
文章目錄
- 一. 問題背景
- 二. 知識儲備
- 2.1 共識演算法
- 2.2 CAP定理
- 三. 前言
- 四. Raft和Paxos的因緣?
- 五. Raft原理
- 5.1 節點個數
- 5.2 節點的角色
- 5.3 多數派協議
- 5.4 隨機超時機制
- 5.5 正常情況下,Raft集群是怎么樣的?
- 5.6 Candidate的日志長度要等于或者超過半數節點才能選為Leader
- 5.7 為什么不是檢查Commit Index?
- 5.8 Followers日志補齊
- 5.9 Followers未提交日志的更新
- 5.10 新舊Leader的交替
- 5.10.1 Term
- 5.10.2 作廢舊Leader
- 5.11 Raft的實作
一. 問題背景
研究完關于Redis的架構之后,想要了解一下哨兵模式是如何選出哨兵leader的,因此來研究一下raft演算法
參考:
- Raft官網
- 由淺入深理解Raft協議
- 白話講解paxos&raft演算法原理及實戰_一點課堂(多岸學院&多岸教育)
二. 知識儲備
2.1 共識演算法
在分布式系統的環境下,有若干個服務器在不同地方同時運行,這些服務器需要共同使用一套規則來協商某些事情,這套規則就是共識演算法,也可以叫一致性演算法,Redis哨兵集群選舉出leader就需要共識演算法,可簡單了解關于Redis的架構,共識涉及多個服務器就價值達成一致,一旦他們對價值做出決定,該決定就是最終決定
2.2 CAP定理
在分布式系統中,CAP定理是:
- C,Consistency,一致性,在分布式系統中所有資料副本的值,在同一時刻是否相同,
- A,Availability,可用性,集群中的部分節點故障后,剩余節點是否還能回應客戶端的讀寫請求,
- P,Partition tolerance,系統如果不能在時限內達成資料一致性,就意味著發生了磁區(比如A地的服務端資料無法與B地的服務端資料同步,存在資料差異),必須對當前操作在C和A之間做出選擇
三. 前言
Redis對Raft的應用,是在哨兵集群選舉出哨兵leader這方面,而不是直接選舉出提升哪個Redis slave為master,
四. Raft和Paxos的因緣?
由于Paxos過于難懂,因此有了Raft演算法(大牛們實在覺得Paxos太難懂了,因此模仿Paxos設計出了一套簡單易懂的共識演算法),并得到了廣泛的應用,這里就不講Paxos,只研究Raft
五. Raft原理
5.1 節點個數
一個Raft集群包含若干個服務器節點,通常是奇數個節點(一般是5個,這樣的系統可以容忍2個節點失效,因為掛了2個還剩3個,3個中每個人都必須投票給其他人且只能投一次,所以肯定會有一個人有最多票)
5.2 節點的角色
Raft集群中,有3種角色:
- follower,跟隨者 ,每個節點最初都是跟隨者,且都會有一個屬于自己的隨機超時時間(timeout),比如timeout為3s,3s內沒有收到leader的資訊,節點則變成candidate(候選者),
- candidate,候選者,成為候選者,可以向其他節點發出請求,請他們投自己一票,即選舉(每個節點在每次選舉中只能投一次票),最快得到最多票數的候選者將成為leader(領導者)
- leader,領導者,成為領導者后,定時發送訊息給其他節點,其他節點也要發送回應報文給leader,領導者可以代表整個raft集群內的所有節點,外部客戶端是與領導者互動的,
5.3 多數派協議
