我創建了下面的堆疊條形圖,但代碼似乎是有效的,條形圖似乎被分成了幾片,每片都有不同的懸停,這是不必要的,而且令人困惑。我怎樣才能洗掉它們呢?
Tar2< -結構(list(Site = c("ABC123">, "ABC123", "ABC123"。 "ABC123",
"ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123")。 組 = c("A"/span>。 "A", "B"。 "B", "A", "A"。 "A", "A", "A",
"B", "B"。 "B"/span>, "B"/span>。 "B", "B", "B"。 "B", "B", "B"。 "B"/span>, "B"/span>。 "B",
"B", "A"。 "A"/span>, "B"/span>。 "B", "B", "B"。 "A", "A", "B"。 "B"/span>, "B"/span>。 "B",
"B", "B", "B"。 "B", "A"。 "A")。 病人= c(46L。 46L, 46L。 46L,
46L, 46L。 46L, 46L。 46L, 46L, 46L。 46L, 46L, 46L。 46L, 46L。 46L,
46L, 46L。 46L, 46L。 46L, 46L, 46L。 46L, 46L, 46L。 46L, 46L。 46L,
46L, 46L,, 46L, 46L, 46L。 46L, 46L, 46L。 46L)),行。 names = c(NA,)
-40L)。 class = c("tbl_df"/span>。 "tbl", "data. frame"))
library(ggplot2)
library(dplyr)
library(plotly)
c< -ggplot(Tar2, aes(fill=Group, y=Patients。 x=Site))
geom_bar(position="stack"。 stat="identity")
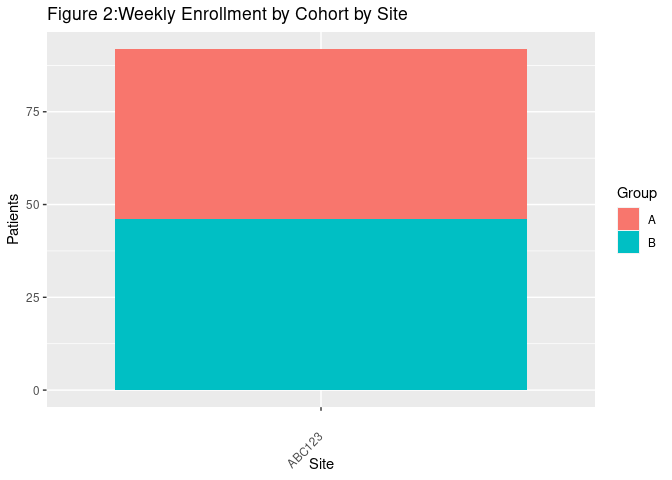
c<-c 主題(axis.text. x = element_text(angle = 45。 vjust = 0. 5。 hjust=1)) labs(title = " Figure 2: 按地點劃分的各組群的每周注冊人數"
)
ggplotly(c)
uj5u.com熱心網友回復:
你可以使用group_by和slice來獲得每組只有一條記錄:
Tar2 < -結構(list(Site = c()
"ABC123", "ABC123"。 "ABC123", "ABC123", "ABC123",
"ABC123", "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",/span> "ABC123"。 "ABC123",
"ABC123"
),集團=c()
"A"/span>, "A"/span>。 "B", "B"。 "A"/span>, "A"/span>。 "A", "A", "A",
"B", "B"。 "B"/span>, "B"/span>。 "B", "B", "B"。 "B", "B", "B"。 "B"/span>, "B"/span>。 "B",
"B", "A"。 "A"/span>, "B"/span>。 "B", "B", "B"。 "A", "A", "B"。 "B"/span>, "B"/span>。 "B",
"B", "B", "B"。 "B", "A", "A"/span>
), Patients = c()
46L,/span> 46L。 46L, 46L, 46L,
46L, 46L。 46L, 46L。 46L, 46L, 46L。 46L, 46L, 46L。 46L, 46L。 46L,
46L, 46L。 46L, 46L。 46L, 46L, 46L。 46L, 46L, 46L。 46L, 46L。 46L,
46L, 46L,, 46L, 46L。 46L, 46L。 46L, 46L, 46L
)),行。 names = c()
NA,
-40L
)。 class = c("tbl_df"/span>。 "tbl", "data. frame"))
library(tidyverse)
c <-
Tar2%>%
group_by(Group,Patients,Site) %> %
slice(1) %>%
ggplot(aes(fill =Group, y = Patients, x = Site))
geom_bar(position = "stack", 統計= "identity")
主題(axis.text。 x = element_text(angle = 45。 vjust = 0. 5, hjust = 1))
實驗室(title = "Figure 2:Weekly Enrollment by Cohort by Site")
c
創建于2021-09-14,由reprex包(v2.0.1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/318915.html
標籤: