我想對 X、Y 資料執行計算以生成計算出的 Z。我的代碼如下:
injection_wells.csv 的示例資料集
| 姓名 | X | 是 | 問 |
|---|---|---|---|
| MW-1 | 2517700 | 996400 | 5 |
| MW-2 | 2517770 | 996420 | 5 |
import pandas as pd
import math
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.tri as tri
IW = pd.read_csv (r'Injection_wells.csv')
`Note that - Injection wells is a table of three wells with names, X, Y, and Q (flow rate).`
#pull all the relevant well information by well into their own arrays
MW1 = IW[IW['Name'] == 'MW1']
MW2 = IW[IW['Name'] == 'MW2']
MW3 = IW[IW['Name'] == 'MW3']
#initiate grid
xi = np.linspace(2517675,2517800,625)
yi = np.linspace(996300,996375,375)
#make it so i can apply np.float to an array
vector = np.vectorize(np.float)
X,Y = np.meshgrid(xi,yi)
#perform calculation over every X and Y.
PSI = ((MW1['Q']/(2*math.pi))*(np.arctan(((vector(X[None,:]))-np.float(MW1['X']))/(vector(Y[:,None])-np.float(MW1['Y']))))
(MW2['Q']/(2*math.pi))*(np.arctan(((vector(X[None,:])-np.float(MW2['X']))/vector((Y[:,None])-np.float(MW2['Y'])))))
(MW3['Q']/(2*math.pi))*(np.arctan(((vector((X[None,:])-np.float(MW3['X']))/vector((Y[:,None])-np.float(MW3['Y'])))))))
我收到錯誤:
ValueError Traceback (most recent call last)
<ipython-input-11-fd6ee058014f> in <module>
17 X,Y = np.meshgrid(xi,yi)
18
---> 19 PSI = ((MW1['Q']/(2*math.pi))*(np.arctan(((vector(X[None,:]))-np.float(MW1['X']))/(vector(Y[:,None])-np.float(MW1['Y']))))
20 (MW2['Q']/(2*math.pi))*(np.arctan(((vector(X[None,:])-np.float(MW2['X']))/vector((Y[:,None])-np.float(MW2['Y'])))))
21 (MW3['Q']/(2*math.pi))*(np.arctan(((vector((X[None,:])-np.float(MW3['X']))/vector((Y[:,None])-np.float(MW3['Y'])))))))
~\Anaconda3\lib\site-packages\pandas\core\ops\common.py in new_method(self, other)
63 other = item_from_zerodim(other)
64
---> 65 return method(self, other)
66
67 return new_method
~\Anaconda3\lib\site-packages\pandas\core\ops\__init__.py in wrapper(left, right)
343 result = arithmetic_op(lvalues, rvalues, op)
344
--> 345 return left._construct_result(result, name=res_name)
346
347 wrapper.__name__ = op_name
~\Anaconda3\lib\site-packages\pandas\core\series.py in _construct_result(self, result, name)
2755 # We do not pass dtype to ensure that the Series constructor
2756 # does inference in the case where `result` has object-dtype.
-> 2757 out = self._constructor(result, index=self.index)
2758 out = out.__finalize__(self)
2759
~\Anaconda3\lib\site-packages\pandas\core\series.py in __init__(self, data, index, dtype, name, copy, fastpath)
311 try:
312 if len(index) != len(data):
--> 313 raise ValueError(
314 f"Length of passed values is {len(data)}, "
315 f"index implies {len(index)}."
ValueError: Length of passed values is 375, index implies 1.
我知道這與我試圖將函式應用于僅接受一個值的陣列有關。我正在嘗試克服這個問題,并能夠在整個網格資料集上按原樣執行此計算。對此的任何幫助將不勝感激。
我正在嘗試做的方程式如下。請注意,方程中的 theta 是從網格節點到注入井(對于每個網格節點)的距離的反正切,這是我試圖在代碼中復制的內容。
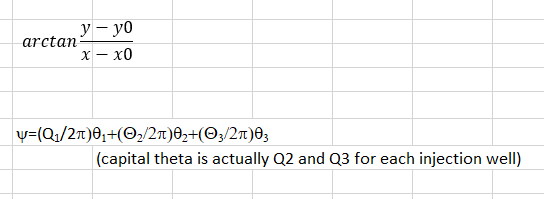
謝謝
uj5u.com熱心網友回復:
我會在這里跳槍,因為我想我現在明白了這個問題,在多看了一點之后。
所以你有一個注入井資料的 DataFrame,有四列:
name x y q
str int int int
您有一個f(x, y, q) -> z要評估的函式。我不確定我是否完全遵循您的函式正在執行的操作,因為它的格式非常難以閱讀,因此我將使用一個簡化的示例:
def func(x, y, q):
return (q / 2 * np.pi) * np.arctan(y, x)
現在,不要將井資料分成不同的陣列,只需按行在整個資料幀上應用該函式:
df["z"] = func(df.x, df.y, df.q)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/330958.html