在我正在進行的專案中,我正在分析兩個各有500,000行的資料集。我必須根據一個特定列的值來過濾這些行。以下是我在二維碼上編碼使用的函式:
theme_analyser <- function(tibble_to_analyse) {>
for (i in 1: nrow(tibble_to_analyse)) {
主題 < - unlist(strsplit((tibble_to_analyse$themes[i])。 " 。 "))
if (any(theme %in% themes_to_use)){
next}
else {
tibble_to_analyse <- tibble_to_analyse[-i,] /span>
}
}
}
在這個函式中,themes_to_use是一個包含一組字串值的向量。主題列需要一個以上的值,并且每個值都由"; "分隔。因此,我首先拆分這些值,然后將它們從串列中洗掉。
這段代碼的問題是,它的作業速度太慢。它在18個小時內只完成了250k行的作業。我有什么方法可以加快這個程序,使其不需要花費那么多時間呢?
假設我有一個如下的資料集 :
A B
1 "bright"
2 "shiny"/span>
3 " bright"
我想過濾這些行,所以我只得到B列等于 "明亮 "的行。我的代碼是用來選擇themes列等于價值向量中的至少一個值的行。
預先感謝你。
uj5u.com熱心網友回復:
另一種方法是使用來自tidyverse的dplyr/string:
library(tidyverse)
tibble_to_analyse%>%。
filter(str_detect(themes, paste(themes_to_use。 崩潰= "|")) # Edit, 謝謝你 @Jared_mamrot
示例資料:
set.seed(123)
n = 10000
tibble_to_analyse = tibble()
val1 = sample(c。 themes_to_use), n。 替換= TRUE),
val2 = sample(c(LETTERS。 themes_to_use), n。 替換= TRUE),
主題 = paste(val1, val2, sep = " 。 "),
值 = 1:n
)
速度有了很大的提高,但沒有@Jared_marot的基礎R解決方案快。
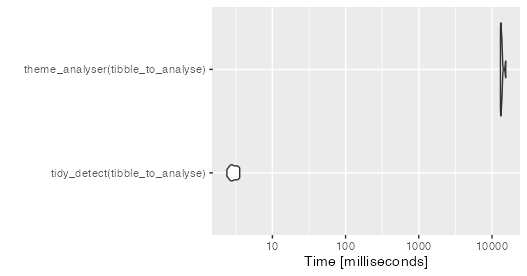
uj5u.com熱心網友回復:
如果沒有一個最小的可重復的例子,很難說這個解決方案是否合適,但是你的回圈需要這么長的時間,其中一個原因是你在回圈的每一次迭代中都在寫tibble并計算theme <- unlist(strsplit((tibble_to_analyse$themes[i]), ";"))/code>.
如果你通過向量函式來繞過這些問題,它應該會明顯地更快--下面是一個例子:
如果你通過向量函式來繞過這些問題,它應該會明顯地更快。
library(tidyverse)
set.seed(123)
df <- data. frame(themes = sample(c("one; 主題", "二;主題",
"three;theme", "four;theme"),
size = 10000。 替換= TRUE),
values = rnorm(10000))
themes_to_use < - c("one"。 "three")
theme_analyser <- function(tibble_to_analyse) {
for (i in 1: nrow(tibble_to_analyse)) {
主題 < - unlist(strsplit((tibble_to_analyse$themes[i])。 " 。 "))
if (any(theme %in% themes_to_use)){
next}
else {
tibble_to_analyse <- tibble_to_analyse[-i,] /span>
}
}
}
vectorised_theme_analyser <- function(tibble_to_analyse) {
tibble_to_analyse[which(gsub("; 。 *", "1"。 tibble_to_analyse$themes) %in% themes_to_use)。 ]
}
res <- microbenchmark:: microbenchmark(vectorised_theme_analyser(df),
theme_analyser(df))
autoplot(res)
#> 坐標系統已經存在。添加新的坐標系,它將取代現有的坐標系。
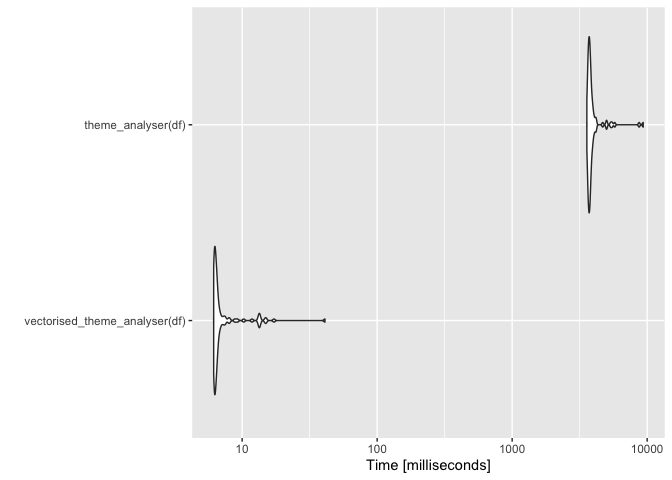
創建于2021-09-10,由reprex包(v2.0.1)
編輯
利用你問題中提供的簡化示例資料,這里有一個簡化的子集方法以及與@Jon Spring的tidy_detect方法的對比:library(tidyverse)
set.seed(123)
df <- data. frame(themes = sample(c("one"/span>。
"三", "四"),
size = 500000。 替換= TRUE),
values = rnorm(500000)
themes_to_use < - c("one"。 "three")
subset_in <- function(tibble_to_analyse) {
tibble_to_analyse[tibble_to_analyse$themes %in% themes_to_use,】
}
tidy_detect <- function(tibble_to_analyse) {
tibble_to_analyse %> %過濾(str_detect(themes, paste(themes_to_use, 崩潰= "|")))
}
res <- microbenchmark:: microbenchmark(subset_in(df),
tidy_detect(df))
autoplot(res)
#> 坐標系統已經存在。添加新的坐標系,它將取代現有的坐標系。
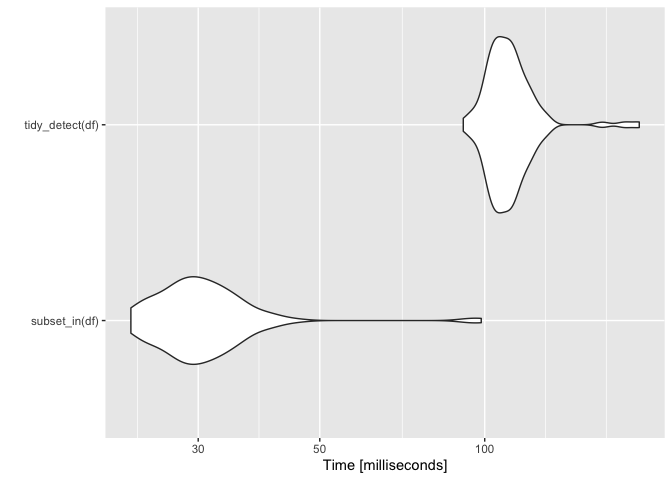
創建于2021-09-10,由reprex包(v2.0.1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/314519.html
標籤: