我有一項日常任務,需要比較兩個 .csv 檔案,這些檔案包含有關用戶的資料以及分配給他們的鍵集。我每天都會通過電子郵件收到新的 .csv 檔案,并檢查添加或洗掉了哪些用戶,并查看哪些用戶的密鑰集已更改。每個檔案上大約有 1000 個用戶。我已經設定了兩個檔案位于電源查詢運行所在的檔案夾中的位置。這是我的第一個專案,所以我正在看看它是否可以用于此目的。
我玩了電源查詢并能夠顯示串列用戶之間的差異。我匯入并轉換了資料,洗掉了不必要的列,將用戶列分組以計算該列中每個名稱的數量,如果找到兩個,則取消選擇它們。這向我展示了差異,但缺乏我試圖達到的比較。
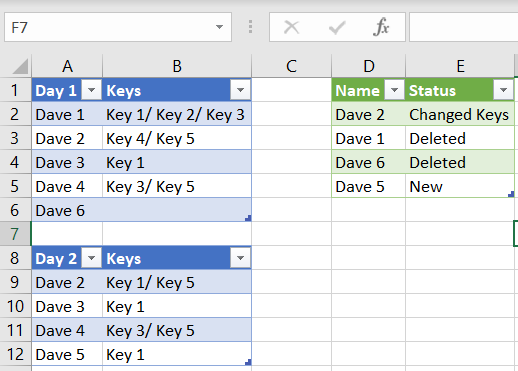
我計劃嘗試其他方法,但對 power query 可以做的所有事情都沒有經驗。我制作了一個測驗資料集,看看是否有人對如何創建此報告有一個好主意
| 第一天 | 鑰匙 |
|---|---|
| 戴夫 1 | 鍵 1/ 鍵 2/ 鍵 3 |
| 戴夫 2 | 鍵 4/ 鍵 5 |
| 戴夫 3 | 關鍵 1 |
| 戴夫 4 | 鍵 3/ 鍵 5 |
| 第 2 天 | 鑰匙 |
|---|---|
| 戴夫 2 | 鍵 1/ 鍵 5 |
| 戴夫 3 | 關鍵 1 |
| 戴夫 4 | 鍵 3/ 鍵 5 |
| 戴夫 5 | 關鍵 1 |
結果應該顯示 Dave 1 被洗掉,Dave 5 被添加,Dave 2 有一個鍵更改并顯示鍵的更改。
如果有人有關于如何創建它的想法,請告訴我或指出我在哪里可以找到結果的方向。我只能在我的作業計算機上訪問 excel,所以我試圖找到一種方法來使用可用的軟體,而不是說服老板購買任何新的東西。
uj5u.com熱心網友回復:
教程化答案
此方法從名為Key Files的檔案夾中收集資料,該檔案夾包含一組每日 csv 檔案。它將檔案夾中的每個檔案匯總為一個標準化的從一天到第二天的更改事件表:
- 已洗掉 - 名稱已被洗掉
- 新 - 名稱已添加
- 已添加密鑰 - 名稱已添加密鑰
- Key Removed - name has key removed 輸出表將包含四個欄位:
- 日期 - 取自 CSV
- 名稱 - 與事件相關
- 事件 - 按上述定義計算
- Key - 如果添加或洗掉了一個鍵,否則為 null
步驟 1 - 從檔案夾中獲取檔案
因為您還詢問了如何將資料匯入 Power Query,這里有一個說明。一旦你看到它是如何完成的,你就可以研究更多這樣的技術,然后從那里開始。我將 csv 檔案放入我的Documents檔案夾中名為Key Files 的檔案夾中以供說明。我制作了三個檔案,以便示例清晰。
作為參考,這些檔案包含以下資料:
keyfile0.csv |15/10/2021|密鑰| |:--- |:--- | |戴夫 0|鍵 2/ 鍵 3| |戴夫 1|鑰匙 1/ 鑰匙 2/ 鑰匙 3| |戴夫 2|鑰匙 4/ 鑰匙 5| |戴夫 3|關鍵 5| |戴夫 4|關鍵 3/ 關鍵 5|
keyfile1.csv |16/10/2021|密鑰| |:--- |:--- | |戴夫 1|鑰匙 1/ 鑰匙 2/ 鑰匙 3| |戴夫 2|鑰匙 4/ 鑰匙 5| |戴夫 3|關鍵 1| |戴夫 4|關鍵 3/ 關鍵 5| |戴夫 6|鑰匙 2/ 鑰匙 3|
keyfile2.csv |17/10/2021|密鑰| |:--- |:--- | |戴夫 2|鑰匙 1/ 鑰匙 5| |戴夫 3|關鍵 1| |戴夫 4|關鍵 3/ 關鍵 5| |戴夫 5|關鍵 1| |戴夫 6|關鍵 3/ 關鍵 5|
要獲取這些檔案,您需要從“資料”選項卡中獲取資料>>“來自檔案夾**” ,如下所示:
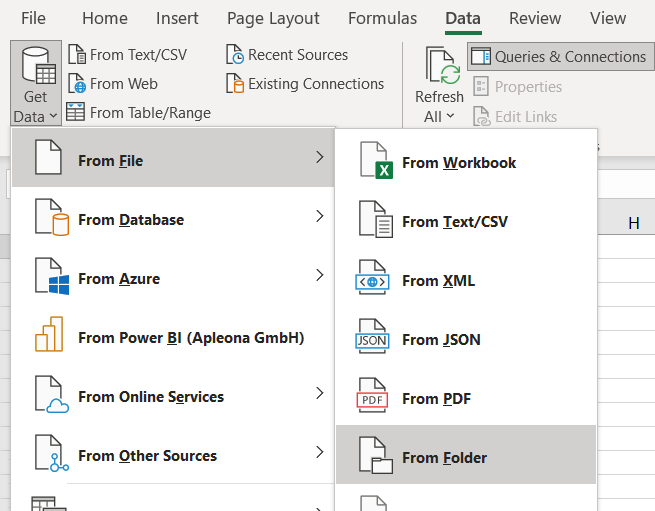
我在這個例子中的測驗檔案夾路徑是: C:\Users\Admin\Documents\Key Files
You can also get file From Text/CSV, but if your two CSV files will have constantly changing names, you would need to modify your Power Query Script each time you run it. From the description in your comments, I think it would be easier to put all csv's into a folder and let the script adapt.
You will be given a window that looks like this:
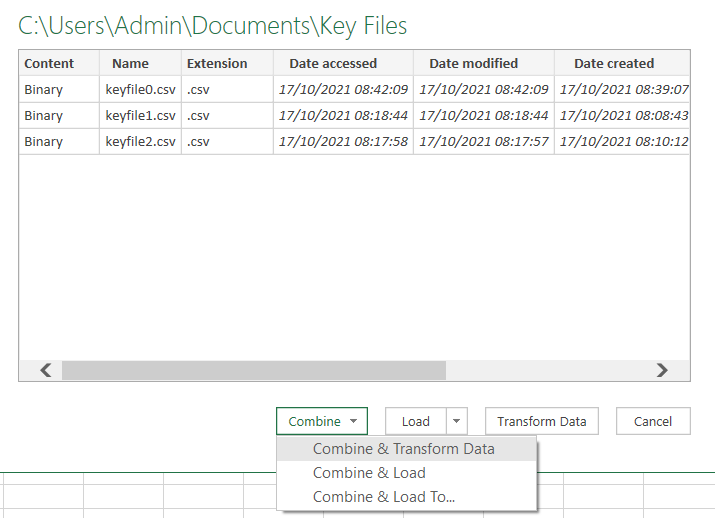
You will want to choose Combine & Transform Data. After that, it will bring up a table based on the first file it sees and you can click OK. Now this needs an explanation - PQ created a script and a function to read all of the files in that folder and append them into a single table. This approach lets you eat all of the files at once and never worry about their names. The price you pay for this convenience is that you have to split these back into logical day values as you can see from this screenshot Key Files table:
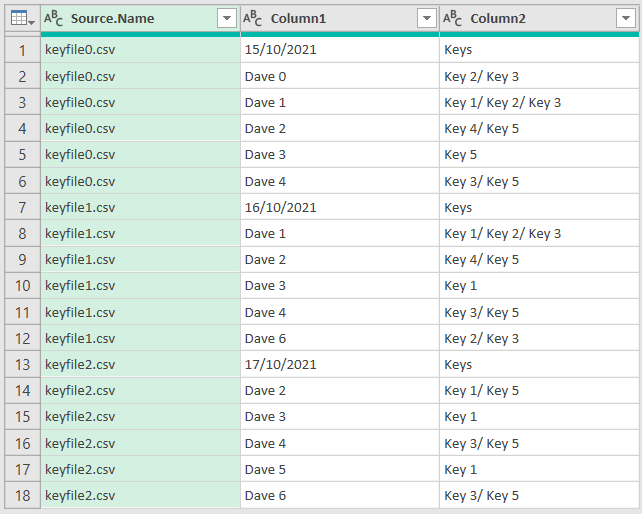
Somehow, row 8 has to be matched against row 3 to see if Dave 1 changed keys and then you need to be able to detect that on 17 Oct, Dave 1 was deleted. At the same time, Dave 2 in row 14 needs to be compared to Dave 2 in row 9 and NOT in row 4. So you need some way of knowing the sequence of days. Either:
- the filenames must be serialized in some order OR
- your header Day 1, Day 2, etc. must have a serialized value like the actual dates.
I have chosen 2 because I cannot guess at how your filenames will be structured and 2 is harder to implement, so it is better for a tutorialized answer. I will do that in the next step, so let's stop here and show the script that creates the Key Files table above:
let
Source = Folder.Files("C:\Users\Admin\Documents\Key Files"),
#"Filtered Hidden Files1" = Table.SelectRows(Source, each [Attributes]?[Hidden]? <> true),
#"Invoke Custom Function1" = Table.AddColumn(#"Filtered Hidden Files1", "Transform File", each #"Transform File"([Content])),
#"Renamed Columns1" = Table.RenameColumns(#"Invoke Custom Function1", {"Name", "Source.Name"}),
#"Removed Other Columns1" = Table.SelectColumns(#"Renamed Columns1", {"Source.Name", "Transform File"}),
#"Expanded Table Column1" = Table.ExpandTableColumn(#"Removed Other Columns1", "Transform File", Table.ColumnNames(#"Transform File"(#"Sample File"))),
#"Changed Type" = Table.TransformColumnTypes(#"Expanded Table Column1",{{"Source.Name", type text}, {"Column1", type text}, {"Column2", type text}})
in
#"Changed Type"
Step 2 - Transform the Key File Table As shown above, this step is required simply because of the choice above to read from a folder. If I were to do this in practice, instead of as a tutorial, I would streamline this, but instead, I will do it in separable steps. For illustration, I am going to create two tables from the Key Files table:
- filedates contains the file name and an associated date
- nTable is the normalized table that will be used in the final step to deliver the calculated outcomes.
To create these, right-click the Key Files table and select Reference.
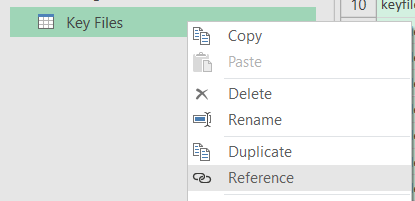 Do this twice. It will create two tables called Key Files (2) and Key Files (3).
Do this twice. It will create two tables called Key Files (2) and Key Files (3).
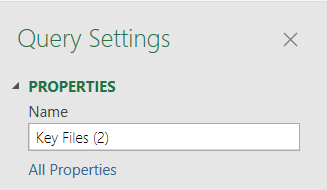 Rename these to filedates and nTable. Each of these must be transformed. I won't go into the details as that would make this a lot longer post, but here is the M script for each:
Rename these to filedates and nTable. Each of these must be transformed. I won't go into the details as that would make this a lot longer post, but here is the M script for each:
For filedates you just want to make a table of filenames and their dates. There are many ways to do that, but I just filtered for the work "Keys" because it computes fast.
let
Source = #"Key Files",
#"Filtered Rows" = Table.SelectRows(Source, each ([Column2] = "Keys"))
in
#"Filtered Rows"
For nTable you want to remove the "Keys" headers and then merge the result back with filedates so that you can have a serialized reference. As stated above, I chose to use the Date as the serial reference. I then split the Keys by row and renamed/removed columns.
let
Source = #"Key Files",
#"Filtered Rows" = Table.SelectRows(Source, each ([Column2] <> "Keys")),
#"Merged Queries" = Table.NestedJoin(#"Filtered Rows", {"Source.Name"}, filedates, {"Source.Name"}, "filedates", JoinKind.LeftOuter),
#"Expanded filedates" = Table.ExpandTableColumn(#"Merged Queries", "filedates", {"Column1"}, {"filedates.Column1"}),
#"Renamed Columns" = Table.RenameColumns(#"Expanded filedates",{{"filedates.Column1", "Date"}, {"Column1", "Name"}, {"Column2", "Keys"}}),
#"Changed Type" = Table.TransformColumnTypes(#"Renamed Columns",{{"Date", type date}}),
#"Removed Columns" = Table.RemoveColumns(#"Changed Type",{"Source.Name"}),
#"Split Column by Delimiter" = Table.ExpandListColumn(Table.TransformColumns(#"Removed Columns", {{"Keys", Splitter.SplitTextByDelimiter("/ ", QuoteStyle.Csv), let itemType = (type nullable text) meta [Serialized.Text = true] in type {itemType}}}), "Keys"),
#"Changed Type1" = Table.TransformColumnTypes(#"Split Column by Delimiter",{{"Keys", type text}}),
#"Trimmed Text" = Table.TransformColumns(#"Changed Type1",{{"Keys", Text.Trim, type text}})
in
#"Trimmed Text"
The result of nTable looks like this:
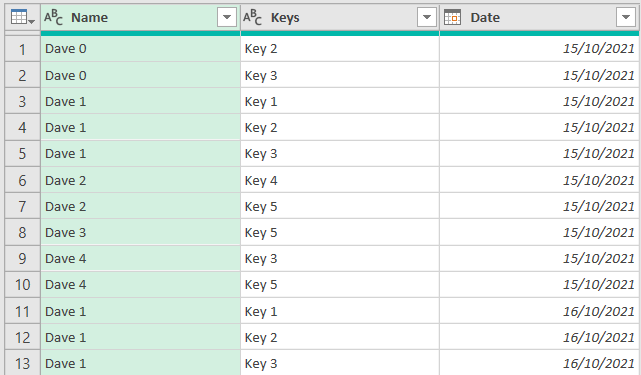
Step 3 - Calculating the Result So this is the answer to your question. Again, I will produce it as a separate step for illustration and modularity.
NB: this is where Ron Rosenfeld said you could simply push this out and then do all the processing in Excel. The remaining steps are complex. I did not create PQ Functions because it would be harder to show and understand. This is more of a tutorial to see how you could do things. With more Power Query knowledge, you can modify this to suit your needs.
The following is the M script that takes in the nTable and produces a table I named output. You can go into Advanced Editor and paste this as a new source. Afterwards you can Close & Load To your Excel sheet to see the table results.
let
Source = nTable,
SortedNTable = Table.Sort(Source,{{"Name", Order.Ascending}, {"Keys", Order.Ascending}, {"Date", Order.Ascending}}),
UniqueNameDates = Table.Distinct(SortedNTable, {"Name", "Date"}),
CalculatedLatest = List.Max(SortedNTable[Date]), //
CalculatedEarliest = List.Min(SortedNTable[Date]),
NamesFirstSeen = Table.Group(SortedNTable, {"Name"}, {{"Date", each List.Min([Date]), type nullable date}}),
NamesAdded = Table.AddColumn(NamesFirstSeen, "Event", each "Added"),
NamesLastSeen = Table.Group(SortedNTable, {"Name"}, {{"LSDate", each List.Max([Date]), type nullable date}}),
NamesDeleted = Table.AddColumn(NamesLastSeen, "Event", each "Deleted"),
AdjNamesDeleted = Table.AddColumn(NamesDeleted, "Date", each Date.AddDays([LSDate],1)), //names are deleted on the day after last seen
NameKeysFirstSeen = Table.Group(SortedNTable, {"Name", "Keys"}, {{"Date", each List.Min([Date]), type nullable date}}),
KeysAdded = Table.AddColumn(NameKeysFirstSeen, "Event", each "Key Added"),
NameKeysLastSeen = Table.Group(SortedNTable, {"Name", "Keys"}, {{"LSDate", each List.Max([Date]), type nullable date}}),
KeysDeleted = Table.AddColumn(NameKeysLastSeen, "Event", each "Key Deleted"),
AdjKeysDeleted = Table.AddColumn(KeysDeleted, "Date", each Date.AddDays([LSDate],1)), //keys are deleted on the day after last seen
// bring it all together
#"Appended Query" = Table.Combine({NamesAdded, AdjNamesDeleted, KeysAdded, AdjKeysDeleted}),
#"Removed Columns" = Table.RemoveColumns(#"Appended Query",{"LSDate"}),
//filter out first day adds and last day deletes
#"Filtered Rows" = Table.SelectRows(#"Removed Columns", each [Date] <> CalculatedEarliest or not Text.Contains([Event], "Added")),
#"Filtered Rows1" = Table.SelectRows(#"Filtered Rows", each [Date] <> Date.AddDays(CalculatedLatest,1) or not Text.Contains([Event], "Deleted")),
#"Changed Type" = Table.TransformColumnTypes(#"Filtered Rows1",{{"Name", type text}, {"Date", type date}, {"Event", type text}, {"Keys", type text}}),
#"Sorted Rows" = Table.Sort(#"Changed Type",{{"Name", Order.Ascending}, {"Date", Order.Ascending}})
in
#"Sorted Rows"
The script above uses logical variable names in order to make the steps clear and it has some limited // comments inside. Pasting it into the advanced editor (after you have done Steps 1 & 2) will let you see it more clearly and examine the output table at each step.
Summary
Here is the result based on the fake data I made above:
| Name | Date | Event | Keys |
|---|---|---|---|
| Dave 0 | 16/10/2021 | Deleted | |
| Dave 0 | 16/10/2021 | Key Deleted | Key 3 |
| Dave 0 | 16/10/2021 | Key Deleted | Key 2 |
| Dave 1 | 17/10/2021 | Deleted | |
| Dave 1 | 17/10/2021 | Key Deleted | Key 3 |
| Dave 1 | 17/10/2021 | Key Deleted | Key 2 |
| Dave 1 | 17/10/2021 | Key Deleted | Key 1 |
| Dave 2 | 17/10/2021 | Key Added | Key 1 |
| Dave 2 | 17/10/2021 | Key Deleted | Key 4 |
| Dave 3 | 16/10/2021 | Key Added | Key 1 |
| Dave 3 | 16/10/2021 | Key Deleted | Key 5 |
| Dave 5 | 17/10/2021 | Added | |
| Dave 5 | 17/10/2021 | Key Added | Key 1 |
| Dave 6 | 16/10/2021 | Added | |
| Dave 6 | 16/10/2021 | Key Added | Key 2 |
| Dave 6 | 16/10/2021 | Key Added | Key 3 |
| Dave 6 | 17/10/2021 | Key Deleted | Key 2 |
| Dave 6 | 17/10/2021 | Key Added | Key 5 |
So, as Ron pointed out in the comments, that last step is very involved. It delivers the events in a way that matches your criteria, but it may still not be exactly what you are looking for. In any case, this 3 step approach allows you to dump all of the CSV files that you want to process into a single folder and then process all of them, no matter how large or how many there are.
Here is the previous answer which is quite simplistic, but shows the basic idea.
Basic Answer
To produce the M code in Power Query that mimics your situation, I am using Table1 as the Day1 table and Table2 as the Day2 table. Assuming that you have ingested these into Power Query, the script could be:
let
Source = Table.NestedJoin(Table2, {"Day 2"}, Table1, {"Day 1"}, "Table1", JoinKind.FullOuter),
#"Expanded Table1" = Table.ExpandTableColumn(Source, "Table1", {"Day 1", "Keys"}, {"Table1.Day 1", "Table1.Keys"}),
#"Added Conditional Column" = Table.AddColumn(#"Expanded Table1", "Status", each if [Day 2] = null then "Deleted" else if [Table1.Day 1] = null then "New" else if [Keys] <> [Table1.Keys] then "Changed Keys" else null),
#"Filtered Rows" = Table.SelectRows(#"Added Conditional Column", each ([Status] <> null)),
#"Added Conditional Column1" = Table.AddColumn(#"Filtered Rows", "Name", each if [Status] = "New" then [Day 2] else null),
#"Merged Columns" = Table.CombineColumns(#"Added Conditional Column1",{"Name", "Table1.Day 1"},Combiner.CombineTextByDelimiter("", QuoteStyle.None),"Name"),
#"Removed Other Columns" = Table.SelectColumns(#"Merged Columns",{"Name", "Status"})
in
#"Removed Other Columns"
This does a full outer join of the two tables, then it used a conditional column to determine if each row is either New, Deleted, Changed Keys or no change (null). It then filters out the no change and applies another conditional column to identify the New instances and copies the name from Day2. It merges that conditional column with the Table1.Day1 names to make a consolidated list of names. It removes the unnecessary columns and you are left with a normalized table of names and status. I don't know how you want it presented, but with such a normalized table, you can either further shape it in Power Query or in Excel.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/323733.html
上一篇:用戶表單中幾個命令按鈕的唯一代碼