原文標題:Index Design of Electronic Medical Record Database Using Blockchain
原文作者:Jingwen Li,Jian Wang
原文地址:DOI 10.1109/ICMCCE51767.2020.00438
發表會議:2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE)
筆記整理:doxbwx@163,com
1.簡介
電子簡歷(EMR)是一種高度敏感的醫療資料,存盤在傳統的SQL資料庫中,很容易因為資料庫的開放資料訪問而導致資料被篡改,利用區塊鏈的防篡改、可追溯、高共享等特點,與傳統資料庫方便查詢用戶資料的特點相結合,在保證醫療資料存盤安全的情況下,方便用戶查詢檢索,主要作出了以下幾個方面的貢獻:
- 作者設計了一個專門用于存盤EMR的區塊鏈系統
- 根據EMR的欄位特征,設計了一個資料庫表,用三種結構建立聚類索引和非聚類索引
- 基于資料庫表的索引結構,用戶可以在單欄位或多欄位組合中進行資料查詢,
預備內容
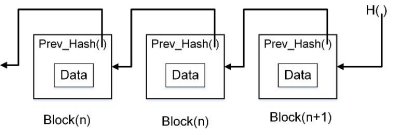
1.一般區塊鏈結構如下圖所示
區塊鏈可以理解為一種分布式的資料庫,它由多個區塊按時間順序鏈接在一起組成的p2p網路,
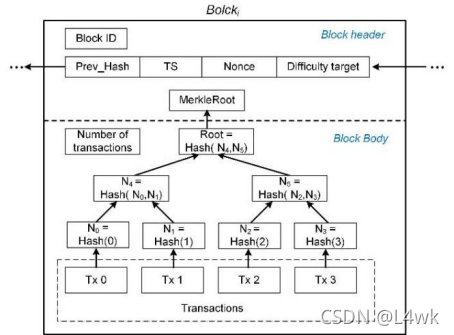
2.資料庫中的索引
索引可以分為聚集索引和非聚集索引,
聚集索引可以通過主鍵值直接找到需要的資料,非聚集索引只能找到對應的主鍵值,然后再通過聚集索引中的主鍵找到最終的資料,兩者之間的關系如下圖所示,
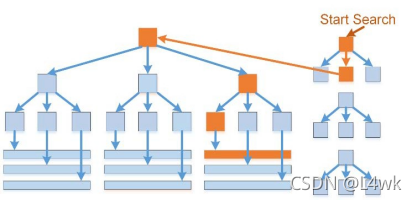
常見的索引結構包括有B-樹,B+樹和bitmap index
B樹:由下圖所示,是一個M叉搜索樹
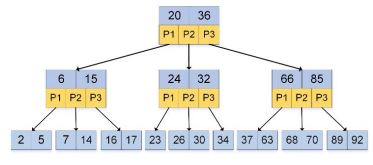
- num(根節點的子節點) = [2,M]
2. 除根節點外,num(非葉子節點的子樹)=[M/2,M]
3. num(非葉子節點的關鍵字)=num(指向子節點的指標)-1
4. 非葉子節點的關鍵字K[1], K[2], … , K[M-1], 并且K[i] < K[i+1]
5. 非葉子節點P[1],P[2],… ,P[M]的指標,其中P[1]指向關鍵字小于K[1]的子樹,P[M]指向關鍵字大于K[M-1]的子樹,其他P[i]指向關鍵字屬于(K[i-1],K[i])的子樹
6. 所有葉子節點都在同一層
B+樹:如下圖所示,與B-樹基本相同,差別在于
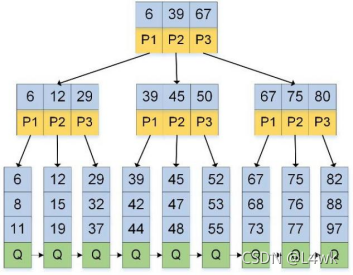
1.對于非葉節點,num(指向子節點的指標)=num(關鍵字)
2.非葉子節點作為索引,葉子節點存盤關鍵詞的資料記錄
3.所有葉子節點形成一個有序的鏈表,這對范圍查詢很方便
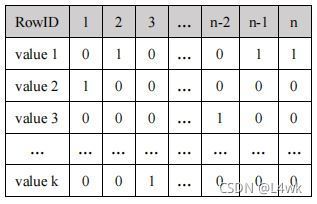
位圖索引:適用于一個欄位只有幾個固定的值
方案
作者把方案分為三個部分
- 用于存盤醫療資料的區塊鏈資料庫
- 面向用戶的資料庫
- 建立索引和查詢
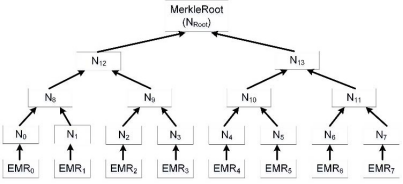
把資料存入EMR表中,并把它當作一個資料塊,把資料塊的哈希結果作為葉子節點的哈希值傳入,
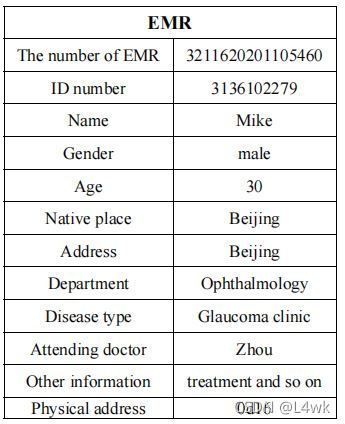
面向用戶的資料庫各欄位定義為下圖所示
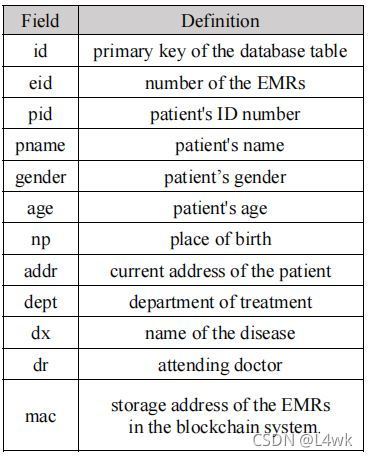
建立索引
//在表patient_info(id)上創建聚類索引index_id
create unique index index_id on patient_info(id);
//在表patient_info(pid)上創建非聚類索引index_pid
