時序定位的區域-全域視頻-文字互動
Abstract
摘要
本文針對文本到視頻的時域定位問題,旨在識別與文本查詢語意相關的視頻時間間隔,我們使用一種新的基于回歸的模型來解決這個問題,該模型學習為文本查詢中的語意短語提取一組中級特征,這些特征對應于查詢中描述的重要語意物體(參與者、物件和動作等),并且從多個層次反映查詢的語言特征和視頻的視覺特征之間的雙模態互動,
該方法在雙模態互動中,利用從區域到全域的背景關系資訊,有效的預測了目標時間間隔,通過深度的消融研究,我們發現,在視頻和文本互動中結合區域和全域背景關系對準確的定位至關重要,我們的實驗表明,該方法在xx資料集上的性能遠遠優于目前的技術水平,在Recall@tIoU=0.5米處,分別為7.44%和4.61%
Introduction
介紹
研究背景
隨著網路上的視頻數量爆炸性增長,對視頻內容的理解并且分析視頻(內容分類及探究)變得日益重要,此外,隨著基于大規模資料集上深度學習取得的最新進展,對于視頻內容理解的研究也開始朝向多模態問題發展(視頻問答、視頻字幕),包括文字、語言和聲音,
解決的問題
本文解決了文字到視頻的時域定位問題,旨在定位視頻中與文本查詢中運算式對應的的時間間隔,
我們的主要想法是從文本查詢中提取多個語意短語,并使用語言學與視覺特征的區域與全域互動將他們與視頻對齊,我們將語意短語定義為可能描述了一個語意物體的單詞序列,如演員、物體、動作、地點等等,
圖表1a)展示了一個時域定位的例子:包含多個語意的文本查詢對應于演員(一個女人)和動作(混合了所有的原料,將它放在一個平底鍋,將它放進烤箱),這個例子表明了,一個文本查詢可以通過從查詢中識別相關的語意短語并適當的將它們與對應的視頻片段對齊,來有效的定位到視頻上,
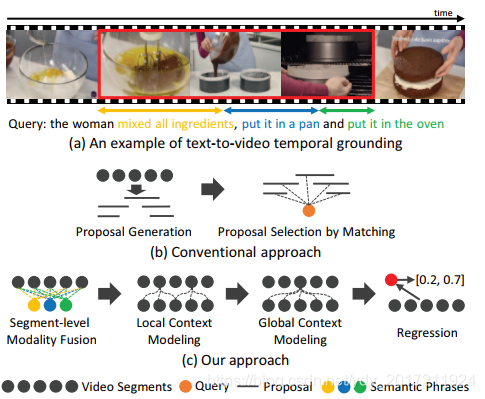
a)一個例子,目標時間間隔包含了多個與文本查詢中語意短語相關的部分
b) scan-and-localize框架,通過將獨立建議和查詢中的整個語意進行比較,來定位目標時間間隔(現有方法)
c)我們的方法,使用視頻片段和查詢中識別的語意短語間的三個層次上的雙模態互動,來回歸目標時間間隔
現有方法的問題
然而,在時域定位的問題上,從未探索過如何利用文本查詢中的這種語意短語,
1
大多數現有的方法[1,4,5,8,9,20,32,37]通常 scan-and-localize框架中解決這個問題,簡而言之,將查詢與所有時間間隔的候選建議進行對比,并選擇最高匹配,如圖表一b),在匹配中,他們依靠查詢的獨立全域特征而不是短語級別的細粒度特征,因此丟失了本地化中的重要細節,
2
最近的研究[35]將該任務定義為通過回歸的注意力定位,并試圖通過注意力方案從查詢中提取語意特征,然而,沒有全面理解語境的情況下,這種方法仍局限于識別最具辨識性的語意短語,
我們提出的方法
我們提出如圖一所示新穎的基于回歸的方法來解決時域定位問題,執行區域-全域的視頻-文字互動,對語意短語和視頻片段進行深入的關系建模,
與現有的方法相反,我們首先使用序列查詢注意力,提取語言學特征查詢中的語意短語,
接著我們執行三個層次的視頻-文本互動,來有效的將語意短語特征和片段級視覺特征進行匹配:
1)視頻片段和語意短語特征進行片段級融合,突出與每個語意短語相關的片段
2)區域背景關系建模,這有助于將短語與可變長度的時間區域對齊
3)全域背景關系建模,捕捉短語間的連接
最后我們使用時間注意力池化來聚合融合的片段級特征,并使用聚合特征回歸時間間隔
主要貢獻
我們我們引入了一個順序查詢注意模塊,從文本查詢中提取多個不同的語意短語表示,用于后續的視頻-文本互動
我們提出了一種有效的區域-全域視頻-文本互動演算法,在多個層次上對視頻片段和語意短語之間的關系進行建模,從而通過回歸增強最終定位,
我們進行了大量的實驗來驗證我們的方法的有效性,并表明它在這兩方面都比目前的技術水平要好很多,charadessta和ActivityNet標題資料集,
相關作業
2.1 時序行為檢測
最近的時間動作檢測方法通常依賴于影像領域的最先進的目標檢測和分割技術,可以分為以下三組:
首先,一些方法使用幀-級密集預測,根據置信值對幀進行修建并對相鄰幀進行分組,來確定時間間隔,
其次,基于建議的技術[27,31,36,38]提取所有的動作提議并細化其邊界以進行動作檢測
第三,存在一些基于單次檢測(如SSD[21])的快速推斷方法[18,34],
與僅限于定位單個動作實體的動作檢測任務不同,文本對視頻的時間基礎需要定位更復雜的間隔,根據句子查詢中的描述,這將涉及兩個以上的動作,
2.2 Text-to-Video時域定位
從用于text-to-video時域定位的兩個資料集DiDeMo Charades-STA發布以來,各種演算法[1,8,9,20,37)中已經使用了scan-and-localize框架,基于滑動視窗掃描整個視頻獲得候選片段,并最終選擇與輸入文本查詢最匹配的剪輯,
方法一
由于滑動視窗方案耗時且常常包含冗余的候選剪輯,因此提出了更有效、更高效的方法[4,5,32]作為替代方案:
提出了一種基于lstm的單流網路[4]來進行幀對字的互動,并提出了基于視頻片段生成的方法[5,32]來減少冗余候選剪輯的數量,
盡管這些方法成功的提高了處理時間,他們仍需要觀察整個視頻,因此,引入了增強學習來觀察一部分幀或幾個剪輯
方法二
另一方面,無提議演算法[10,25,35]也被提出,受最近在基于文本的機器理解方面的進展啟發,Ghosh等人[10]提出直接識別與起始和結束位置對應的視頻段索引,Opazo等人[25]通過采用查詢引導的動態過濾器改進了該方法,Yuan等人[35]提出了一種基于共同注意的位置回歸演算法,該演算法學習注意在ground-truth時間間隔內聚焦于視頻片段
方法三
ABLR[35]與我們的演算法最相似,因為它將任務定義為基于注意力的位置回歸,然而,我們的方法不同于ABLR在以下兩個方面,首先,abr只關注查詢中最具判別性的語意短語來獲取視覺資訊,而我們考慮多個語意短語來進行更全面的估計,其次,ABLR依賴于視頻和文本輸入之間的粗互動,通常無法捕捉視頻片段和查詢詞之間的細粒度關聯,
相比之下,我們采用了更有效的多層次視頻-文本互動來模擬語意短語和視頻片段之間的關聯,
3 提出的方法
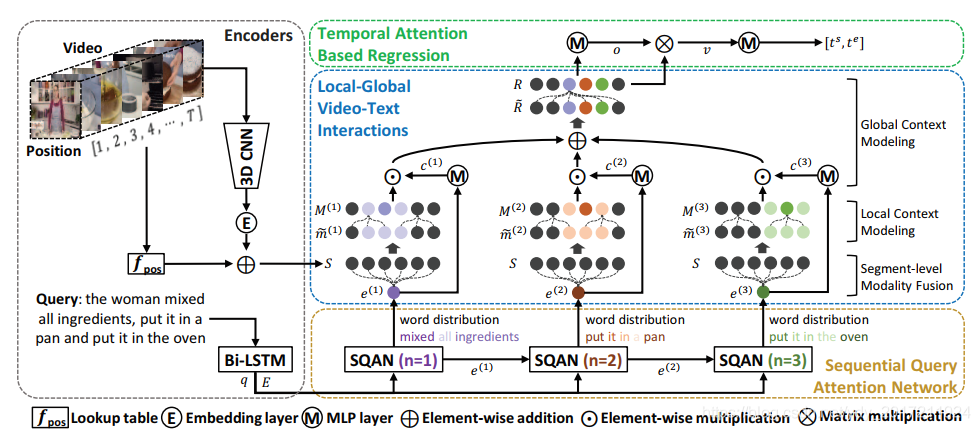
