澄清一下。我想計算每個人在每個年齡段之前發生的事件數量,按性別分組并計算平均值。因此,舉例來說,資料集中有四名女性。在20歲時,所有女性總共有4個事件,在21歲時,總共有6個事件。由于資料集中有4名女性,20歲時的累積平均數(如果這是一個詞的話)是1,21歲時的平均數是1.5等等。這就是我想在折線圖中可視化的內容。
我有這樣的資料:
我有這樣的資料。
set.seed(123)
id <- rep(1: 8,每個= 5)
女性 < - (c(rep(1。 20)。 rep(0。 20)))
age < - c(rep(20。 24, 8))
dat <- data.frame(id, female, age)
dat$event < - sample(rep(c(1。 0)。 nrow(dat) / 2))
其中id列代表一個獨特的個體,如果女性等于1,則為女性。事件如果發生則等于1,如果沒有發生則等于0。
我想創建一個折線圖,按性別列出每個年齡組發生的事件的累積平均值。也就是說,我想把男性在20,...,24歲時經歷的事件的累計平均數和女性在20,...,24歲時經歷的事件的累計平均數形象化。
我希望它是有意義的,并且是可以實作的。
uj5u.com熱心網友回復:
我想這就是你想要的--通過dplyr計算各組的平均值。
library(dplyr)
library(ggplot2)
set.seed(123)
id <- rep(1。 8,每個= 5)
女性 < - (c(rep(1。 20)。 rep(0。 20)))
age < - c(rep(20。 24, 8))
dat <- data.frame(id, female, age)
dat$event < - sample(rep(c(1。 0)。 nrow(dat) / 2))
dat <- dat %> % group_by(female,age) %>%
summarise_at(vars(event),
list(mean = mean)
ggplot(dat, aes(x=age。 y=mean。 group=female))
geom_line(aes(linetype=as. character(female))
geom_point()
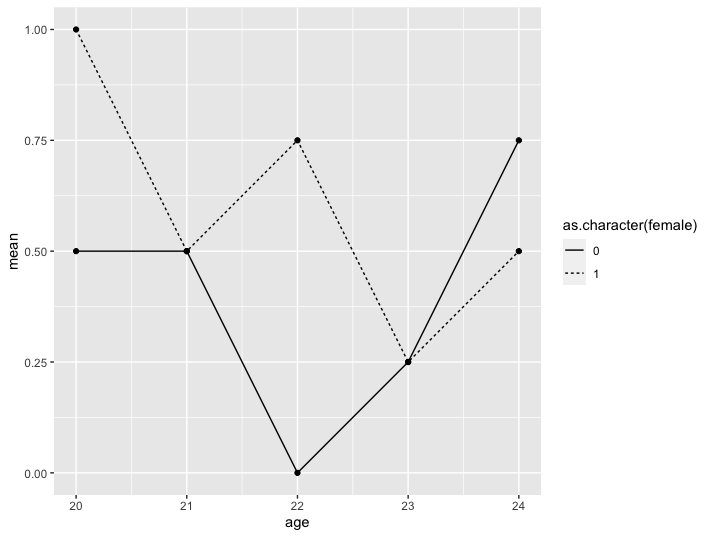
uj5u.com熱心網友回復:
我希望我得到了你的正確答案
library(dplyr)
library(ggplot2)
set.seed(123)
id <- rep(1。 8,每個= 5)
女性 < - (c(rep(1。 20)。 rep(0。 20)))
age < - c(rep(20。 24, 8))
dat <- data.frame(id, female, age)
dat$event < - sample(rep(c(1。 0)。 nrow(dat) / 2))
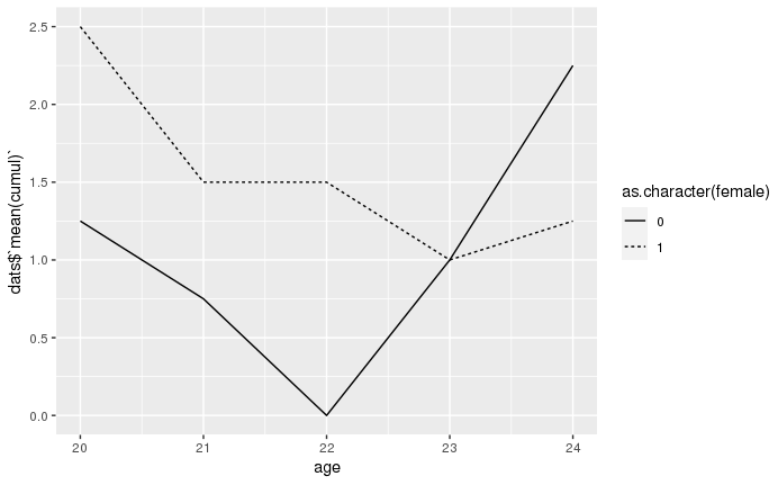
dats <- dat %>%
arrange(age)%>%
group_by(年齡,女)%>%
突變(cumul = cumsum(event))%> %
summarise(mean(cumul))
ggplot(dats, aes(x = age。 y =dats$`mean(cumul)`。 組=女))
geom_line(aes(linetype=as。 character(female)))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/330198.html
標籤: