我想為 mysql 資料庫中的所有列找到唯一計數和空百分比以進行資料發現(近似為空/不同的表也可以)。Postgres 有包含 null_frac 和 n_distinct 欄位的 pg_stats 表,mysql 中是否有包含類似統計資訊的表?不希望通過所有列運行此查詢。
SELECT COUNT( DISTINCT col1) FROM table1;
這是一個示例資料:
CREATE TABLE employees (
employeeNumber INT NOT NULL,
lastName VARCHAR(50) NOT NULL,
firstName VARCHAR(50) NOT NULL,
extension VARCHAR(10) NOT NULL,
email VARCHAR(100) NOT NULL,
officeCode VARCHAR(10) NOT NULL,
reportsTo INT DEFAULT NULL,
jobTitle VARCHAR(50) NOT NULL,
PRIMARY KEY (employeeNumber)
) ;
INSERT INTO employees(employeeNumber,lastName,firstName,extension,email,officeCode,reportsTo,jobTitle) VALUES
(1002,'Murphy','Diane','x5800','[email protected]','1',NULL,'President'),
(1056,'Patterson','Mary','x4611','[email protected]','1',1002,'VP Sales'),
(1076,'Firrelli','Jeff','x9273','[email protected]','1',1002,'VP Marketing'),
(1088,'Patterson','William','x4871','[email protected]','6',1056,'Sales Manager (APAC)'),
(1102,'Bondur','Gerard','x5408','[email protected]','4',1056,'Sale Manager (EMEA)'),
(1143,'Bow','Anthony','x5428','[email protected]','1',1056,'Sales Manager (NA)'),
(1165,'Jennings','Leslie','x3291','[email protected]','1',1143,'Sales Rep'),
(1166,'Thompson','Leslie','x4065','[email protected]','1',1143,'Sales Rep'),
(1188,'Firrelli','Julie','x2173','[email protected]','2',1143,'Sales Rep'),
(1216,'Patterson','Steve','x4334','[email protected]','2',1143,'Sales Rep'),
(1286,'Tseng','Foon Yue','x2248','[email protected]','3',1143,'Sales Rep'),
(1323,'Vanauf','George','x4102','[email protected]','3',1143,'Sales Rep'),
(1337,'Bondur','Loui','x6493','[email protected]','4',1102,'Sales Rep'),
(1370,'Hernandez','Gerard','x2028','[email protected]','4',1102,'Sales Rep'),
(1401,'Castillo','Pamela','x2759','[email protected]','4',1102,'Sales Rep'),
(1501,'Bott','Larry','x2311','[email protected]','7',1102,'Sales Rep'),
(1504,'Jones','Barry','x102','[email protected]','7',1102,'Sales Rep'),
(1611,'Fixter','Andy','x101','[email protected]','6',1088,'Sales Rep'),
(1612,'Marsh','Peter','x102','[email protected]','6',1088,'Sales Rep'),
(1619,'King','Tom','x103','[email protected]','6',1088,'Sales Rep'),
(1621,'Nishi','Mami','x101','[email protected]','5',1056,'Sales Rep'),
(1625,'Kato','Yoshimi','x102','[email protected]','5',1621,'Sales Rep'),
(1702,'Gerard','Martin','x2312','[email protected]','4',1102,'Sales Rep');
這是能夠使用 pg_stats 表(特別是 num_null 和 num_of_distinct 列)從 postgres 獲得的預期輸出 postgres 中的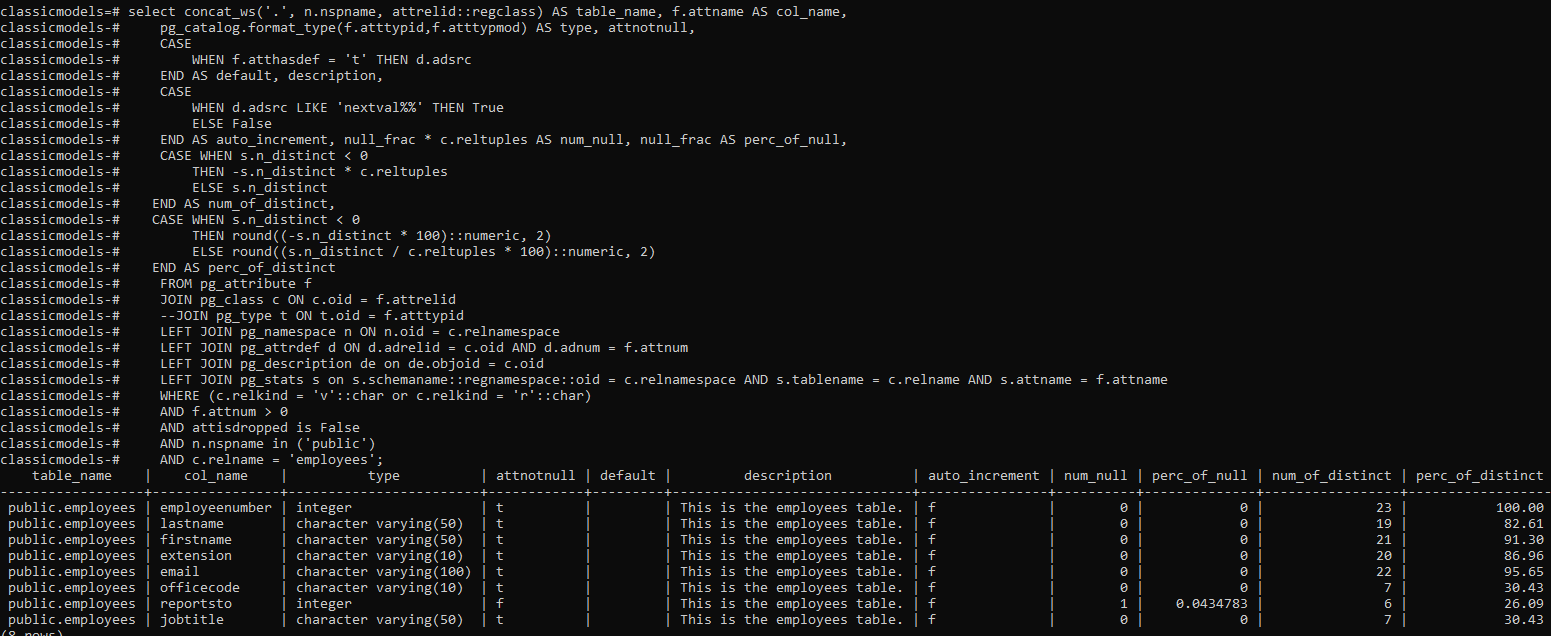 示例表結構和資料:https : //pastebin.com/fXg3RJdi
示例表結構和資料:https : //pastebin.com/fXg3RJdi
非常感謝!
uj5u.com熱心網友回復:
這個想法是使用準備好的陳述句。
- 設定基本查詢:
SET @sql1 := (SELECT GROUP_CONCAT(CONCAT('SELECT "',column_name,'" AS column_name,
COUNT(DISTINCT ',column_name,') AS num_of_distinct,
SUM(CASE WHEN ',column_name,' IS NULL THEN 1 ELSE 0 END) AS num_null,
COUNT(*) AS TotalRows
FROM employees ') SEPARATOR '
UNION ALL
')
FROM information_schema.COLUMNS
WHERE table_name='employees'
AND table_schema= 'public');
/*Check @sql1 variable*/
SELECT @sql1;
- 使用百分比計算設定外部查詢:
SET @sql2 := CONCAT('SELECT *, CAST(num_null/TotalRows AS DECIMAL(14,7)) perc_of_null,
ROUND((num_of_distinct/TotalRows)*100,2) perc_of_distinct
FROM (',@sql1,') tv;');
/*Check @sql2 variable*/
SELECT @sql2;
- 從
@sql2變數準備陳述句,執行然后釋放它:
PREPARE stmt FROM @sql2;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
結果:
| 列名 | num_of_distinct | num_null | 總行數 | perc_of_null | perc_of_distinct |
|---|---|---|---|---|---|
| 員工編號 | 23 | 0 | 23 | 0.0000000 | 100.00 |
| 姓 | 19 | 0 | 23 | 0.0000000 | 82.61 |
| 名 | 21 | 0 | 23 | 0.0000000 | 91.30 |
| 延期 | 20 | 0 | 23 | 0.0000000 | 86.96 |
| 電子郵件 | 22 | 0 | 23 | 0.0000000 | 95.65 |
| 辦公室代碼 | 7 | 0 | 23 | 0.0000000 | 30.43 |
| 匯報給 | 6 | 1 | 23 | 0.0434783 | 26.09 |
| 職稱 | 7 | 0 | 23 | 0.0000000 | 30.43 |
這是一個演示小提琴。
對于根據您的螢屏截圖的完整結果,您可能可以@sql2按如下方式修改變數:
SET @sql2 := CONCAT('SELECT CONCAT(tt.table_schema,".",tt.table_name),
cc.COLUMN_NAME,
cc.COLUMN_TYPE,
cc.IS_NULLABLE,
cc.COLUMN_KEY,
tt.TABLE_COMMENT,
cc.EXTRA,
num_of_distinct,
num_null,
num_null/TotalRows perc_of_null, ROUND((num_of_distinct/TotalRows)*100,2) perc_of_distinct
FROM information_schema.COLUMNS cc
JOIN information_schema.TABLES tt ON cc.TABLE_SCHEMA=tt.TABLE_SCHEMA AND cc.TABLE_NAME=tt.TABLE_NAME
JOIN (',@sql1,') tv ON cc.COLUMN_NAME=tv.column_name
WHERE tt.table_schema="Public" AND tt.table_name="employees";');
但是,我不完全確定 MySQL 上的表屬性是否與 Postgres 中的表屬性匹配。
uj5u.com熱心網友回復:
您可以創建自己的程序,以使用準備好的陳述句構建此類報告。
DELIMITER //
CREATE PROCEDURE sys_column_stats (IN tableName varchar(64))
BEGIN
SET SESSION group_concat_max_len = 1000000;
SELECT
GROUP_CONCAT(
'SELECT \'', c.column_name,'\' AS column_name,',
'(SELECT COUNT(DISTINCT `', c.column_name,'`) FROM `', table_name, '`) AS distinct_count,',
'(SELECT SUM(`', c.column_name,'` IS NULL) FROM `', table_name, '`) AS null_count'
-- ... More stats you need
SEPARATOR ' UNION ALL '
) AS sql_statement
INTO @sql
FROM information_schema.columns c
WHERE `table_name` = tableName;
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END//
DELIMITER ;
用法:
CALL sys_column_stats('employees');
程序中的 SQL 陳述句將UNION ALL查詢準備為
SELECT
'email' AS column_name,
(SELECT COUNT(DISTINCT `email`) FROM `employees`) AS distinct_count,
(SELECT SUM(`email` IS NULL) FROM `employees`) AS null_count
UNION ALL
SELECT
'employeeNumber' AS column_name,
(SELECT COUNT(DISTINCT `employeeNumber`) FROM `employees`) AS distinct_count,
(SELECT SUM(`employeeNumber` IS NULL)FROM `employees`) AS null_count
UNION ALL
[ ... ]
小提琴
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/325115.html
上一篇:根據其他三個列的值創建自定義列