一、初始化部分:

功能的初始化入口:StreamingFeaturePipeline::init
initNodes中會檢查各功能支持標志位,如果支持,則把對應Node添加到List中,
接下來通過兩個模板類的,實作呼叫不同Node的onInit方法,VSDOF功能對應DepthNode,這里以后都是為VSDOF功能定制的初始化流程,
有幾個重點函式:
-
initializeBufferPool:
依次呼叫所需的各個Node對應的initxxxBuffPool
完成每個Node 需要的BufferPool創建,并完成allocate動作,
每種資料緩沖池中buffer的數量就是在這里allocate時完成配置 -
buildImageBufferPoolMap:
構建bufferPoolMap,將第一步中創建的BufferPool與特定的key值系結,存盤到map中,方便后續根據使用場景取用 -
TEST_AND_CREATE_NODE:
檢查各Node支持情況,如果支持,則創建對應類的實體,并將前面流程中定義的mpNodeSignal, mpDepthStorage, mpBufferPoolMgr傳入各個node中,用于共享,
各Node的建構式中,主要完成:根據需要的資料,添加對應數量的addWaitQueue, -
buildPipeGraph:
連接各個節點的資料流,完成圖的構建,如下所示:
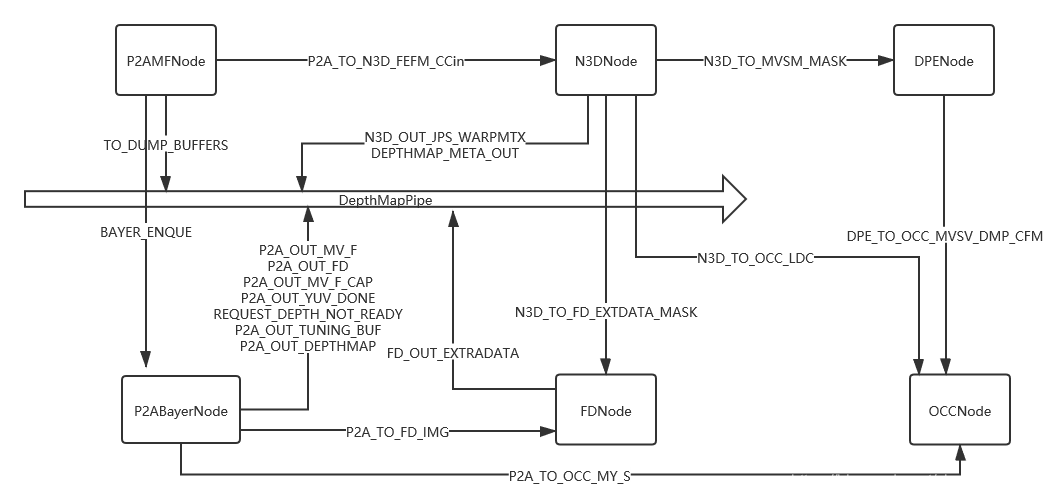
-
mCamGraph.start:
為各個Node起單獨的執行緒,并執行onThreadLoop里面的流程
二、各個Node onThreadLoop的部分流程走向:
Node間的聯系都是基于buildPipeGraph中創建的資料流走向,
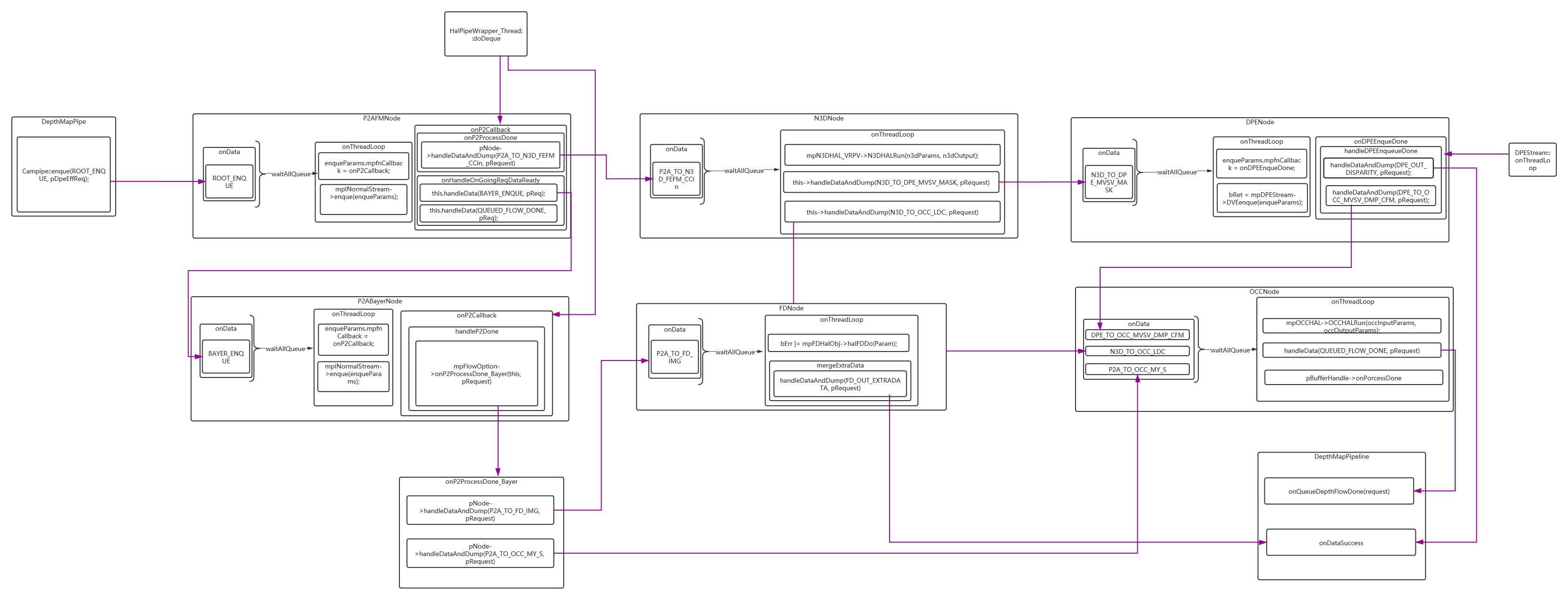
三、緩沖池(buffer pool)中每個buffer的輪轉流程
以N3DMaskBufPool_Main1為例:
- 創建buffer pool:
CREATE_IMGBUF_POOL(mN3DMaskBufPool_Main1, "N3DMaskBufPool_Main1", rN3DSize.mWARP_MASK_SIZE,
eImgFmt_Y8, usage, MTRUE);- 分配空間
ALLOCATE_BUFFER_POOL(mN3DMaskBufPool_Main1, VSDOF_WORKING_BUF_SET);- 添加到mBIDtoImgBufPoolMap_Scenario中,方便后續根據實際場景需求取用
MASKImgBufMap.add(eBUFFER_POOL_SCENARIO_PREVIEW, mN3DMaskBufPool_Main1);
mBIDtoImgBufPoolMap_Scenario.add(BID_N3D_OUT_MASK_M, MASKImgBufMap);
- Node的流程中通過bufferID(BID_N3D_OUT_MASK_M)定位需要獲取的具體buffer
IImageBuffer* pImgBuf_MASK_M = pBufferHandler->requestBuffer(getNodeId(), BID_N3D_OUT_MASK_M);requestbuffer方法中通過bufferID與使用場景獲取到buffer pool——對應第3步中構建的map
并從buffer pool中取出一個buffer,
SmartImageBuffer smImgBuf = mpBufferPoolMgr->request(bufferID, mReqAttr.bufferScenario);
SmartImageBuffer NodeBufferPoolMgr_VSDOF::request(DepthMapBufferID id, BufferPoolScenario scen)
{
……
ssize_t index_2 = mBIDtoImgBufPoolMap_Scenario.indexOfKey(id);
if(index_2 >= 0)
{
ScenarioToImgBufPoolMap ScenarioBufMap = mBIDtoImgBufPoolMap_Scenario.valueAt(index_2);
if((index=ScenarioBufMap.indexOfKey(scen))>=0)
{
sp<ImageBufferPool> pBufferPool = ScenarioBufMap.valueAt(index);
return pBufferPool->request(); //出堆疊
}
}
……
}- addEnquedBuffer方法構建BID buffer map:
將分配好的buffer添加到當前node對應的bidBufMap中
BIDToSmartBufferMap& bidBufMap = mEnqueBufferMap.editValueFor(srcNodeID);
bidBufMap.add(bufferID, smImgBuf);- 針對申請到到buffer做Node對應的處理:
rN3dParam.maskMain1 = pImgBuf_MASK_M;
bRet = mpN3DHAL_VRPV->N3DHALRun(n3dParams, n3dOutput);- 處理完成的資料傳遞給下一個目標Node
pBufferHandler->configOutBuffer(getNodeId(), BID_N3D_OUT_MASK_M, eDPETHMAP_PIPE_NODEID_DPE);此方法主要完成從源Node的buffer Map(第五步中構建)中取出需要傳遞的buffer,并添加到目標Node的buffer Map中
queuedBufferMap = mEnqueBufferMap.valueFor(srcNodeID);
smBuf = queuedBufferMap.valueAt(bufIndex); //獲取到對應buffer
this->addOutputBuffer(outNodeID, outBufferID, smBuf);- 通知目標節點資料已就位
this->handleDataAndDump(N3D_TO_DPE_MVSV_MASK, pRequest);呼叫目標節點的onDate,將對應的request添加到waitQueue中,然后在Node的onThreadLoop中從waitQueue中dequeue出來使用,
此處用到初始化流程第4步中buildPipeGraph方法構建的資料流向圖
- 目標節點獲取資料:
bRet &= pBufferHandler->getEnqueBuffer(getNodeId(), BID_N3D_OUT_MASK_M, pImgBuf_MASK_M);從第7步中構建的buffer Map中去除對應的buffer,并傳送到需要的位置做處理
rDPEConfigVec.push_back(dpeConfig);- 完成處理流程后清理buffer并返還到buffer pool
pBufferHandler->onProcessDone(getNodeId());遺留部分:
四、DPEStream部分的流程
五、每個Node 輸入/輸出的具體資料是什么
六、每個Node具體使用拿到的資料做了什么處理
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/277721.html
標籤:區塊鏈
下一篇:心得1:解方程組