為了保證選舉的結果只產生一個leader,選舉的程序采用多數派協議(即少數服從多數),當一個candidate發出請求申請成為leader時,只有獲得raft集群中半數以上的follower同意后,才能成為leader,投票程序如下:
- follower每回應完leader的資訊后,都會開始一個隨機超時時間,最快超過這個超時時間的節點成為candidate,candidate向其他節點發送請求,申請成為leader
- follower們投票
- 如果獲得超過半數的follower投票,那么candidate自動變成leader,開始廣播日志(即發送心跳包)
5.4 隨機超時機制
candidate也會發生多個Candidate同時發送投票請求,而導致誰都不能夠得到多數贊成票的情況,有可能永遠也選不出Leader,為了保證Leader選舉的效率,Raft在投票選舉中使用了隨機超時的機制:
-
在每個Followers上設定的Leader超時時間是在一個范圍內隨機的,這樣可以盡量讓Followers不在同一時間發起Leader選舉,
-
每個candidate發起投票后,如果在一段時間內沒有任何candidate成為Leader則,需要重新發起Leader選舉,這段等待的時間,在每個candidate上也是隨機的,從而保證不會有多個candidate同時重新發起Leader選舉,
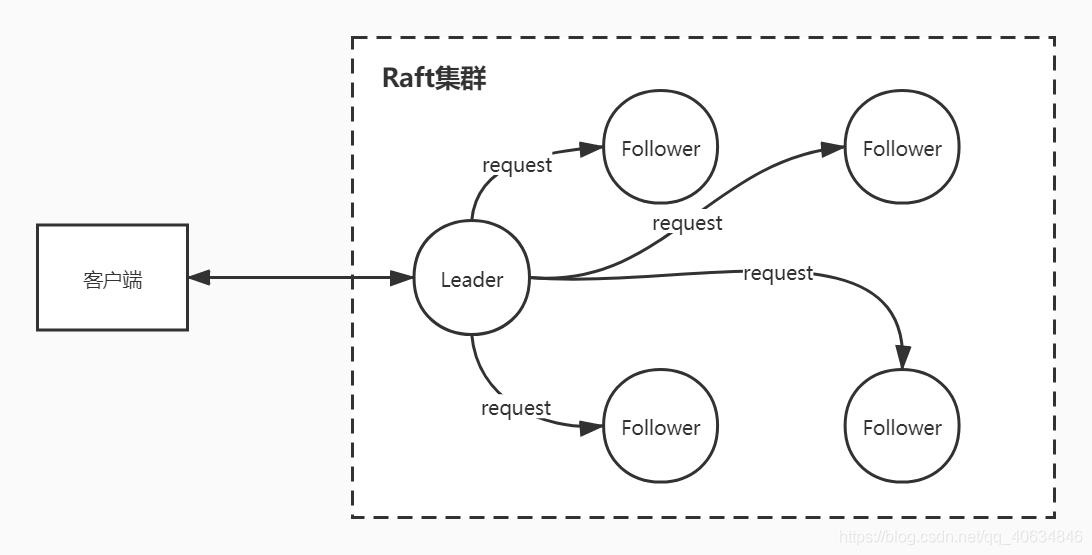
5.5 正常情況下,Raft集群是怎么樣的?
正常情況下:
- Raft的集群只有一個Leader,其余節點都是Follower,
- Follower都是被動的,他們不會發送任何請求,只是簡單地回應Leader和Candidate的請求,
- Leader處理所有的客戶端請求,如果客戶端與Follower通信,Follower會將請求重定向給Leader,
雖說是隨機的超時時間,但是也有個范圍,太小或者太大都會影響系統的可用性,太小會導致過多的選舉沖突,太大又會影響系統的平滑運行,在Raft的論文中,作者將這個超時時間稱為electionTimeout,并給出了合理的范圍,公式如下:
broadcastTime ? electionTimeout ? MTBF
“?”代表數量級上的差異(10倍以上),
5.6 Candidate的日志長度要等于或者超過半數節點才能選為Leader
當Leader故障時,Followers上日志的狀態很可能是不一致的,有的多有的少,而且Commit Index也不盡相同,
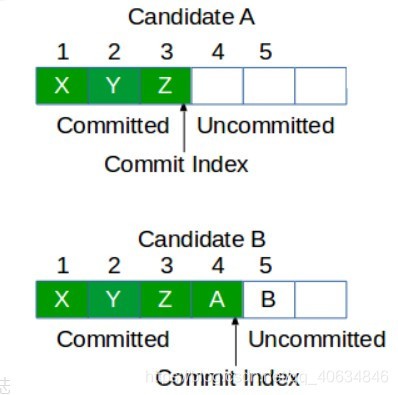
我們知道已經提交的日志是不能夠丟棄的,必須要最終復制到所有的節點上才行,假如在選Leader時,圖中Candidate A變成了Leader,就必須要首先從Candidate B上將日志4復制過來,然后才能開始處理新的日志,為了減少復雜性,raft就規定,只有包含了所有已提交日志的Candidate才能當選為Leader,
-
當發現Leader無回應后(一段時間內沒有資料或心跳),Candidate發送投票請求,請求中包含自己日志佇列的長度(或者說最大日志的Index),
-
Followers檢查Candidate的日志長度,只有Candidate的日志等于或者長于自己才投票,
-
如果超過半數的Followers投了票,則Candidate自動變成Leader,開始廣播資料
因為已經提交的日志一定被復制到了多數節點上,所以日志長度等于或者長于多數節點的Candidate一定包含了所有已經提交的日志
5.7 為什么不是檢查Commit Index?
因為Leader故障時,很有可能只有Leader的Commit Index是最大的,
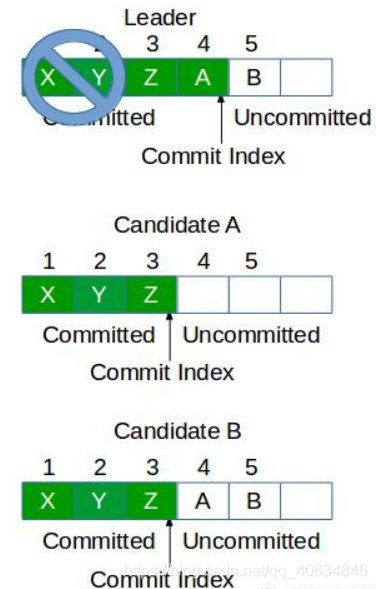
如果圖中的Candidate A被選舉為Leader,那么日志4就會被丟棄,但是日志4已經在原來的Leader上提交了,因此必須被保留才行,所以只能讓日志長度更長的Candidate B選為Leader,這種做法有可能把原來Leader沒廣播完成的日志(圖中的日志5)接著廣播完成,這沒有什么關系,
5.8 Followers日志補齊
當Leader故障時,Followers上的日志狀態是不一樣的,有長有短,因此新的Leader選出后,首先要將所有Followers的日志補齊才行,因此Leader要詢問Followers的日志長度,從最小的日志位置開始補齊,
5.9 Followers未提交日志的更新
新Leader的日志一定包含所有已經提交的日志,但新Leader的日志不一定是最長的,那些新Leader沒有的日志,一定是未提交的日志,因此可以被更新,沒有關系的,Leader只需要從自己的當前位置開始插入日志并廣播出去就可以了,Followers會用新的日志去更新指定位置上的日志,
5.10 新舊Leader的交替
新的Leader選出后,開始廣播日志,這時如果舊的Leader故障恢復了(比如網路臨時中斷),并且還認為自己是Leader,也會廣播日志,這不就導致了同時有兩個Leader出現嗎?是的,Raft也沒辦法讓舊的Leader不發日志,但是Raft有辦法讓Followers拒絕舊Leader的日志,
5.10.1 Term
Raft將時間劃分為連續的時間段,稱為Term, Term是指從一次Leader選舉開始到下一次Leader選舉的一段時間,這段時間內只能有一個Leader被選舉成功,并負責管理系統或者沒有Leader選出,
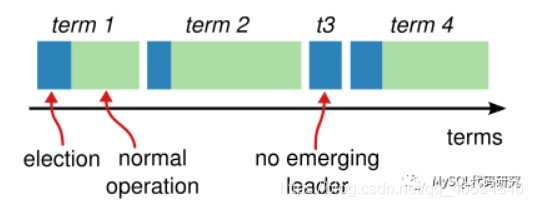
每個Term都有一個唯一的數字編號,所有Term的數字編號是從小到大連續排列的,
5.10.2 作廢舊Leader
Term編號在作廢舊Leader的程序中至關重要,但卻十分簡單,程序如下:
- 發送日志到所有Followers,Leader的Term編號隨日志一起發送,
- Followers收到日志后,檢查Leader的Term編號,如果Leader的Term編號等于或者大于自己的當前Term(Current Term)編號,則存盤日志到佇列并且應答收到日志,否則發送失敗訊息給Leader,訊息中包含自己的當前Term編號,
- 當Leader收到任何Term編號比自己的Term編號大的訊息時,則將自己變成Follower,收到的訊息包括:Follower給自己的回復訊息、新Leader的日志廣播訊息、Leader的選舉訊息,
5.11 Raft的實作
論文中作者僅用了兩個RPC就實作了Raft的功能,它們分別是:
-
RequestVote(): Candidate發起的投票請求 -
AppendEntries(): 將日志廣播到Followers上
AppendEntries()除了廣播日志外,作者還巧妙的用它實作了以下的功能:
- 發送心跳(heartbeat): 沒有客戶日志時,通過AppendEntries()廣播空日志,當做心跳,
- 發送Commit Index:當Commit Index更新后,可以隨著當前的日志通過AppendEntries()廣播到Followers上,如果沒有客戶端日志,則可以隨著心跳廣播出去,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/259287.html
標籤:區塊鏈
上一篇:go每日新聞(2021-02-11)——Go泛型方案已被采納
下一篇:什么是區塊鏈【運用費曼技巧解釋】