新手學習爬蟲,作為練習專案,使用Scrapy框架實作騰訊招聘爬蟲并保存到MongoDB資料庫
附騰訊招聘鏈接:搜索 | 騰訊招聘
查看網頁源代碼后發現其中沒有資料,因此轉向后端抓包查找資料源,

找到介面后進行決議,不難發現timestamp后的一串數字就是當前的時間戳,因此爬蟲運行時若要爬取實時的招聘資訊,就要動態獲取當前的時間戳,
 之后開始創建專案
之后開始創建專案
創建專案命令:scrapy startproject tencent
創建爬蟲:scrapy genspider hr tencent.com
item:
import scrapy
from scrapy import Field
class TencentItem(scrapy.Item):
title=Field() #職位
country=Field() #城市
type=Field() #作業型別
text=Field() #崗位介紹
time=Field() #發布時間
url=Field() #職位詳情鏈接
collection='hr'爬蟲體:
import scrapy
import time
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['tencent.com']
start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?timestamp={}'
'&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn'.format(int(time.time()*1000))]
def parse(self, response):
# print(response.json()['Data']['Posts'][0])
content=response.json()['Data']['Posts']
for tr in content:
item={}
item['title']=tr['RecruitPostName']
item['country']=tr['CountryName']+' '+tr['LocationName']
item['type']=tr['CategoryName']
item['text']=tr['Responsibility']
item['time']=tr['LastUpdateTime']
item['url']='https://careers.tencent.com/jobdesc.html?postId='+tr['PostId']
print(item)
yield item
for i in range(2,940):
next_url='https://careers.tencent.com/tencentcareer/api/post/Query?timestamp={}' \
'&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'.format(int(time.time()*1000),i)
yield scrapy.Request(
url=next_url,
callback=self.parse
)這里先獲取資料,之后創建一個空字典item,對每個欄位進行拆分,生成鍵值對進行保存,之后查找下一頁的url地址,在翻頁后觀察url中改變的引數資訊,除了時間戳之外還發現其中的pageIndex由1變成了2,由此可以判斷根據這個引數進行翻頁,之后使用一個for回圈生成url地址(這里爬取940頁的招聘資訊)
最后生成請求,將生成的url地址交給回呼函式parse進行爬取,直到結束
資料清洗和資料庫保存:
from pymongo import MongoClient
class MongoPipeline(object):
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri=mongo_uri
self.mongo_db=mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client=MongoClient(self.mongo_uri)
self.db=self.client[self.mongo_db]
def process_item(self,item,spider):
name=item.__class__.__name__
item['text']=item['text'].strip() #洗掉字串末端空格
self.db[name].insert(dict(item)) #插入資料庫
return item
def close_spider(self,spider):
self.client.close()最后對爬取的資訊進行清洗并保存到資料庫
settings資訊:
BOT_NAME = 'tencent'
SPIDER_MODULES = ['tencent.spiders']
NEWSPIDER_MODULE = 'tencent.spiders'
MONGO_URL='localhost'
MONGO_DB='tencent'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
ROBOTSTXT_OBEY = False
LOG_LEVEL='WARNING'
ITEM_PIPELINES = {
'tencent.pipelines.MongoPipeline': 300,
}運行結果:
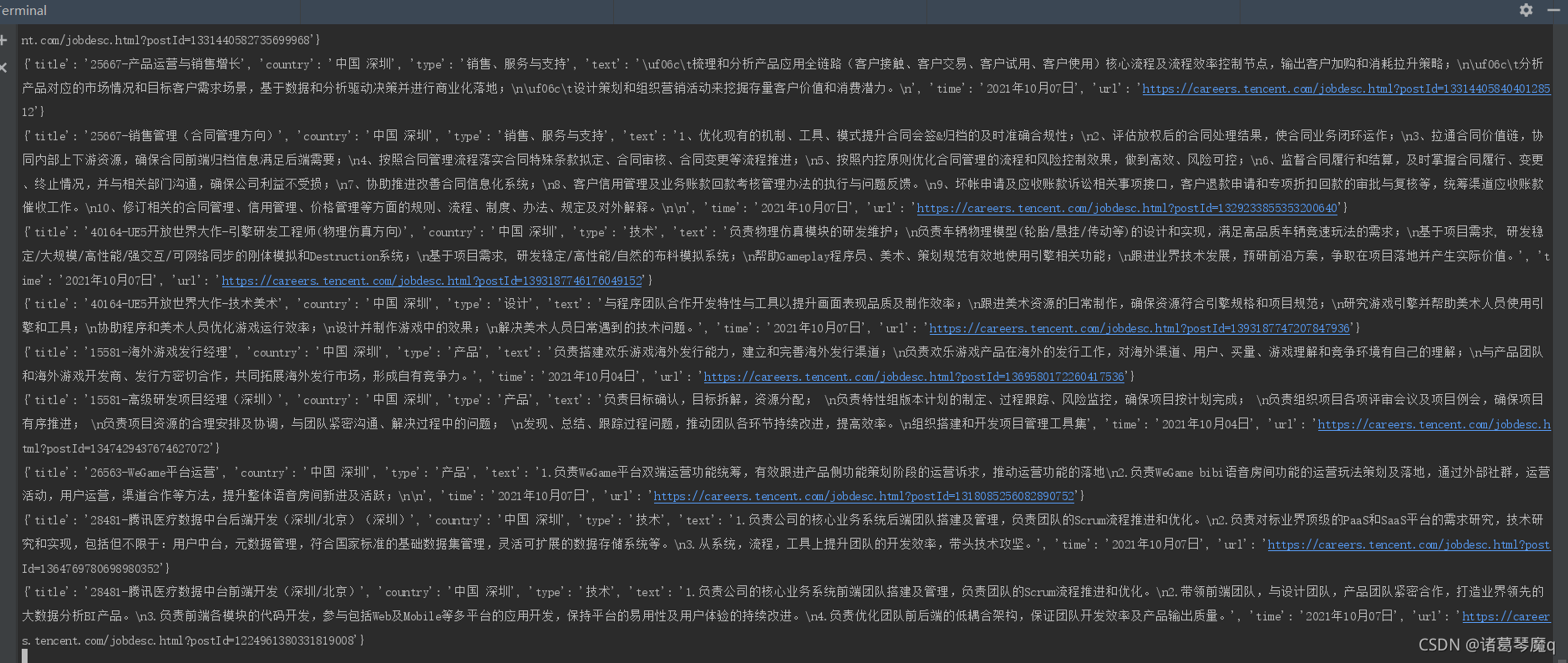
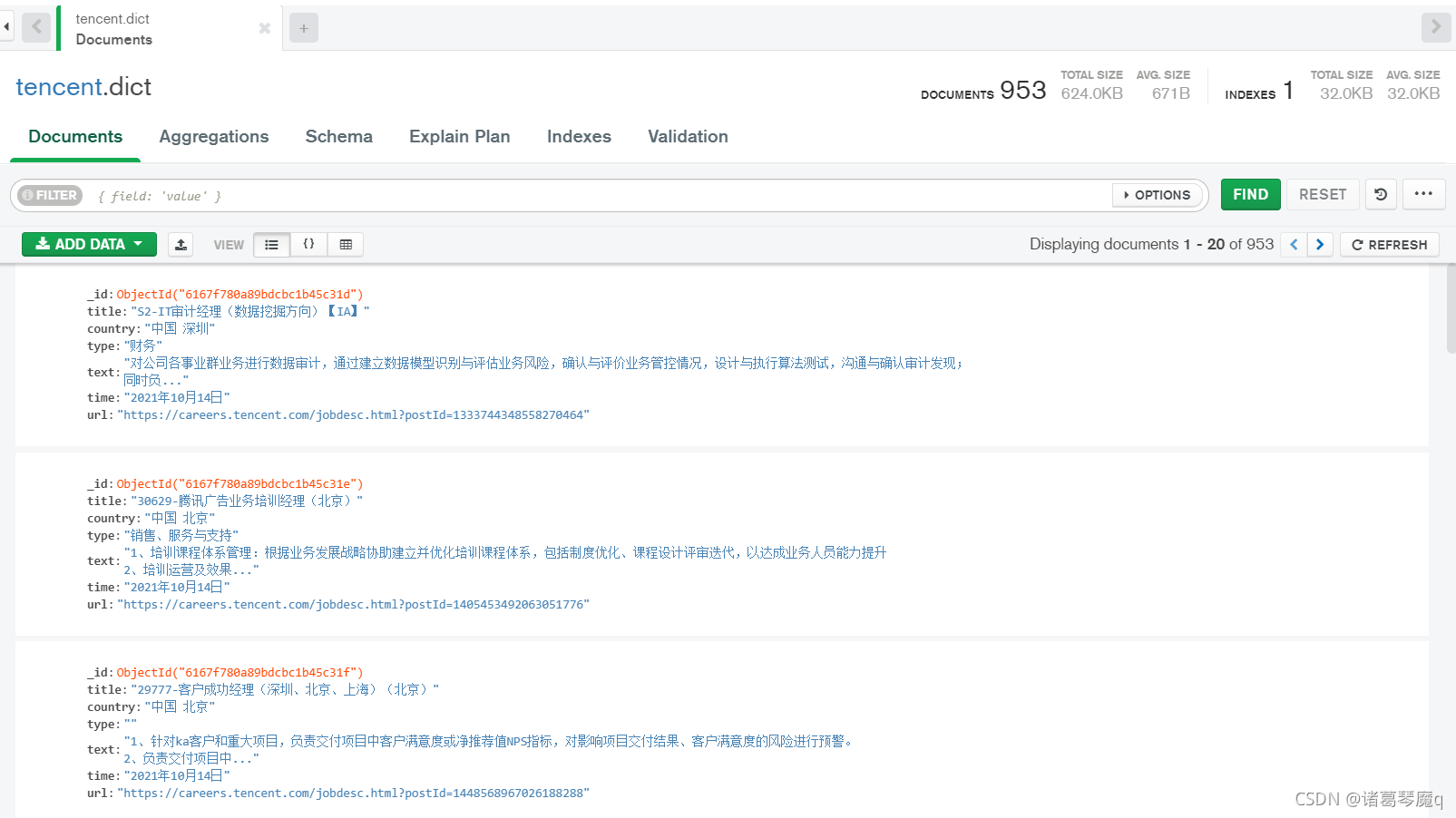
作為爬蟲初學者第一次嘗試練習,還有很多不足,歡迎指點,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/329274.html
標籤:區塊鏈