create index index_id on patient_info(pid);
//在表patient_info(gender)上創建非聚類索引index_gender
create index index_gender on patient_info(gender);
//在表patient_info(dr)上創建非聚類索引index_dr
create index index_dr on patient_info(dr);
在主鍵上建立index_id索引,則B+樹上葉子節點不僅存盤節點的鍵值,還存盤資料行資訊,從資料行資訊中可以找到EMR的物理地址,再從區塊鏈資料庫中下載EMR進行哈希處理,兩者相比較,相等則沒被篡改,
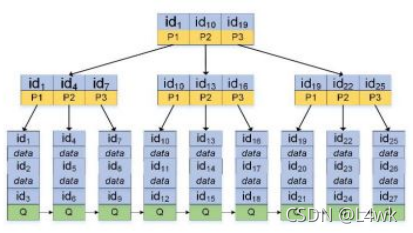
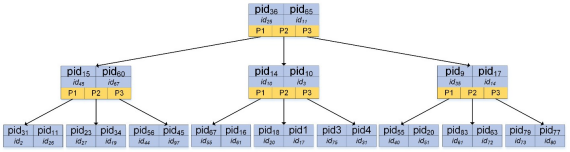
使用B樹結構建立”index_pid“索引,因為每個病人都有id,所以每個節點都包含pid、id以及指標,檢索到滿足條件的pid后可以得到id,通過id再聚類索引葉子節點,
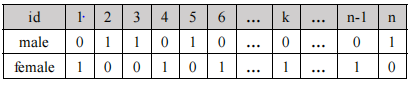
”gender“和"dr"欄位重復率高,所以使用位圖索引,當查詢到性別為male時,male的向量為011010…等,再使用id滿足該向量為1,繼續在聚類索引樹中查詢,直到葉子節點滿足條件為止,
檢索演算法
單欄位查詢陳述句
//在表patient_info(id)上創建聚類索引index_id
create unique index index_id on patient_info(id);
//在表patient_info(pid)上創建非聚類索引index_pid
create index index_id on patient_info(pid);
//在表patient_info(gender)上創建非聚類索引index_gender
create index index_gender on patient_info(gender);
多欄位組合查詢陳述句
//在表patient_info(dr)上創建非聚類索引index_dr
create index index_dr on patient_info(dr);
性能分析
用戶輸入一個查詢條件時,主鍵將被非聚類索引找到,然后資料行也將通過聚集索引使用主鍵進行查詢,這種情況下,索引的時間復雜性可以分為下面兩種情況,
- Time1 = Time(Bitmap) + Time(B+Tree)
O1 = O(1) +O(log N) = O(log N) - Time2 = Time(B-Tree) + Time(B+Tree)
O2 = O(log N) + O(log N) = O(log N)
當用戶輸入多個條件查詢,主鍵被幾個非聚集索引找到,然后通過聚集索引進行查詢,
- Time3 = Time(B-Tree) + Time(B+Tree) + Time(Bitmap)
O3 = mO(log N) + O(log N) + nO(1) = O(log N)
所以,平均時間復雜度為O(log N)
結論
作者建了一個專門用于存盤EMR的區塊鏈資料庫,然后使用B-tree、B+tree和bitmap索引來建立資料庫表的聚類索引和非聚類索引,可以滿足用戶不同的查詢需求,可以準確地、快速地檢索到EMR,作者將區塊鏈資料庫與傳統SQL資料庫結合,既滿足了用戶查詢需求,又保證了EMR的安全性,但是該方案還有待改進,多欄位的條件租合查詢,還需要使用多個查詢陳述句或嵌套陳述句來實作,時間成本還有待減少并且區塊鏈資料庫中用于存盤EMR的Merkle樹應該還可以改進,并且作者提出的該方案還沒有經過實驗論證,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/319883.html
標籤:區塊鏈
下一篇:2021-10-15