點開這篇文章的人應該已經都聽說過位元幣了,如果稍有了解的人就會說位元幣挖礦是利用了雙哈希演算法SHA256,從2019年末到現在,位元幣的價格經過了喪心病狂的上漲,導致市場上礦機價格飆升,大家也都買不到顯卡了,不過顯卡的價格不是位元幣的鍋,因為顯卡已經幾乎完全挖不到位元幣了,位元幣已經完全是礦機的天下,這里我們不探討市場行為,不探討挖礦是否浪費資源,單純從可行性角度探討用FPGA挖礦
不過閱讀這篇博客的看官們請注意:這篇文章沒法幫你挖到礦,原因很簡單,現在隨便一個礦機都能到達TH/s量級,而鄙人在FPGA上實作的最高不過100MH/s,不僅速度有量級的區別,而且能量利用率也遠遠不夠,看到這里的看官如果還沒關,那說明是對實作的技術感興趣(或者就是好奇),那么客官里邊請~
FPGA應用篇【0】位元幣SHA256演算法實作——原理分析
- 哈希演算法介紹
- 初始化流程
- 主回圈
- 測驗案例
- 位元幣演算法
- 軟體代碼仿真
- 硬體架構設計
- 演算法流程圖優化
- 結論
哈希演算法介紹
哈希演算法是一種確定性的不可逆密碼函式,對于一個給定長度的字串,它能生成一個固定長度的密碼字串,如果有人改動了輸入字串中的任意一個字符,哪怕只是改了一個位置,都會導致輸出密碼串有很大的區別,由此可以用來快速確定是否有人修改了原文,位元幣挖礦演算法就是利用了哈希演算法的不可逆性和混淆特性,讓礦工不斷嘗試碰撞來得到結果,模擬挖礦的程序
在這篇英文檔案中介紹了SHA256,SHA384和SHA512三種哈希演算法的細節:Descriptions of SHA-256, SHA-384, and SHA-512
下面的內容是基于這篇檔案的翻譯和注釋內容
初始化流程
被哈希編碼的資訊首先要:
- 在資訊流末端補充資訊,直到資訊流長度為512位元的整數倍,補充的方式是先補充一位1,再補充k位0,使得最后長度對512的余數為448,最后補上64位為原始資訊流的位元長度
- 把資訊流分成512位元長的資訊塊 M ( 1 ) M^{(1)} M(1), M ( 2 ) M^{(2)} M(2)……每一個資訊快按照32bit分成16個小塊 M 0 ( i ) , . . . , M 15 ( i ) M_0^{(i)},...,M_{15}^{(i)} M0(i)?,...,M15(i)?
資訊快依次進行哈希編碼,初始哈希值為 H ( 0 ) H^{(0)} H(0),之后的編碼公式為 H ( i ) = H ( i ? 1 ) + C M ( i ) ( H ( i ? 1 ) ) H^{(i)}=H^{(i-1)}+C_{M^{(i)}}(H^{(i-1)}) H(i)=H(i?1)+CM(i)?(H(i?1))
在這里C是SHA-256壓縮方程, H ( i ) H^{(i)} H(i)是 M i M^i Mi的哈希值,而這里的加法是32bit的mod 2 32 2^{32} 232加法,例如 0 x F F F F _ F F F F + 0 x 0000 _ 0001 = 0 x 0000 _ 0000 0xFFFF\_FFFF + 0x0000\_0001=0x0000\_0000 0xFFFF_FFFF+0x0000_0001=0x0000_0000
SHA-256壓縮方程C中有幾個運算子需要提前定義,這里所有運算子針對的是32位數(原文中取反符號的定義為補碼,個人理解這里應該是取反):
| 符號 | 簡介 |
|---|---|
| ⊕ \oplus ⊕ | 按位異或 |
| ∧ \land ∧ | 按位與 |
| ∨ \lor ∨ | 按位或 |
| ? \lnot ? | 取反 |
| + | mod 2 32 2^{32} 232加法 |
| R n R^n Rn | 右移n位,高位補符號位 |
| S n S^n Sn | 回圈右移n位 |
哈希值的初始值是由初始8個素數(2,3,5,7,11,13,17,19)平方根的二進制小數部分頭32位得到的:
H
1
(
0
)
=
0
x
6
a
09
e
667
H
2
(
0
)
=
0
x
b
b
67
a
e
85
H
3
(
0
)
=
0
x
3
c
6
e
f
372
H
4
(
0
)
=
0
x
a
54
f
f
53
a
H
5
(
0
)
=
0
x
510
e
527
f
H
6
(
0
)
=
0
x
9
b
05688
c
H
7
(
0
)
=
0
x
1
f
83
d
9
a
b
H
8
(
0
)
=
0
x
5
b
e
0
c
d
19
H_1^{(0)}=0x6a09e667\\ H_2^{(0)}=0xbb67ae85\\ H_3^{(0)}=0x3c6ef372\\ H_4^{(0)}=0xa54ff53a\\ H_5^{(0)}=0x510e527f\\ H_6^{(0)}=0x9b05688c\\ H_7^{(0)}=0x1f83d9ab\\ H_8^{(0)}=0x5be0cd19
H1(0)?=0x6a09e667H2(0)?=0xbb67ae85H3(0)?=0x3c6ef372H4(0)?=0xa54ff53aH5(0)?=0x510e527fH6(0)?=0x9b05688cH7(0)?=0x1f83d9abH8(0)?=0x5be0cd19
主回圈
主要回圈的偽代碼如下:
For i = 1 to N // N是補位后的資訊快數量
{
// a,b,c,d,e,f,g,h是八個哈希狀態暫存器,每個32位元,如果是第一個資訊快,則用初始哈希值
a = H_1;
b = H_2;
c = H_3;
d = H_4;
e = H_5;
f = H_6;
g = H_7;
h = H_8;
// 使用SHA-256壓縮方程來更新八個哈希狀態
For j = 0 to 63
{
// Ch, Maj, Sig0, Sig1, K 和W會在后面介紹
T1 = h + Sig1(e) + Ch(e, f, g) + K[j] + W[j];
T2 = Sig0(a) + Maj(a, b, c);
h = g;
g = f;
f = e;
e = d + T1;
d = c;
c = b;
b = a;
a = T1 + T2;
}
// 使用八個哈希狀態來更新哈希值
H_1 = a + H_1;
H_2 = b + H_2;
...
H_8 = h + H_8;
}
H_final = {H_1, H_2,..., H_8}; // 最終結果
畫成流程圖如下
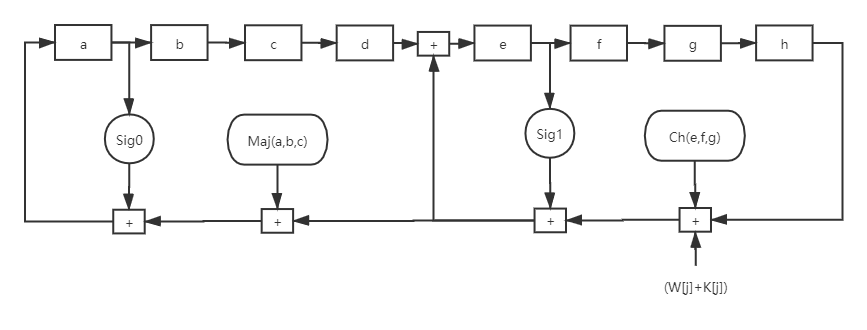
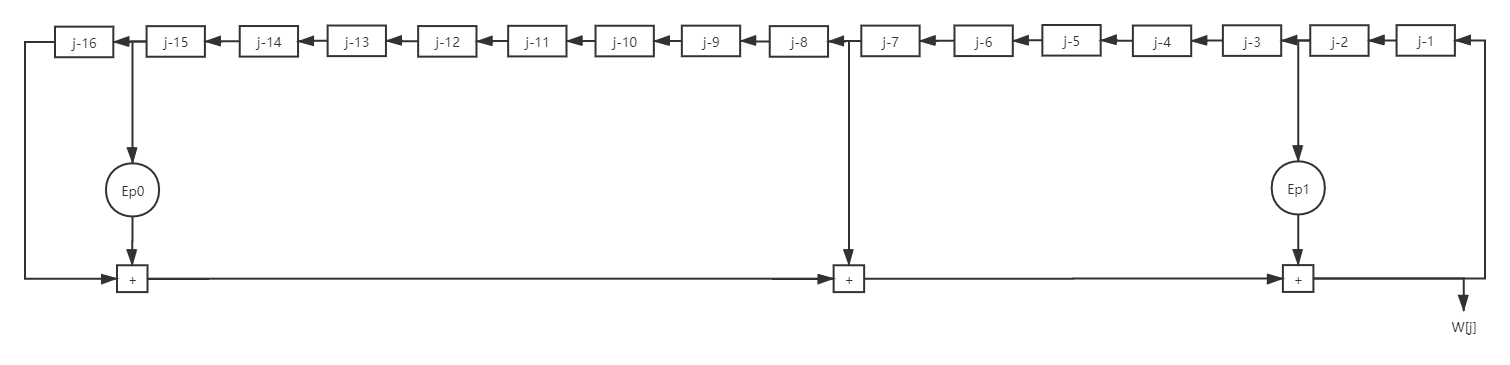
上述偽代碼中的W是擴展資訊塊,分為64份, W 0 , W 1 , . . . , W 63 W_0, W_1,...,W_{63} W0?,W1?,...,W63?,它們的計算方式偽代碼如下:
For j = 0 to 63
{
if(j=0, 1,...,15)
W[j] = M_i[j]
else
W[j] = Ep1(W[j-2]) + W[j-7] + Ep0(W[j-15]) + W[j-16]
}
其中M_i是輸入資料,W_0至W_15是直接使用輸入資料進行初始化的,輸入是512位元的資料塊,分為16塊32位元的資料塊,作為M_i,這同樣可以畫成流程圖如下
另外其中的K是一組常數,它的具體數值為(形式為{ K 0 K_0 K0?, K 1 K_1 K1?,…, K 63 K_{63} K63?}):
{
0x428a2f98,0x71374491,0xb5c0fbcf,0xe9b5dba5,0x3956c25b,0x59f111f1,0x923f82a4,0xab1c5ed5,
0xd807aa98,0x12835b01,0x243185be,0x550c7dc3,0x72be5d74,0x80deb1fe,0x9bdc06a7,0xc19bf174,
0xe49b69c1,0xefbe4786,0x0fc19dc6,0x240ca1cc,0x2de92c6f,0x4a7484aa,0x5cb0a9dc,0x76f988da,
0x983e5152,0xa831c66d,0xb00327c8,0xbf597fc7,0xc6e00bf3,0xd5a79147,0x06ca6351,0x14292967,
0x27b70a85,0x2e1b2138,0x4d2c6dfc,0x53380d13,0x650a7354,0x766a0abb,0x81c2c92e,0x92722c85,
0xa2bfe8a1,0xa81a664b,0xc24b8b70,0xc76c51a3,0xd192e819,0xd6990624,0xf40e3585,0x106aa070,
0x19a4c116,0x1e376c08,0x2748774c,0x34b0bcb5,0x391c0cb3,0x4ed8aa4a,0x5b9cca4f,0x682e6ff3,
0x748f82ee,0x78a5636f,0x84c87814,0x8cc70208,0x90befffa,0xa4506ceb,0xbef9a3f7,0xc67178f2
};
偽代碼和擴展邏輯塊計算中有六個邏輯函式Ch, Maj,
Σ
0
\Sigma_0
Σ0? (Sig0),
Σ
1
\Sigma_1
Σ1? (Sig1),
?