圖2,我們演算法的總體架構,給定一個視頻和一個文本查詢,我們對它們進行編碼,以獲得片段級視覺特征、單詞級和句子級文本特征(章節3.2),我們使用序列從查詢中提取一組語意短語特征查詢注意網路(SQAN)(章節3.3),然后,根據提取的短語特征,通過區域-全域視頻-文本互動獲得語意感知的片段特征(章節3.4),最后,我們利用時間注意直接從總結的視頻特征中預測時間間隔(章節3.5),我們使用回歸損失和兩個額外的注意相關損失來訓練模型(第3.6節)
3.1 演算法總覽
給定一個未修剪的視頻V,一個文本查詢Q和V內目標區域C的時間間隔,現有的方法通常學習由θ引數化的模型,以最大化以下期望對數似然:
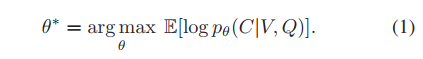
注意,在上面的目標函式中,文本查詢Q經常涉及到多個語意短語,如圖1(a),除了全域關系外,還需要對查詢與視頻之間的更精細的關系進行建模,以實作時間定位,
為了實作這一想法,我們引入了一個可微模塊fe,將查詢表示為一組語意短語,并結合區域-全域視頻-文本互動,以深入理解視頻中的短語,這導致了一個新的目標函式:
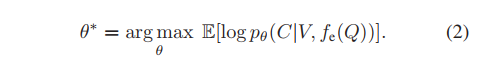
圖表2說明了所提方法的總體架構,
我們首先計算片段級視覺特征及其嵌入的時間戳,然后在查詢的基礎上推匯出單詞級和句子級特征,
其次,順序查詢注意網路(Sequential Query Attention Network,SQAN)通過順序關注詞級特征從查詢中提取多個語意短語特征,
然后,通過多層視頻-文本互動獲取語意感知的片段特征;通過分段級模態融合和區域背景關系建模來突出每個語意短語對應的片段特征,通過全域背景關系建模來估計短語之間的關系,
最后,使用臨時參與的語意感知段特征預測時間間隔,
3.2 編碼器
查詢編碼
對于有L個單詞的文本查詢,我們使用一個兩層的雙向LSTM來獲取單詞和句子級別的表示,
將雙向LSTM應用于嵌入的詞特征,通過公式
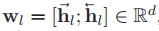
將兩個方向的隱藏狀態串聯起來,得到第l位的單詞級特征,
而句子級別的特征q是通過連接前向和后向lstm中的最后隱藏狀態來提供的,
d表示特征維數
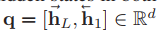
視頻編碼
一個未裁剪的視頻被分成一個固定長度的片段序列(例如,16幀),其中兩個相鄰的片段相互重疊一半的長度,
我們在對T個片段進行均勻采樣后,使用3D CNN模塊fv(·)從單個片段中提取特征,
然后將特征輸入到嵌入層,
再通過ReLU函式將其維度與查詢特征進行匹配,
形式上,用
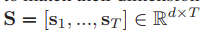
表示一個矩陣,在列上存盤了T個采樣過的片段特征,如果輸入視頻較短,且片段數小于T,則用零向量填充缺失部分
我們按照==[6]==的方法,將每個片段的時間位置嵌入到相應的片段特征向量中,以提高實際的精度,
這個程序可以得到如下的視頻表示公式:
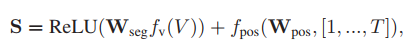
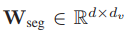
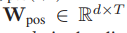
Wseg表示可學習的段特征嵌入矩陣
fpos為由嵌入矩陣Wpos和和時間戳[1, . . . , T ]定義的查找表
注意dv是由fv(·)提供的特征的尺寸
由于我們將給定的任務表述為位置回歸問題,位置編碼是在后續程序中識別不同時間位置語意的關鍵步驟,
3.3 順序查詢注意力網路(SQAN)
(2)中表示為fe(·)的SQAN在識別描述語意物體的語意短語方面起著關鍵作用,例如,演員,物件和動作,這些都應該在視頻中觀察到,以實作精確定位,
由于語意短語沒有groundtruth,我們以端到端的方式學習它們的表示,
為此,我們采用了一種注意機制,假設語意短語由查詢中的單詞序列定義,如圖1,這些語意短語可以彼此獨立提取,然而,請注意,由于我們的目標是獲得不同的短語,我們通過前面的序列條件來提取它們,如[13,33],

給出L個詞級特征的向量E以及一個句子級別的特征q,
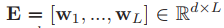
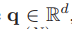
我們提取了N個語意短語特征
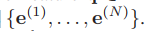
在每一步n中,通過將線性變換的句子級特征 與前面的語意短語特征e(n?1)∈Rd 連接起來的向量 嵌入 得到一個引導向量g(n)∈Rd
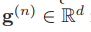
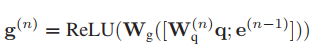
為可學習的嵌入矩陣,
請注意,我們在每一步使用不同的嵌入矩陣W(n) q,以便更容易地處理查詢的不同方面,
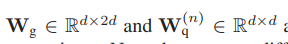
然后,通過對詞級特征上的注意權重向量a(n)∈RL進行估計
并計算詞級特征的加權總和,得到當前的語意短語特征e(n),如下:
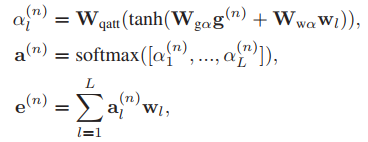
αl(n)為第l個詞在第n步的置信度值
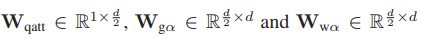
為可學習嵌入矩陣的查詢注意層
3.4 區域-全域的視頻-文本互動
考慮到語意短語的特征,我們在三個層次上進行視頻文本互動,以實作兩個目標:
1)個體語意短語理解和
2)語意短語之間的關系建模,
單獨語意短語理解
每個語意短語特征在兩個層次上與單獨的片段特征互動:片段級模態融合和區域背景關系建模,
在片段級模態融合中,我們鼓勵突出與語意短語特征相關的詞段特征,抑制不相關的詞段特征,然而,分段級互動不足以正確地理解長期語意物體,因為每個分段都只有16幀的有限視野,因此,我們引入了區域背景關系建模,考慮了相鄰的獨立片段,
考慮到這一點,我們使用Hadamard乘積進行類似==[14]==的片段級模態融合,同時基于殘差塊建模本地背景關系,殘差模塊(ResBlock)由兩個時間卷積層構成,注意,我們在ResBlock中使用了大帶寬的內核(例如,15)來覆寫長距離語意物體,整個程序總結如下
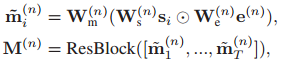
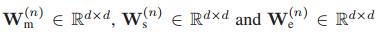
為用于分段級融合可學習的嵌入矩陣
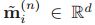
表示段級融合后的第i個雙模態段特征
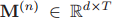
表示第n個語意短語特征e(n)的語意專用段特征,
語意短語之間的關系建模
在得到N個具體語意的段特征后,{M(1),…, M(N)},分別考慮語意短語之間的背景關系關系和時間關系,
例如,在圖1(a)中,在語意短語“把它放在平底鍋里”中理解“它”,需要從另一個短語“混合所有成分”的背景關系來理解,由于這種關系可以在時間間隔較大的語意短語之間定義,我們通過觀察所有其他部分來進行全域背景關系建模,
為此,我們首先聚合N個特定于語意短語的段特征{M(1), …, M(N)},采用注意力池化,根據相應的語意短語特征計算權重
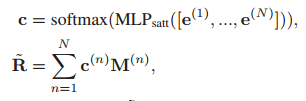
其中MLPsatt表示多層感知器(MLP),其隱含層為d/2維,
c∈RN是N個語意特定的片段特征的權向量,
~R是通過注意力池化得到的聚合特征
然后,我們使用非本地塊==[30]==(NLBlock),廣泛用于捕獲全域背景關系
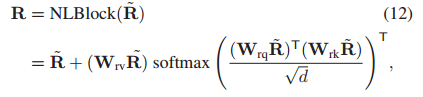
R是使用提出的區域-全域視頻-文本互動的最終語意感知片段特征,
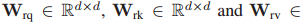
可學習的嵌入矩陣在NLBlock中
3.5 基于時間注意的回歸
一旦獲得語意感知的區段特征,我們在使用時間注意機制突出重要區段特征的同時對資訊進行總結,最后使用MLP預測時間間隔(ts, te)如下:
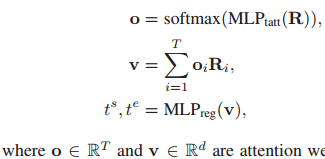
分別為片段的關注權值和總結視頻特征的關注權值,注意,MLPtatt和MLPreg分別有d2維和d維隱藏層,
3.6 training
我們使用三個損失項訓練網路:
1)位置回歸損失Lreg
2)時間注意力引導損失Ltag
3)顯著的查詢注意力損失Ldqa
整體loss為L = Lreg + Ltag + Ldqa.
位置回歸損失
==[35]==回歸損失定義為歸一化的標注時間區間(t?s, t?e)∈[0,1]與我們的預測(ts, te)之間光滑L1距離的和,如下
lreg = smoothL1(t?s?ts) + smoothL1(t?e?te),
|x| < 1 smoothL1(x)被定義為0.5x^2
否則定義為|x| -0.5
時間注意力引導損失
由于我們直接從時間注意特征回歸時間位置,時間注意的質量是至關重要的,因此,我們采用==[35]==中提出的時間注意引導損失
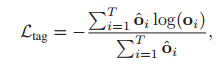
其中,如果第i段位于標注的時間間隔內,o?i設定為1,否則設定為0,注意引導損失使得模型在與文本查詢相關的片段中獲得更高的注意權值
顯著的查詢注意力損失
雖然SQAN的設計目的是捕捉查詢中的不同語意短語,但我們觀察到,不同步驟中的查詢注意權重通常與圖3所示相似,
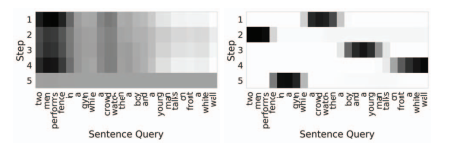
圖3:沒有突出查詢注意力損失的查詢注意力權重可視化(左),與突出查詢注意力損失的(右),SQAN成功地提取出了對應于不同步驟的參與者和動作的語意短語,
因此,我們采用==[19]==中引入的正則化術語,在不同的步驟中強制查詢注意權值不同:
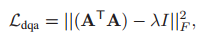
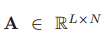
A為跨越N個步驟的連接的查詢注意權重,||·||F表示矩陣的Frobenius范數,
通過使兩個不同步驟的查詢注意力權重不相關,這種損失鼓勵注意力分布有更少的重疊
注意,λ∈[0,1]控制查詢注意分布之間的重疊程度;當λ接近1時,注意權重被學習為one-hot向量,圖3清楚地表明,正則化術語鼓勵模型在查詢注意步驟中關注不同的語意短語,
實驗
4.1 資料集
Charades-STA
該資料集由[8]從Charades 資料集中采集,用于評估文本-視頻時域定位,分別由訓練集和測驗集中的12408個時間間隔和3720個文本查詢對組成,視頻的平均長度為30秒,文本查詢的最大長度設定為10秒,
ActivityNet Captions
這個資料集最初是為密集視頻字幕而構建的,由20k平均長度120秒的YouTube視頻組成,分為10,024、4,926和5,044個視頻,分別用于訓練、驗證和測驗,視頻平均包含3.65個時間區間和句子描述,其中句子描述的平均長度為13.48個單詞,按照前面的方法,我們報告我們的演算法在驗證集(由val 1和val 2表示)上的性能,因為測驗分割的注釋不公開可用
4.2 指標
跟隨==【8】==我們采用兩個指標進行性能比較:
1)時域交集不同時間閾值的Recall值(R@tIoU),來測量 標注值大于閾值的tIoU的預測百分比,
2)平均tIoU (mIoU),我們使用三個tIoU閾值,{0.3,0.5,0.7},
4.3 應用細節
為了用3D CNN模塊在Charades-STA和ActivityNetCaptions資料集上提取分割特征,我們分別使用I3D[3] 2和C3D[28] 3網路,在一個訓練步驟中固定它們的引數,我們從每個視頻中均勻抽樣T(= 128)段,
對于查詢編碼,我們保持小寫轉換和標記化后的所有單詞標記;Charades-STA和ActivityNetCaptions資料集的詞匯量分別為1140和11125,
對于ActivityNetCaptions資料集,我們截斷所有最多有25個單詞的文本查詢,對于順序查詢注意網路(SQAN),我們提取了3個和5個語意短語,Charades-STA和ActivityNetCaptions資料集的λ分別設為0.3和0.2,在所有的實驗中,我們使用Adam[15]學習模型,以100個視頻查詢對和固定的學習速率0.0004,特征維度d設定為512,
4.4 與其他方法比較
我們將我們的演算法與最近的幾種方法進行了比較,這些方法分為兩組:
掃描-定位方法包括MCN [1], CTRL [8], SAP [5], ACL [9],acn [20], MLVI [32], TGN [4], MAN [37], TripNet [11],SMRL [29], RWM [12]
proposal-free演算法如ABLR[35]、ExCL[10]、PfTML-GA [25]
表1和表2分別總結了CharadesSTA和ActivityNet標題資料集上的結果,其中我們的演算法優于所有競爭方法,值得注意的是,就R@0.5度量而言,所提議的技術分別比最先進的性能高出7.44%和4.61%,
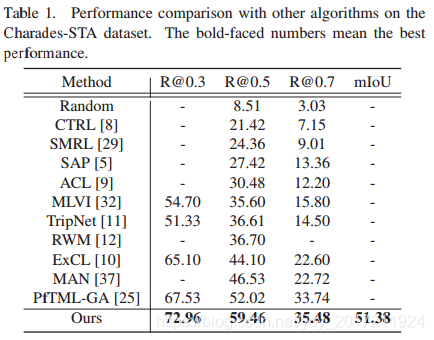
Charades-STA資料集上與其他演算法的性能比較,加粗的數字表示性能最好
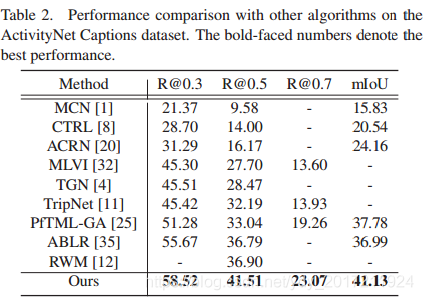
ActivityNetCaptions資料集上與其他演算法的性能比較,黑體數字表示最好的表現,
4.5 深入分析
為了更好地理解我們的演算法,我們分析了各個組件的貢獻,
4.5.1 模型簡化測驗
首先研究了順序查詢注意網路(SQAN)和LOSS項對CharadesSTA資料集的影響,
在這個實驗中,我們訓練5變種模型:
1)LGI:我們的完整模型,執行區域-全域的視頻-文字互動,基于SQAN提取的語意表達特征功能,且學習使用所有loss項
2)LGI w / o Ldqa: LGI學習沒有突出查詢注意Ldqa(不加Ldqa
3)LGI w / o Ltag: LGI學習沒有時間注意力引導Ltag,(不加Ltag
4)LGI-SQAN:一個本地化文本查詢的模型,使用了sentencelevel特性q而沒有SQAN,(不加SQAN
5) LGI-SQAN沒有Ltag
請注意,在補充材料中描述了LGI-SQAN的架構,

表3:Charades-STA資料集模型簡化研究結果,黑體字表示性能最好,
不同模塊的具體作用
表3總結了我們觀察到的以下結果,首先,從查詢中提取語意短語特征(LGI)比單純依賴句子級表示(LGI -SQAN)更有效地實作精確定位,其次,使用Ldqa對查詢的顯著性注意權重進行正則化,通過捕獲不同的語意短語,提高了性能,第三,時間注意力引導損失Ltag通過使模型在目標時間間隔內聚焦于段特征來提高定位精度,最后,注意到LGI-SQAN的性能已經超過了R@0.5上最先進的方法(即52.02% vs.57.34%),這表明了所提出的區域-全域視頻文本互動在建模視頻片段和查詢之間的關系方面的優越性,
引數調節 N和λ
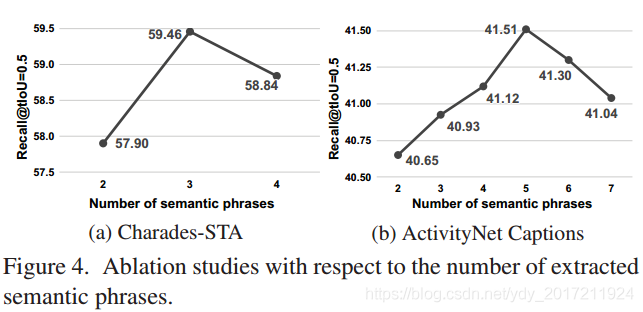
圖4:關于提取的語意短語的數量的Ablation studies
我們還在兩個資料集上分析了SQAN中兩個超引數的影響,sqa - ldqa中的語意短語數(N)和控制值(λ),圖4展示了在SQAN中語意短語數量的結果,在這些結果中,性能一直增加到一定數量然后減少(3和5分別用于Charades-STA和ActivityNetCaptions資料集),這是因為較大的N使模型捕捉更短的短語,不能描述正確的語意,
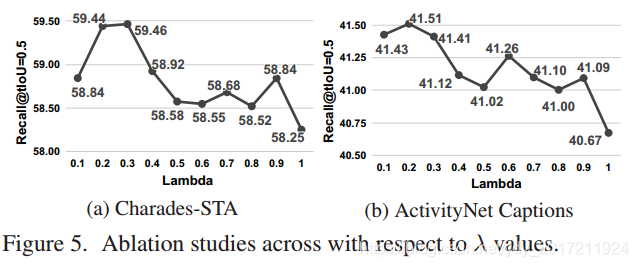
圖5:關于λ值的Ablation studies,
如圖5所示,控制值λ為0.2和0.3通常性能良好,而更高的λ通過使模型集中在一個或兩個單詞作為短語,性能較差,
4.5.2 區域-全域視頻-文本互動分析
我們對Charades-STA資料集上的區域-全域互動進行深入分析,為了做這個實驗,我們使用了
LGI - sqan(代替LGI)作為我們的基礎演算法,以節省訓練時間,
區域和全域背景關系建模的影響
我們通過改變殘差塊(ResBlock)中的內核大小(k)和非本地塊(NLBlock)中的塊數量(b)來研究區域和全域背景關系建模的影響,
