Hyperledger Fabric區塊鏈結構由區塊頭和區塊體組成,并通過父區塊哈希編碼構成唯一鏈接,Hyperledger Fabric加入一層狀態快取設計,用以提高讀寫性能,
Hyperledger Fabric本質上是一個分布式賬本,在底層結構中都是通過鍵值對的方式來存盤資料,而區塊鏈1.0為了實作資料的時間可回溯性和資料防篡改機制,在鏈中并不保存資料的狀態,而只保存對資料的變更,這就使得對某條資料的狀態查詢需要進行全鏈遍歷,其查詢性能很難滿足一些企業級業務的性能需求,因此Hyperledger Fabric引入了“世界狀態(World State)”這一概念,
Fabric 里的資料以分布式賬本的形式存盤,賬本由一系列有順序和防篡改的記錄組成,記錄包含著資料的全部狀態改變,賬本中的資料項以鍵值對的形式存放,賬本中所有的鍵值對構成了賬本的狀態,也稱為“世界狀態”( World State ),當區塊中保存某一條記錄時,會同步更新對應Key的世界狀態,當需要查詢某個鍵值時,只需要查詢對應的世界狀態即可,而無需進行全鏈遍歷,
世界狀態是脫鏈保存在LevelDB/CouchDB結構中的,是一種鏈外附加快取機制,世界狀態的丟失并不會對區塊鏈中的資料產生影響,
每個通道中有唯一的賬本,由通道中所有成員共同維護著這個賬本,每個確認節點上都保存了它所屬通道的賬本的一個副本,因而是分布式賬本,對賬本的訪問需要通過鏈碼實作對賬本鍵值對的增加、洗掉、更新和查詢等的操作,
賬本由區塊鏈(File System)和狀態資料庫(Level DB)兩部分組成,如下圖所示
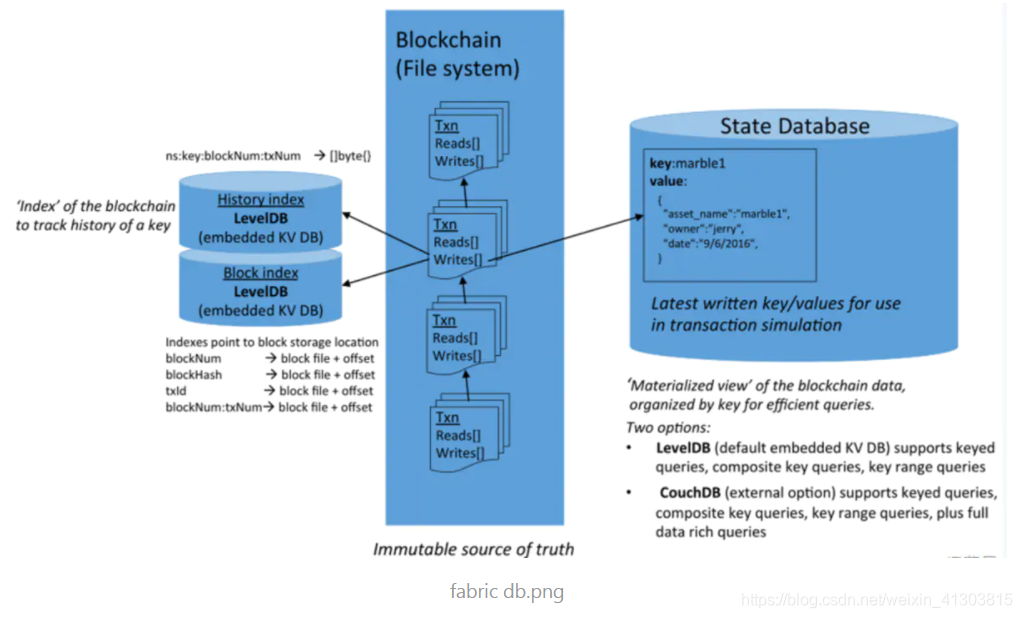
狀態資料庫,記錄了賬本中所有鍵值對的當前值,相當于對當前賬本的交易日志做了索引,鏈碼執行交易的時候需要讀取賬本的當前狀態,從狀態資料庫可以迅速獲取鍵值的最新狀態,
如果沒有狀態資料庫,要獲得某個鍵值時,需要遍歷整個區塊鏈中和該鍵值相關的交易,效率非常低,因此,讀取狀態資料庫可以認為是快速定位和訪問某個鍵值的方法,另外,當狀態資料庫出現故障的時候,可以通過遍歷賬本重新生成,
當一個區塊附加到區塊鏈尾部的時候,如果區塊中的有效交易修改了鍵值對,則會在狀態資料庫中作相應的更新,這樣區塊鏈和狀態資料庫始終保持一致,
狀態資料庫原理上可以是各種鍵值資料庫,Fabric 預設使用的是 LevelDB ,也支持 CouchDB 的選項,CouchDB 除了支持鍵值資料之外,也支持 JSON 格式的檔案模型,能夠做復雜的查詢,
資料存在節點:
/var/hyperledger/production/ledgersData

peer節點上賬本資料庫與區塊資料檔案路徑的默認配置串列
| 資料庫與檔案 | 檔案路徑 |
|---|---|
| id store資料庫 | /var/hyperledger/production/ledgersData/ledgerProvider |
| 區塊資料檔案 | /var/hyperledger/production/ledgersData/chains/chains |
| 隱私資料庫 | /var/hyperledger/production/ledgersData/pvtdataStore |
| 區塊索引資料庫 | /var/hyperledger/production/ledgersData/chains/index |
| 狀態資料庫 | LevelDB默認為/var/hyperledger/production/ledgersData/stateLeveldb CouchDB需要指定服務器地址、用戶名、密碼等配置引數 |
| 歷史資料庫 | /var/hyperledger/production/ledgersData/historyLeveldb |
| transient隱私資料庫 | /var/hyperledger/production/transientStore |
(1)chains:chains/chains下包含的mychannel是對應的channel的名稱,因為Fabric是有多channel的機制,而channel之間的賬本是隔離的,每個channel都有自己的賬本空間,chains/index下面包含的是levelDB資料庫檔案,在Fabric中默認所有的資料庫都是LevelDB,這個原因作者下面會講到,DB中存盤的就是我們上面說的區塊索引部分,chains/chains和chains/index就是上面所說的File System和indexDB;
(2)stateLeveldb: 同樣是levelDB資料庫,存盤的是智能合約putstate寫入的資料;
(3)ledgerProvider:資料庫記憶體儲的是當前節點所包含channel的資訊(已經創建的channel id 和正在創建中的channel id),主要是為了Fabric的多channel機制服務的;
(4)historyLeveldb:資料庫記憶體儲的是智能合約中寫入的key的歷史記錄的索引地址,
order節點上賬本資料庫與區塊資料檔案路徑的默認配置串列
| 資料庫與檔案 | 檔案路徑 |
|---|---|
| 區塊資料檔案 | /var/hyperledger/production/orderer/chains |
| 區塊索引資料庫 | /var/hyperledger/production/orderer/index |
peer節點賬本存盤圖如下
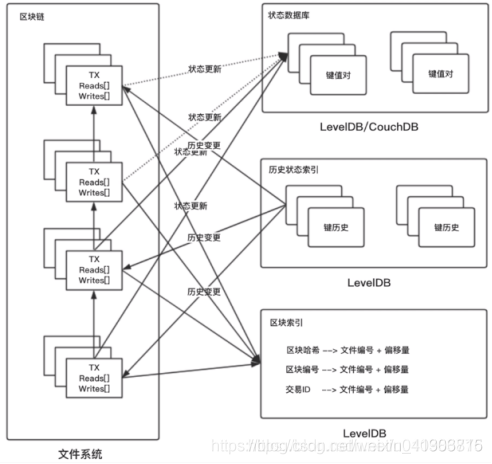
1 左邊區塊鏈是狹義的區塊存盤,底層是一個檔案系統,區塊并不是存盤在資料庫,而是直接存盤為檔案
2 右半部分的區塊索參考于查詢區塊,將區塊屬性與區塊位置相關聯,例如通過區塊hash、區塊高度、交易id查詢區塊資料,區塊索引的實作使用了內置資料庫Leveldb
3 歷史資料索引 啟用與否取決于智能合約是否有查詢歷史的需求,記錄某個鍵值在某條交易中被改變,只記錄改變動作,不記錄具體改變
4 狀態資料庫存盤當前區塊鏈上最新的資料,以鍵值對key-value的形式存盤所有鍵的最新值
賬本存盤原始碼:
狀態資料庫: 可選leveldb、couchdb
vim /opt/gopath/src/github.com/hyperledger/fabric/core/ledger/kvledger/txmgmt/statedb/stateleveldb/stateleveldb.go
歷史資料庫
vim /opt/gopath/src/github.com/hyperledger/fabric/core/ledger/kvledger/history/db.go

區塊檔案讀取:
vim /opt/gopath/src/github.com/hyperledger/fabric/common/ledger/blkstorage/blockstore.go

區塊鏈資料操作 —查詢
區塊鏈資料操作 —添加
呼叫鏈碼發起查詢操作的時候,查的就是世界狀態當中的值,因為查詢操作不會對賬本的當前狀態造成任何改變,
而當呼叫鏈碼發起寫操作(更改,洗掉,增加)時,應用程式提交一個交易提案到背書節點,背書節點背書之后回傳,應用程式再將交易發送給排序節點排序,之后排序節點將交易打包成區塊,將區塊分發給各個組織的 peer 節點,此時,如果該交易是一筆無效交易(比如驗證簽名失敗,背書失敗等等原因),那么該筆交易只會被存盤到本地的交易記錄中,但是不會更改賬本的世界狀態——即無效交易不會導致賬本世界狀態的改變,
另外,世界狀態中的每個狀態都有一個版本號,版本號供 Fabric 內部使用,并且每次狀態更改時版本號都會發生遞增,舉個例子,其當前狀態版本號都是0,當發生了一次對賬本物件的寫操作的時候,賬本的狀態就發生了變化,這樣的新的世界狀態就產生了,其中的狀態的版本號就是1,
每當更新狀態時,都會檢查該狀態的版本,以確保當前狀態與背書時的版本相匹配,這就確保了世界狀態是按照預期進行更新的,沒有發生并發更新,是并發安全的,
首次創建賬本時,世界狀態是空的,因為區塊鏈上記錄了所有代表有效世界狀態更新的交易,所以任何時候都可以從區塊鏈中重新生成世界狀態,這樣一來就變得非常方便,例如,創建節點時會自動生成世界狀態,此外,如果某個節點發生例外,重啟該節點時能夠在接受交易之前重新生成世界狀態,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/277726.html
標籤:區塊鏈