0
\epsilon_0
?0? (Ep0)和
?
1
\epsilon_1
?1? (Ep1),它們的計算方式如下:
C
h
(
x
,
y
,
z
)
=
(
x
∧
y
)
⊕
(
?
x
∧
z
)
M
a
j
(
x
,
y
,
z
)
=
(
x
∧
y
)
⊕
(
x
∧
z
)
⊕
(
y
∧
z
)
Σ
0
(
x
)
=
S
2
(
x
)
⊕
S
13
(
x
)
⊕
S
22
(
x
)
Σ
1
(
x
)
=
S
6
(
x
)
⊕
S
11
(
x
)
⊕
S
25
(
x
)
?
0
(
x
)
=
S
7
(
x
)
⊕
S
18
(
x
)
⊕
R
3
(
x
)
?
1
(
x
)
=
S
17
(
x
)
⊕
S
19
(
x
)
⊕
R
10
(
x
)
Ch(x, y, z) = (x\land y)\oplus (\lnot x\land z)\\ Maj(x,y,z) = (x\land y)\oplus (x\land z)\oplus (y\land z)\\ \Sigma_0(x) = S^2(x)\oplus S^{13}(x) \oplus S^{22}(x)\\ \Sigma_1(x) = S^6(x)\oplus S^{11}(x) \oplus S^{25}(x)\\ \epsilon_0(x) = S^7(x)\oplus S^{18}(x) \oplus R^3(x)\\ \epsilon_1(x) = S^{17}(x) \oplus S^{19}(x) \oplus R^{10}(x)
Ch(x,y,z)=(x∧y)⊕(?x∧z)Maj(x,y,z)=(x∧y)⊕(x∧z)⊕(y∧z)Σ0?(x)=S2(x)⊕S13(x)⊕S22(x)Σ1?(x)=S6(x)⊕S11(x)⊕S25(x)?0?(x)=S7(x)⊕S18(x)⊕R3(x)?1?(x)=S17(x)⊕S19(x)⊕R10(x)
上面所有的邏輯計算都是32位的
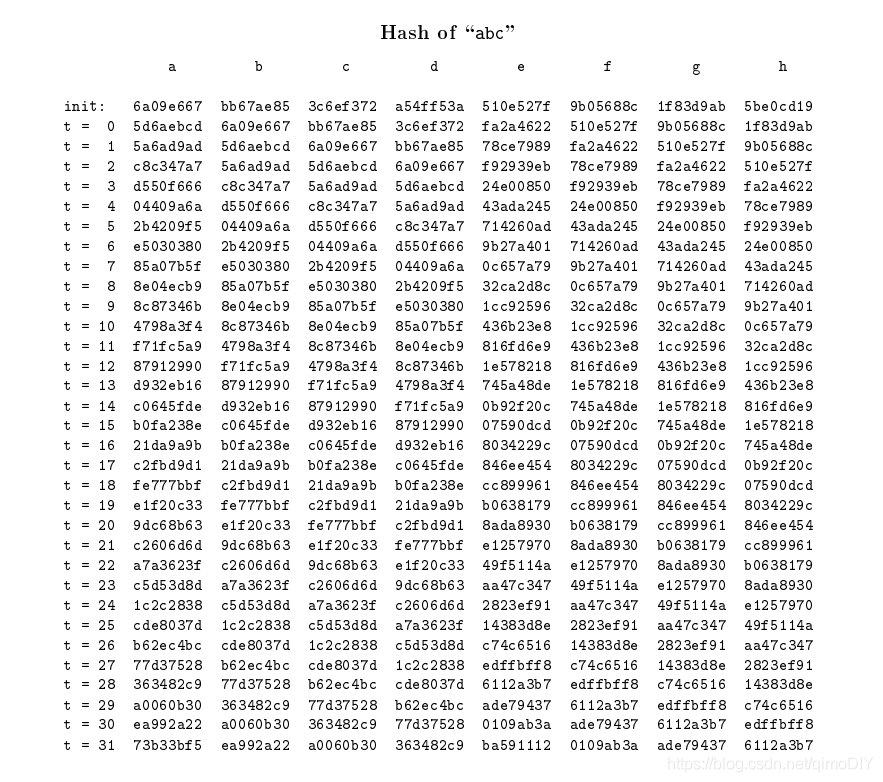
測驗案例
如果輸入字串為一個24bit的"abc",每個字符占用8個bit,則補位后的資料為
61626380 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000018
其哈希值最終結果為
ba7816bf 8f01cfea 414140de 5dae2223 b00361a3 96177a9c b410ff61 f20015ad
當中隨著時間推移,它的8個哈希狀態變化如下,可以再仿真時提供參考:

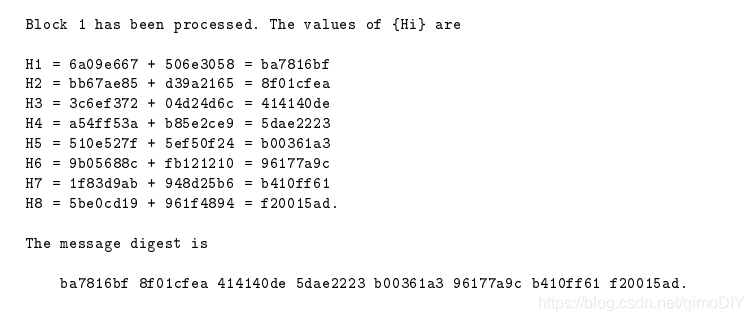
位元幣演算法
現在的加密貨幣礦工已經很少有單獨行動的,一般都通過礦池運作,從礦池獲取資料頭(608位,下一篇會介紹資料頭的獲取方式),填充32位的變數nounce,進行雙重SHA256運算,觀察結果的開頭n位是否為0,如果符合條件則將算出的結果回傳給礦池服務器,獲得收益,不過這個收益不是1個位元幣,而是按照服務器給你配置的難度系數獲得的,難度系數和結果要求的開頭n位0相關,n越大,難度越大,現在挖礦的難度要求已經非常大,至少70位,服務器會根據你的算力給你降低一定難度,使得你在一定時間內可以算出結果來(雖然算力需求也很高)
有關于挖礦演算法,可以參考知乎的這篇文章:位元幣挖礦演算法詳解
這里需要特別注意的是,位元幣挖礦演算法使用的是雙重SHA256演算法,第一重輸入為640位,計算出第一個256位中間結果;再將這256位中間結果作為輸入進入第二重SHA256演算法,得到最終的256位結果
本文給出一個輸入和輸出,以及中間結果的案例,有需要的同學甚至可以以此為參考自己寫一個邏輯:
BYTE input[] = {0x00,0x00,0x00,0x20,0xe3,0x02,0x67,0xc7,0x5d,0x2d,0x24,0xb7,0xdf,0xd8,0xb6,0x45,
0x9f,0xd8,0x37,0x44,0x79,0xd3,0xeb,0x27,0x8c,0x6a,0x0b,0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x00,0x00,0xf6,0x5c,0x34,0x24,0x2c,0x47,0x50,0x07,0x67,0xb5,0x34,0xc9,
0x49,0xc0,0xa3,0x8a,0xf4,0x99,0x07,0xb9,0x4a,0x6e,0x13,0x63,0x21,0x40,0x7c,0xbc,
0x19,0xd2,0x7e,0x62,0x87,0x07,0x2e,0x60,0xb9,0x21,0x0d,0x17,0x40,0x00,0x8b,0xf2};
