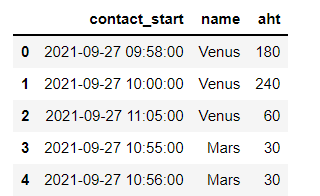
我從下面的 salesforce 匯出并轉換了一個原始資料;
df = pd.DataFrame(columns=['contact_start','name', 'aht'],
data=[['2021-09-27 09:58:00','Venus','180'],
['2021-09-27 10:00:00','Venus','240'],
['2021-09-27 11:05:00','Venus','60'],
['2021-09-27 10:55:00','Mars','30'],
['2021-09-27 10:56:00','Mars','30']])
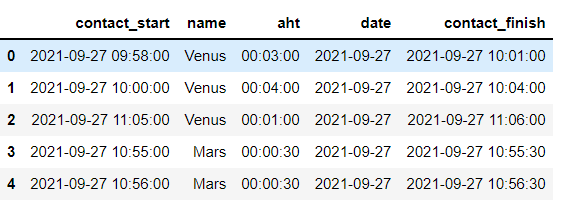
使用下面的這些代碼
df["contact_start"] = pd.to_datetime(df["contact_start"], format = "%Y-%m-%d %H:%M:%S",errors='coerce')
df["date"] = df["contact_start"].dt.strftime('%Y-%m-%d')
df['aht']=pd.to_datetime(df["aht"], unit='s').dt.strftime("%H:%M:%S")
df['contact_finish'] = pd.to_timedelta(df['aht']) pd.to_datetime(df['contact_start'])
df['contact_finish'] = df['contact_finish'].astype('datetime64[s]')
我把它變成:
但我的最終目標是處理重疊問題,我想不出如何實作它。
結果應該如下所示:
df = pd.DataFrame(columns=['date','name', 'total_duration_sec'],
data=[['2021-09-27','Venus','420'],
['2021-09-27','Mars','60']])
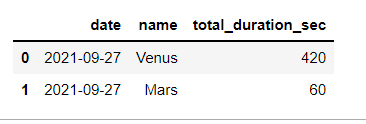
我想這看起來很簡單,但實際上并非如此。我將不勝感激任何幫助。
uj5u.com熱心網友回復:
我認為您可以在每個名稱的連續 contact_start 之間創建以秒為單位的時間差
upper_seconds = (
df.sort_values(['name','contact_start'])
.groupby('name')['contact_start'].diff(-1)
.dt.total_seconds().abs())
print(upper_seconds.sort_index())
# 0 120.0
# 1 3900.0
# 2 NaN
# 3 60.0
# 4 NaN
# Name: contact_start, dtype: float64
現在,您可以將其用作 aht 上的上部剪輯,然后是 groupby 名稱、日期和總和。
res = (
df['aht'].astype(int)
.clip(upper=upper_seconds)
.groupby([df['name'], df['date']]).sum()
.reset_index(name='total_duration_sec')
)
print(res)
name date total_duration_sec
0 Mars 2021-09-27 60
1 Venus 2021-09-27 420
請注意,我使用了您已經撰寫的前兩行來獲得良好的型別。
df["contact_start"] = pd.to_datetime(df["contact_start"],
format = "%Y-%m-%d %H:%M:%S",errors='coerce')
df["date"] = df["contact_start"].dt.strftime('%Y-%m-%d')
uj5u.com熱心網友回復:
您可以通過將這些行添加到您的代碼中來使您現有的代碼作業:
overlapped = pd.Series(df.groupby(['name']).apply(lambda x: (x['contact_finish'] - x['contact_start'].shift(-1)).dt.total_seconds().shift()).droplevel(0), name='overlapped')
overlapped = overlapped.mask(overlapped<0, 0).fillna(0)
df['date'] = df['contact_start'].dt.date
df = df.groupby(['date', 'name']).apply(lambda x: (((x['contact_finish'] - x['contact_start']).dt.seconds) - overlapped).sum()).reset_index(name='total_duration_sec')
輸出:
date name total_duration_sec
0 2021-09-27 Mars 60.0
1 2021-09-27 Venus 420.0
uj5u.com熱心網友回復:
有一個涉及步驟函式的解決方案,可以處理日邊界上的重疊(如果需要更通用的方法)
import pandas as pd
import staircase as sc
def create_union_stepfunction(dframe):
return sc.Stairs(dframe, "contact_start", "contact_finish").make_boolean()
step_functions = df.groupby("name").apply(create_union_stepfunction)
這為您提供了一個名為 的系列step_functions,由行星名稱索引,值是staircase.Stairs代表階躍函式的物件。
name
Mars <staircase.Stairs, id=1956311648200>
Venus <staircase.Stairs, id=1956311120648>
dtype: object
這些階躍函式在接觸期間的值為 1,否則為 0。然后我們可以用 bins 分割階躍函式并計算積分,以獲得每個 bin 進行接觸的總時間。用于日常垃圾桶
def calc_seconds_per_bin(sf, bins):
return sf.slice(bins).integral()/pd.Timedelta("1 second")
step_functions.apply(calc_seconds_per_bin, pd.date_range("2021-9-27", "2021-9-29"))
你會得到一個 pandas.DataFrame
[2021-09-27, 2021-09-28) [2021-09-28, 2021-09-29)
name
Mars 60.0 0.0
Venus 420.0 0.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/325494.html
上一篇:Postgres時間與時區的比較
下一篇:格式化本地化日期時間C#