對于區域背景關系建模,除了ResBlock外,我們還采用了一個額外的模塊,稱為masked非區域塊(Masked NL);掩碼將注意力區域限制為一個區域范圍,在NLBlock中以單個段為中心的固定視窗大小w,
表4總結了結果,說明了以下幾點,
首先,僅使用分段級模態融合而不使用背景關系建模的模型的性能遠遠沒有達到最先進的性能
其次,結合區域或全域背景關系建模可以增強語意短語與視頻的對齊,從而提高性能
第三,在區域背景關系建模中,更大的區域視圖范圍進一步提高了性能,根據我們的觀察,ResBlock比masked NL更有效
最后,合并區域和全域背景關系建模可以獲得16.48%的最佳性能增益
注意,盡管全域背景關系建模本身具有區域背景關系建模的能力,但通過增加nlblock的數量來對區域背景關系建模是很困難的;masked NL和NLBlock的組合性能優于堆疊的NLBlock,顯示了顯式本地背景關系建模的重要性
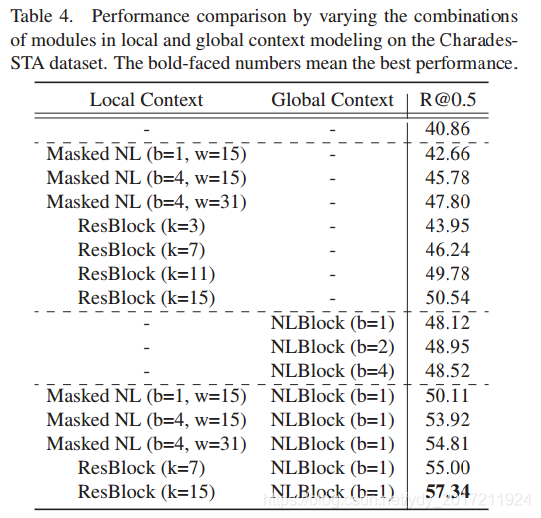
表4:通過在CharadesSTA資料集上改變區域和全域背景關系建模中的模塊組合進行性能比較,加粗的數字表示性能最好,
何時執行段級模態融合
表5(a)給出了三種不同選擇的模態融合階段的結果,這一結果表明,早期融合更有利于語意感知的聯合視頻文本的理解,并導致更好的準確性,
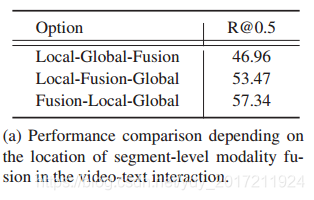
a)視頻-文本互動中基于片段級模態融合位置的性能比較,
c)位置嵌入對視頻編碼的影響,
模態融合方法
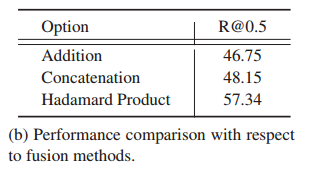
b)融合方法的性能比較,
我們比較了不同的融合操作——加法、連接和點乘,對于連接,我們通過增加一個嵌入層來匹配其他方法的輸出特征維數,從表5(b)可以看出,Hadamard積的性能最好,而其他兩種方法的性能要差得多,我們推測部分由于Hadamard積作為一個門控操作,而不是結合兩種形式,從而幫助模型區分語意短語相關和不相關的片段,
位置嵌入影響
表5?展示了位置嵌入在不同時間位置識別語意物體的有效性,提高了時序定位的準確性,

4.5.3 定性結果
圖6顯示了LGI和LGI - sqan的預測和時間注意力權重o,我們的完整模型LGI通過語意短語層次的查詢理解,提供了比LGI - sqan更準確的定位,使得視頻-文本互動更加有效,在我們的補充資料中介紹了更多可視化時間注意權重、查詢注意權重a和預測的例子,

兩個模型(LGI和LGI-SQAN)預測的可視化,和回歸前計算的時間注意權重o,
5 結論
我們提出了一種新的區域-全域視頻-文本互動演算法,通過成分語意短語提取來實作文本-視頻的時序定位,所提出的多層互動方案通過建模區域和全域背景關系,有效地捕獲了語意短語和視頻片段之間的關系,我們的演算法在charadessta和ActivityNetCaptions資料集上都達到了最先進的性能,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/260112.html
標籤:區塊鏈
上一篇:Vant Weapp輕量小程式 UI 組件庫匯入教程
下一篇:Go為什么天生支持高并發