
4. 總結
通過客戶流失預測案例感悟資料分析設計方法,正如Gartner于2020年給出資料分析領域的技術趨勢,更智能、更高速、更負責的AI,凸顯新技術引領業務,以站在高緯度上的預測結果為頂層設計,倒逼資料診斷分析、描述性分析,使業務資料分析線條更清晰,目的更明確,
對于資料分析作業崗位,其實可以分為兩種:一種類似產品經理、一種偏向資料挖掘,類似產品經理向更加注重業務,對業務能力要求比較高;資料挖掘向更加注重技術,對演算法代碼能力要求比較高,
由于作者水平有限,歡迎交流討論,
本文涉及代碼詳見:https://github.com/xiaoyw71/Feature-engineering-machine-learning
參考:
[1].《電信用戶流失分析與預測》 知乎 ,南橋那人 ,2019年6月
[2].《Telco Customer Churn》 CSDN博客 , qqissweat ,2021年1月
[3].《大資料人工智能常用特征工程與資料預處理Python實踐(2)》 CSDN博客 ,肖永威,2020年12月
[4].《oversample 過采樣方法 SMOTE ——欠采樣(undersampling)和過采樣(oversampling)會對模型帶來怎樣的影響》 CSDN博客, Arthur-Ji ,2019年8月
[5].《資料分析的四個層次》 人人都是產品經理 , 大鵬 ,2020年7月
[6].《Gartner發布2020年資料與分析領域的十大技術趨勢》 Gartner ,Laurence Goasduff ,2020.06
[7].《最全的零售行業指標體系詳解!》 知乎 ,李啟方 ,2020年10月
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/255946.html
標籤:區塊鏈
上一篇:參加Chainlink中國開發者社區ETHDenver #BUIDLathon專案提交,贏取Chainlink專案提交獎勵!