BYTE middle_result[] = {0x61,0xa5,0x03,0x1b,0x3e,0x78,0x71,0xa6,
0x38,0x22,0x1c,0x99,0xc0,0xaa,0x10,0xd1,
0x2b,0x2f,0x4b,0x48,0x94,0xab,0xa3,0x5b,
0x0d,0x25,0x80,0x59,0x7d,0xe2,0x7c,0xcc};
BYTE result[] = {0x00,0x00,0x01,0xfe,0x42,0x2c,0x0e,0x30,
0x40,0xf5,0x6d,0x96,0x99,0xe2,0xfb,0xd6,
0x0f,0xbd,0x0e,0x8e,0x5d,0x64,0xfc,0x22,
0x22,0xc7,0x91,0x28,0x68,0xf1,0x7e,0x47};
可以看到最終結尾的頭20位元為0,這么設定可以讓人快速確認結果是正確的,當然實際挖礦不會讓你只有20位的
軟體代碼仿真
下面用C語言實作SHA256的基礎功能,為了凸顯演算法細節,我們這里不呼叫任何庫檔案,具體代碼參考了B-con的github并加以提取修改如下:
/*************************** HEADER FILES ***************************/
#include <stdio.h>
#include <stdlib.h>
#include <memory.h>
#include <string.h>
/****************************** MACROS ******************************/
#define SHA256_BLOCK_SIZE 32 // SHA256 outputs a 32 byte digest
#define ROTLEFT(a,b) (((a) << (b)) | ((a) >> (32-(b))))
#define ROTRIGHT(a,b) (((a) >> (b)) | ((a) << (32-(b))))
#define CH(x,y,z) (((x) & (y)) ^ (~(x) & (z)))
#define MAJ(x,y,z) (((x) & (y)) ^ ((x) & (z)) ^ ((y) & (z)))
#define EP0(x) (ROTRIGHT(x,2) ^ ROTRIGHT(x,13) ^ ROTRIGHT(x,22))
#define EP1(x) (ROTRIGHT(x,6) ^ ROTRIGHT(x,11) ^ ROTRIGHT(x,25))
#define SIG0(x) (ROTRIGHT(x,7) ^ ROTRIGHT(x,18) ^ ((x) >> 3))
#define SIG1(x) (ROTRIGHT(x,17) ^ ROTRIGHT(x,19) ^ ((x) >> 10))
/**************************** DATA TYPES ****************************/
typedef unsigned char BYTE; // 8-bit byte
typedef unsigned int WORD; // 32-bit word, change to "long" for 16-bit machines
typedef struct {
BYTE data[64];
WORD datalen;
unsigned long long bitlen;
WORD state[8];
} SHA256_CTX;
/**************************** VARIABLES *****************************/
static const WORD k[64] = {
0x428a2f98,0x71374491,0xb5c0fbcf,0xe9b5dba5,0x3956c25b,0x59f111f1,0x923f82a4,0xab1c5ed5,
0xd807aa98,0x12835b01,0x243185be,0x550c7dc3,0x72be5d74,0x80deb1fe,0x9bdc06a7,0xc19bf174,
0xe49b69c1,0xefbe4786,0x0fc19dc6,0x240ca1cc,0x2de92c6f,0x4a7484aa,0x5cb0a9dc,0x76f988da,
0x983e5152,0xa831c66d,0xb00327c8,0xbf597fc7,0xc6e00bf3,0xd5a79147,0x06ca6351,0x14292967,
0x27b70a85,0x2e1b2138,0x4d2c6dfc,0x53380d13,0x650a7354,0x766a0abb,0x81c2c92e,0x92722c85,
0xa2bfe8a1,0xa81a664b,0xc24b8b70,0xc76c51a3,0xd192e819,0xd6990624,0xf40e3585,0x106aa070,
0x19a4c116,0x1e376c08,0x2748774c,0x34b0bcb5,0x391c0cb3,0x4ed8aa4a,0x5b9cca4f,0x682e6ff3,
0x748f82ee,0x78a5636f,0x84c87814,0x8cc70208,0x90befffa,0xa4506ceb,0xbef9a3f7,0xc67178f2
};
資料定義部分結束,下面是SHA256演算法的核心部分,首先是16個資料位的更新以及8個狀態暫存器的更新函式sha256_transform()
/*********************** FUNCTION DEFINITIONS ***********************/
void sha256_transform(SHA256_CTX *ctx, const BYTE data[])
{
WORD a, b, c, d, e, f, g, h, i, j, t1, t2, W[64];
for (i = 0, j = 0; i < 16; ++i, j += 4)
W[i] = (data[j] << 24) | (data[j + 1] << 16) | (data[j + 2] << 8) | (data[j + 3]);
for ( ; i < 64; ++i)
W[i] = SIG1(W[i - 2]) + W[i - 7] + SIG0(W[i - 15]) + W[i - 16];
a = ctx->state[0];
b = ctx->state[1];
c = ctx->state[2];
d = ctx->state[3];
e = ctx->state[4];
f = ctx->state[5];
g = ctx->state[6];
h = ctx->state[7];
for (i = 0; i < 64; ++i) {
t1 = h + EP1(e) + CH(e,f,g) + k[i] + W[i];
t2 = EP0(a) + MAJ(a,b,c);
h = g;
g = f;
f = e;
e = d + t1;
d = c;
c = b;
b = a;
a = t1 + t2;
}
ctx->state[0] += a;
ctx->state[1] += b;
ctx->state[2] += c;
ctx->state[3] += d;
ctx->state[4] += e;
ctx->state[5] += f;
ctx->state[6] += g;
ctx->state[7] += h;
}
sha256_init()函式是八個狀態暫存器的初始化函式
void sha256_init(SHA256_CTX *ctx)
{
ctx->datalen = 0;
ctx->bitlen = 0;
ctx->state[0] = 0x6a09e667;
ctx->state[1] = 0xbb67ae85;
ctx->state[2] = 0x3c6ef372;
ctx->state[3] = 0xa54ff53a;
ctx->state[4] = 0x510e527f;
ctx->state[5] = 0x9b05688c;
ctx->state[6] = 0x1f83d9ab;
ctx->state[7] = 0x5be0cd19;
}
sha256_update()函式的作用是將輸入資料data分為長度為512位元的資料塊,留下最后一個長度不足512位元的資料塊等待最后操作
void sha256_update(SHA256_CTX *ctx, const BYTE data[], size_t len)
{
WORD i;
for (i = 0; i < len; ++i) {
ctx->data[ctx->datalen] = data[i];
ctx->datalen++;
if (ctx->datalen == 64) {
sha256_transform(ctx, ctx->data);
ctx->bitlen += 512;
ctx->datalen = 0;
}
}
}
最后一個資料塊需要根據總資料長度進行填充,進行最后一次更新,另外需要考慮大頭優先和小頭優先的區別,將最終資料進行轉換輸出,這些操作由sha256_final完成
void sha256_final(SHA256_CTX *ctx, BYTE hash[])
{
WORD i;
i = ctx->datalen;
// Pad whatever data is left in the buffer.
if (ctx->datalen < 56) {
ctx->data[i++] = 0x80;
while (i < 56)
ctx->data[i++] = 0x00;
}
else {
ctx->data[i++] = 0x80;
while (i < 64)
ctx->data[i++] = 0x00;
sha256_transform(ctx, ctx->data);
memset(ctx->data, 0, 56);
}
// Append to the padding the total message's length in bits and transform.
ctx->bitlen += ctx->datalen * 8;
ctx->data[63] = ctx->bitlen;
ctx->data[62] = ctx->bitlen >> 8;
ctx->data[61] = ctx->bitlen >> 16;
ctx->data[60] = ctx->bitlen >> 24;
ctx->data[59] = ctx->bitlen >> 32;
ctx->data[58] = ctx->bitlen >> 40;
ctx->data[57] = ctx->bitlen >> 48;
ctx->data[56] = ctx->bitlen >> 56;
sha256_transform(ctx, ctx->data);
// Since this implementation uses little endian byte ordering and SHA uses big endian,
// reverse all the bytes when copying the final state to the output hash.
for (i = 0; i < 4; ++i) {
hash[i] = (ctx->state[0] >> (24 - i * 8)) & 0x000000ff;
hash[i + 4] = (ctx->state[1] >> (24 - i * 8)) & 0x000000ff;
hash[i + 8] = (ctx->state[2] >> (24 - i * 8)) & 0x000000ff;
hash[i + 12] = (ctx->state[3] >> (24 - i * 8)) & 0x000000ff;
hash[i + 16] = (ctx->state[4] >> (24 - i * 8)) & 0x000000ff;
hash[i + 20] = (ctx->state[5] >> (24 - i * 8)) & 0x000000ff;
hash[i + 24] = (ctx->state[6] >> (24 - i * 8)) & 0x000000ff;
hash[i + 28] = (ctx->state[7] >> (24 - i * 8)) & 0x000000ff;
}
}
手動配置輸入和預期輸出,進行兩次sha256操作,并比對其是否與預期結果相符
int sha256_test()
{
BYTE input[] = {0x00,0x00,0x00,0x20,0xe3,0x02,0x67,0xc7,0x5d,0x2d,0x24,0xb7,0xdf,0xd8,0xb6,0x45,
0x9f,0xd8,0x37,0x44,0x79,0xd3,0xeb,0x27,0x8c,0x6a,0x0b,0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x00,0x00,0xf6,0x5c,0x34,0x24,0x2c,0x47,0x50,0x07,0x67,0xb5,0x34,0xc9,
0x49,0xc0,0xa3,0x8a,0xf4,0x99,0x07,0xb9,0x4a,0x6e,0x13,0x63,0x21,0x40,0x7c,0xbc,
0x19,0xd2,0x7e,0x62,0x87,0x07,0x2e,0x60,0xb9,0x21,0x0d,0x17,0x40,0x00,0x8b,0xf2};
BYTE expect_result[SHA256_BLOCK_SIZE] = {0x00,0x00,0x01,0xfe,0x42,0x2c,0x0e,0x30,0x40,0xf5,0x6d,0x96,0x99,0xe2,0xfb,0xd6,
0x0f,0xbd,0x0e,0x8e,0x5d,0x64,0xfc,0x22,0x22,0xc7,0x91,0x28,0x68,0xf1,0x7e,0x47};
BYTE middle_result[SHA256_BLOCK_SIZE];
BYTE final_result[SHA256_BLOCK_SIZE];
SHA256_CTX ctx;
int pass = 1;
int i;
sha256_init(&ctx);
sha256_update(&ctx, input, 80);
sha256_final(&ctx, middle_result);
printf("middle hash is: ");
for(i=0; i<32; i++) printf("%.2x", middle_result[i]);
printf("\n");
sha256_init(&ctx);
sha256_update(&ctx, middle_result, 32);
sha256_final(&ctx, final_result);
printf("final hash is: ");
for(i=0; i<32; i++) printf("%.2x", final_result[i]);
printf("\n");
pass = pass && !memcmp(expect_result, final_result, SHA256_BLOCK_SIZE);
return(pass);
}
int main()
{
printf("SHA-256 tests: %s\n", sha256_test() ? "SUCCEEDED" : "FAILED");
return(0);
}
軟體代碼和SHA256演算法介紹中的內容基本一致:
- 使用sha256_init()初始化一個哈希
- 呼叫sha256_update()將字串前部分超過512bit的部分打包成512bit的資訊塊
- 呼叫sha256_transform()更新八個哈希狀態,得到新的哈希值
- 對于剩下小于512bit的字串,呼叫sha256_final()把它補位成最后一個或者兩個資訊塊,分別呼叫sha256_transform()更新哈希狀態
- 得到最終的哈希結果后和預期的結果比較
硬體架構設計
為了讓FPGA進行SHA256演算法,我們首先要分析這個演算法在軟體架構和硬體架構的區別,先進行優化設計,FPGA和軟體邏輯區別是,硬體邏輯是并行執行的,軟體邏輯中呼叫回圈執行的操作,在FPGA中只要資源足夠就可以在一個時鐘周期內完成,因此時鐘能達到多快可以決定其哈希算力大小,我們的優化目標就是盡可能提高時鐘頻率,
演算法流程圖優化
哈希演算法中的核心是擴展資訊塊回圈和哈希狀態回圈,回圈64次可以得到最終哈希結果,假設整個哈希模塊在同一個時鐘域,也就是所有邏輯使用同一個時鐘頻率,可以到達的最高時鐘頻率是由其中最復雜的邏輯決定的,邏輯復雜度由邏輯級數和布線延遲決定,比如兩個32位數的加法比兩個16位數的加法復雜,三個32位數的加法比兩個32位數加法復雜
我們將擴展資訊塊回圈再看一次:
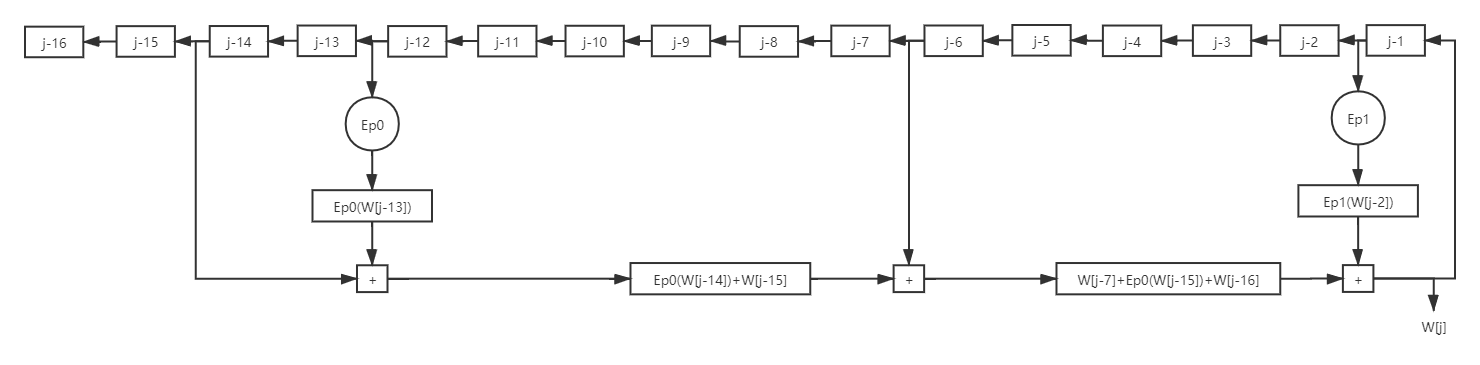
其中最復雜的邏輯就是W[j] = Ep1(W[j-2]) + W[j-7] + Ep0(W[j-15]) + W[j-16] ,四個32位數相加,其中兩個還要經過Ep0或者Ep1函式處理,我們的處理方法是通過暫存器將大塊的邏輯分割成幾個相對小的邏輯塊,我們優化的原則是,兩個相鄰暫存器之間只處理一個邏輯函式或者兩個32位數的加法,需要注意的是,每次到下一個時鐘周期,暫存器中的W[j]就會成為W[j-1],因此要移動取輸入資料的位置
修改設計如下:
t=0: tmp1[0]=Ep0(W[j-12]);
t=1: tmp2[1]=tmp1[1]+W[j-14]=Ep0(W[j-13])+W[j-14];
t=2: tmp3[2]=tmp2[2]+W[j-6]=Ep0(W[j-14])+W[j-15]+W[j-6];
tmp4[2]=Ep1(W[j-1]);
t=3: W[j]=tmp3[3]+tmp4[3]=Ep1(W[j-2])+W[j-7]+Ep0(W[j-15])+W[j-16];
這樣就把一個大的計算邏輯分割成了五個相對較小的邏輯,可以大幅度提高性能,修改后的流程圖如下
下面優化八個哈希狀態的更新,初始狀態機如下:
比較復雜的兩個計算分別是a和e的更新:
e = Sig1(e) + Ch(e,f,g) + W[j] + K[j];
a = Sig0(a) + Maj(a,b,c) + Sig1(e) + Ch(e,f,g) + W[j] + K[j];
這里我們不能再使用前面的擴展資訊塊相似的移動延遲位置的做法,因為狀態機更新中的e的輸入就包含了e的輸出,沒有空間可以操作,因此我們使用另一種思路,使用多通道架構思路來處理,示意圖如下:
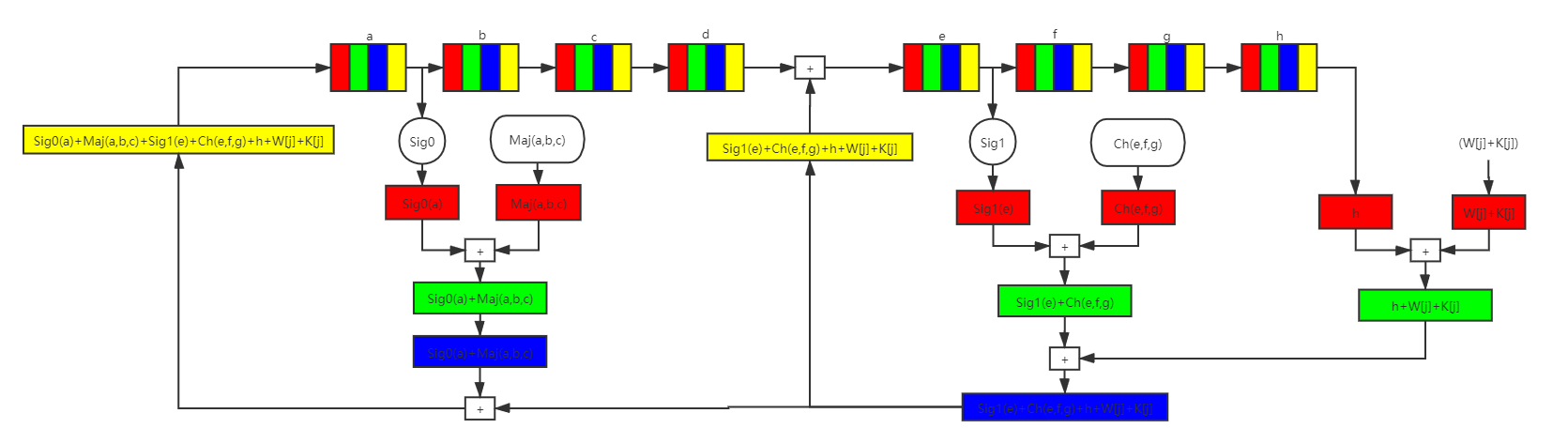
從圖中可以看到紅綠藍黃四種顏色,代表四個不同的資料通道,每個狀態機都由一個暫存器變為四個通道資料的FIFO,這樣對于一個資料通道而言,其一個資料與下一個資料之間由一個時鐘周期變為四個時鐘周期,并且剩下三個時鐘周期也沒有閑著,用來處理其他三個信道的資料
通過這種設計,讓一個時鐘處理一個資料的模式變為了四個時鐘處理四個資料,雖然看起來沒有區別,但由于兩個暫存器之間的邏輯簡化了,FPGA最終能達到的最高時鐘頻率變高,也就提高了效率
之所以這里可以這么做,是因為挖礦操作就是不停的嘗試新的資料,而不是一般加密檔案時只進行一次操作,因此可以并行處理大量資料
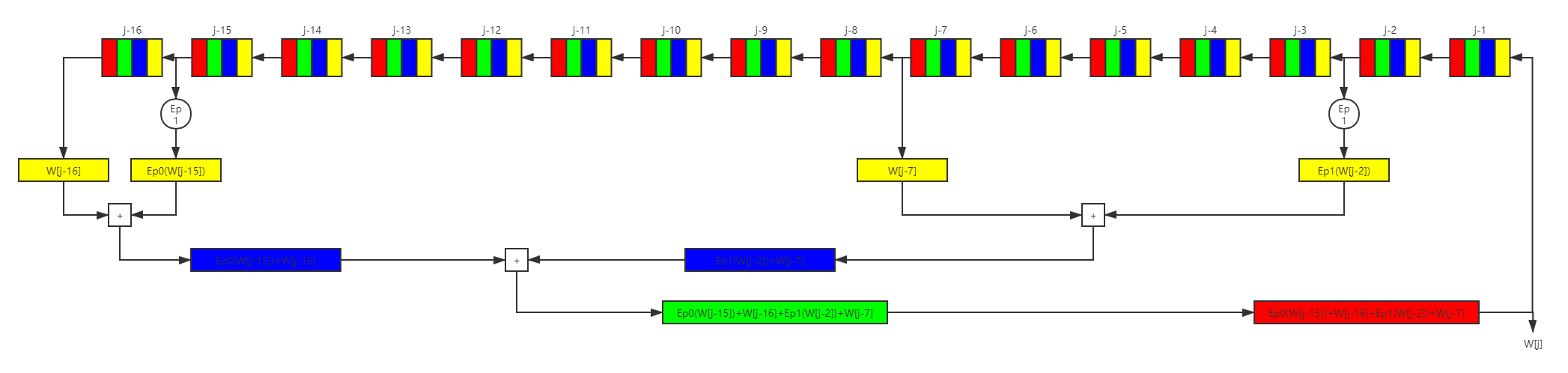
為了和狀態機更新的架構匹配,我們重新設計上面的擴展資訊塊回圈如下,設計思路一樣,就不解釋了:
結論
這一篇中分析了SHA256演算法和位元幣挖礦演算法的關系,給出了C語言的邏輯仿真,并對FPGA實作SHA256演算法的核心硬體架構進行了初步的設計,下一篇我們在此基礎上寫出相應的Verilog代碼并進行仿真
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/282357.html
標籤:區塊鏈
下一篇:【環境篇】Docker 匯出加載鏡像提示 docker: Error response from daemon: OCI runtime