我有一個小專案,對我來說有點頭疼,因為我不是 Python 的新手,我在周末用 Python 進行了幾年的編程。但我看到有很多方法可以轉換 csv 檔案中的資料。我不確定該選擇哪一個,甚至不知道從哪里開始,但我自己可以做很多研究。
現在我有這個資料集:
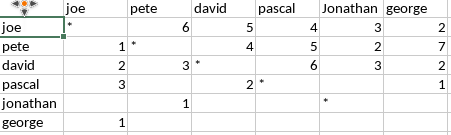
這就是我所擁有的:
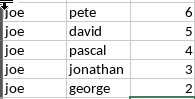
這就是我要的:
可能你們知道哪個模塊最適合給定的問題,目前我關注的是 Pandas 和 openpyxl。
提前謝謝!
uj5u.com熱心網友回復:
它不必很復雜。鑒于此程式:
headings = []
for line in open('x.csv'):
parts = line.rstrip().split(',')
if not headings:
headings = parts
continue
for name,item in zip(headings, parts):
if item.isdigit():
print(','.join((parts[0], name, item)) )
這個輸入:
x,joe,pete,david,pascal,jonathan,george
joe,*,6,5,4,3,2
pete,1,*,4,5,2,7
david,2,3,*,6,3,2
pascal,3,,2,*,,1
jonathan,,1,,,*,,
george,1,,,,,
產生這個輸出:
joe,pete,6
joe,david,5
joe,pascal,4
joe,jonathan,3
joe,george,2
pete,joe,1
pete,david,4
pete,pascal,5
pete,jonathan,2
pete,george,7
david,joe,2
david,pete,3
david,pascal,6
david,jonathan,3
david,george,2
pascal,joe,3
pascal,david,2
pascal,george,1
jonathan,pete,1
george,joe,1
uj5u.com熱心網友回復:
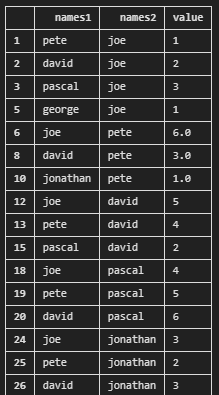
根據您之后可能想做的事情,pandas 選項可能會很有用。在這種情況下,您可以簡單地使用melt. 在這里,我重命名了第一列,names1但如果它有另一個名稱,請使用它。
import pandas as pd
path = 'D:/'
file = 'data.csv'
data = pd.read_csv(path file, delimiter=',')
data = data.rename(columns={'Unnamed: 0':'names1'})
df = pd.melt(data, id_vars=['names1'], var_name='names2')
df = df.dropna(subset=['value'])
df = df[df['value'] != '*']
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/329863.html
上一篇:Terraform匯入地圖資源
下一篇:Xamarin中的Auth0登錄