注意:在1.8之前(本例是1.7版本)中才有indexFor()方法,而1.7及以后該方法沒有了,該方法所產生的作用不再是單獨作為一個方法出現,
該方法的原始碼:
static int indexFor(int h, int length) {
return h & (length-1);
}知道這個方法肯定明白indexFor()方法將hash生成的整型轉換成鏈表陣列的下標,
而h&(length-1)的意思就是取模,即h%length,有下面的等式,但滿足這個等式需要條件的,
h % length == h&(length-1)
// 該等式滿足的條件是length必須是2的n次方但代碼為什么是這樣呢?因為位運算(&)比取模運算(%)效率高得多,畢竟是直接操控二進制位,而取模運算還要轉換成十進制,
那為什么上面的等式相等呢?看下面的代碼,去運行下
public class Demo {
public static void main(String[] args) {
System.out.println(6 % 4);
System.out.println(6 & (4 - 1));
System.out.println();
System.out.println(9 % 16);
System.out.println(9 & (16 - 1));
System.out.println();
System.out.println(6%3);
System.out.println(6&(3-1));
}
}
/**
* 列印結果:
* 2
* 2
*
* 9
* 9
*
* 0
* 2
*/發現如果length是2的n次方,則滿足上面的等式,即可以使用&代替%,但如果length不是2的n次方,則該等式不成立,
為什么呢?&是屬于位運算中的運算,而與(&)運算的運算規則如下:
0&0=0;0&1=0;1&0=0;1&1=1
即:兩個同時為1,結果為1,否則為0
所以把上面的數轉換成二進制來進行&運算,可以一目了然,
十進制6的二進制為:0000 0110
十進制4的二進制為:0000 0100
十進制3的二進制為:0000 0011
而6%4,即是

幾個2的n次方十進制數轉換成二進制得到的結果如下:
2的n次方所轉換成二進制的結果如下:
2^0 0000 0001
2^1 0000 0010
2^2 0000 0100
2^3 0000 1000
2^4 0001 0000
2^5 0010 0000
2^6 0100 0000
2^7 1000 0000所以上面這些是為了證明h % length == h&(length-1)這個等式是成立的,但如果length不是2的n次方則是不成立的,上面的代碼已經證明了結果,
所以只需要滿足length的長度是2的n次方,則可以使用位運算子來提高效率,來實作取模運算,
而indexFor是在HashMap中使用的,而HashMap中保證了length一定是2的n次方倍,
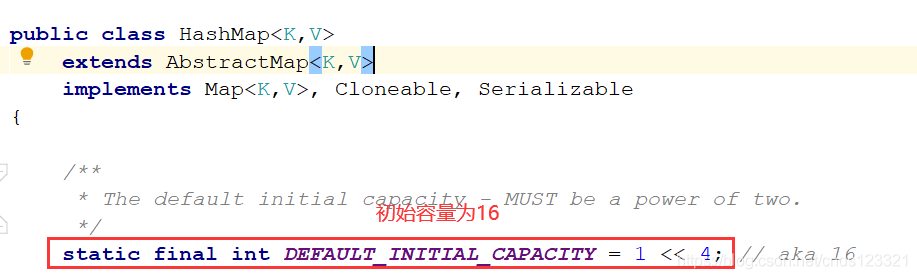
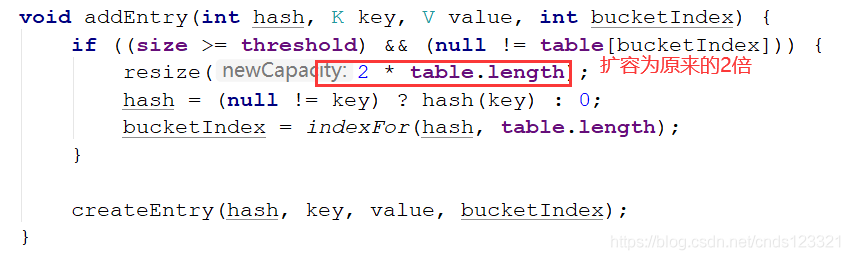
其中HashMap中的初始值是16,是2的4次方,而每次擴容擴為了原來容量的2倍,也就是32,即2的5次方,以后每次擴容,都保證了是2的n次方,
下面提供原始碼證明:
下面看下取模運算和位運算的執行效率差別
public class Demo {
public static void main(String[] args) {
int num=1000000000;// 10億
mod(num);
bit(num);
}
private static void mod(int num){
// 取模運算的時間
long start=System.currentTimeMillis();
int result;
for (int i = 1; i <= num; i++) {
result=i%5;
}
long end=System.currentTimeMillis();
System.out.println("取模運算的時間:"+(end-start)+"毫秒");
}
private static void bit(int num){
// 位運算的時間
long start=System.currentTimeMillis();
int result;
for (int i = 1; i <= num; i++) {
result=i&5;
}
long end=System.currentTimeMillis();
System.out.println("位運算的時間:"+(end-start)+"毫秒");
}
}列印的結果:

如果資料量大了之后,使用位運算效率比取模運算高得多,
一個簡單但值得注意的問題:為什么對length取模就可以得到該物件存盤在鏈表陣列中的哪個下標呢?
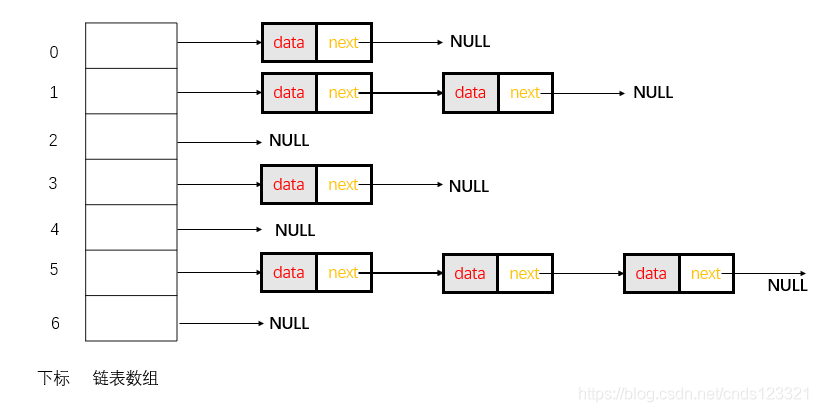
要明白這個問題,需要對哈希表的實作結構一個認知,這里是采用的鏈地址法解決沖突,所以資料結構是采用的鏈表陣列,即將哈希表的每個單元作為鏈表的頭結點,所有哈希地址為i的元素構成一個同義詞鏈表,即發生沖突時就把該關鍵字鏈在以該單元為頭結點的鏈表的尾部,
將任意長度的二進制值串映射為固定長度的二進制值串,這個映射的規則就是哈希演算法,而通過原始資料映射之后得到的二進制值串就是哈希值(散列值),
而hash(key)就是一個hash函式,生成一個十進制整數值,然后還要將這個整數值映射到指定大小的陣列中,而要把超過陣列長度的數映射到陣列中,對陣列長度取模即可,比如說陣列長度length是13,而要把30放入陣列中,那么用30%13取模運算后得到4,即放入到陣列中索引為4的位置,
而在HashMap中這個陣列的長度也是固定的,即length,
可能我還是沒有說清楚,反而越來越糊涂了,
看下面的代碼:
/*
說明:
1.有一些物件需要放入到一個陣列中(為什么要把它們放入陣列,可以探究為什么會產生哈希演算法?)
2.問題來了,怎么確定該物件應該放到陣列中哪個位置,不可能每個程式員都制定一套規則,讓這個物件放到某個位置,沒有統一的標準
3.哈希演算法就可以將一個物件映射成一串二進制,這串二進制又可以轉換成十進制整數
4.也就是某物件和它通過哈希演算法產生的十進制整數是映射關系,對應的
5.可以通過十進制來研究該把放入到陣列中哪個位置
6.發現用十進制數對陣列長度取模,可以將所有物件都限制在陣列長度范圍內
7.這就解決了把這物件放到陣列中哪個位置的問題
*/
public class Demo {
public static void main(String[] args) {
String str=new String("abc");
System.out.println(str);
// 獲取str的hashCode值
int hashCode = str.hashCode();
System.out.println(hashCode);
// 將獲得的所有物件存放到一個長度為20的陣列中
Object[] arr=new Object[20];
int index = hashCode%arr.length;
System.out.println(index);
// 然后將該物件放入陣列中對應下標的位置
arr[index]=str;
System.out.println(Arrays.toString(arr));
}
}控制臺列印結果為:

上面就簡單地模擬了下,應該有更直觀的感受了,
總結:indexFor()方法就是將hash(key)演算法生成的十進制整數對陣列取模,得到對應的下標,確定該物件應該放到陣列中的哪個位置,而使用位運算(&)是為了提高效率,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/257845.html
標籤:區塊鏈