我有兩個資料框架:
我有兩個資料框架。
df1 = pd.DataFrame.from_dict({('category', '): {0: 'A'。
1: 'B'。
2: 'C'。
3: 'D'。
4: 'E'。
5: 'F'。
6: 'G'}。
(pd.Timestamp('2021-06-28 00:00:00'),
'metric_1')。) {0: 4120.54999999, 1: 11226.0166666665, 2: 25049.4433333333, 3: 18261.0833333332, 4: 2553.12083333334, 5: 2843.01, 6: 73203.51333333334},
(pd.Timestamp('2021-06-28 00:00:00'/span>), 'metric_2')。{0: 9907.79,
1: 7614.650000000001,
2: 13775.259999999998,
3: 13158.250000000004,
4: 1457.85,
5: 1089.5600000000002,
6: 38864.9}。
(pd.Timestamp('2021-07-05 00:00:00'),
'metric_1')。) {0: 5817.3199999998, 1: 10799.45, 2: 23521.51, 3: 22062.3508333334, 4: 1249.59749999999, 5: 3229.77, 6: 52796.06083333332},
(pd.Timestamp('2021-07-05 00:00:00'/span>), 'metric_2'): {0: 6321.21,
1: 5606.01,
2: 10239.689999999999,
3: 17476.600000000002,
4: 943.7199999999999,
5: 1410.33,
6: 29645.45}}.set_index('category')
df2 = pd.DataFrame.from_dict({'category'/span>: {0: 'A',
1: 'B'。
2: 'C'。
3: 'D'。
4: 'E'。
5: 'F'。
6: 'G'}。
1: {0: 36234.035577957984,
1: 69078.07089184562,
2: 128879.5397517309,
3: 178376.63536908248,
4: 9293.956915067887,
5: 8184.780211399392,
6: 177480.74540313095},
2: {0: 37887.581678419825,
1: 72243.67956241772,
2: 134803.02342121338,
3: 186603.8963173654,
4: 9716.385738295368,
5: 8555.606693927,
6: 185658.87577993725}}.set_index('category')
首先我把df2的列名改為與df
date_mappings = {
1 : '2021-06-28'/span>,
2 : '2021-07-05'}。
df2 = df2.rename(columns=date_mappings)
然后我嘗試合并它
f = lambda x: pd.to_datetime(x)
df = (df2.merge(df1.unstack(), left_index=True, right_index=True).sort_index( axis=1)
但是我得到了一個錯誤:
ValueError。無法合并一個沒有名字的系列
我的錯誤是什么呢?
我的目標是在每周的df2到df1中添加列,這樣df1就會有3列而不是2列。
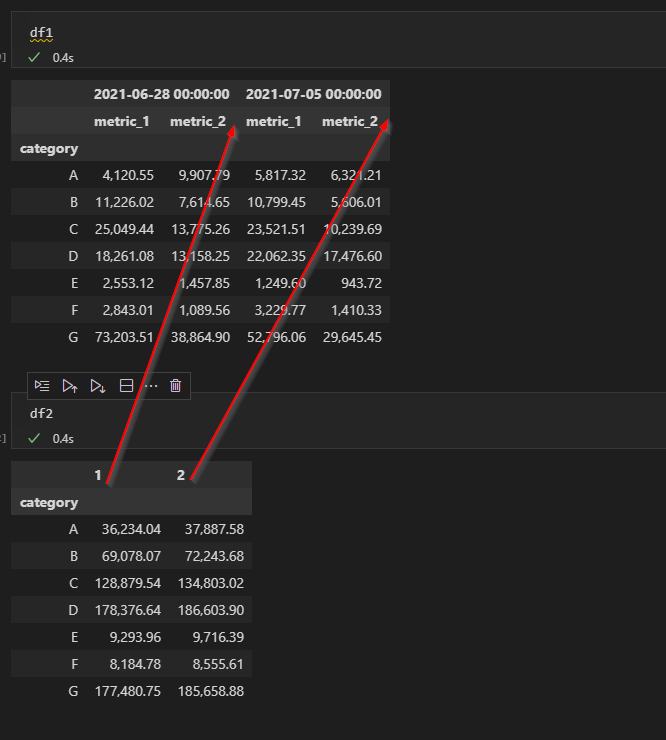
在使用
之后c = [df2.columns.map(date_mappings.get), df2.columns]
df1.join(df2.set_axis(c, axis=1)).sort_index( axis=1)
我得到的值被附加到資料框架的末尾,而不是被附加到具有相同周數命名的相同列:
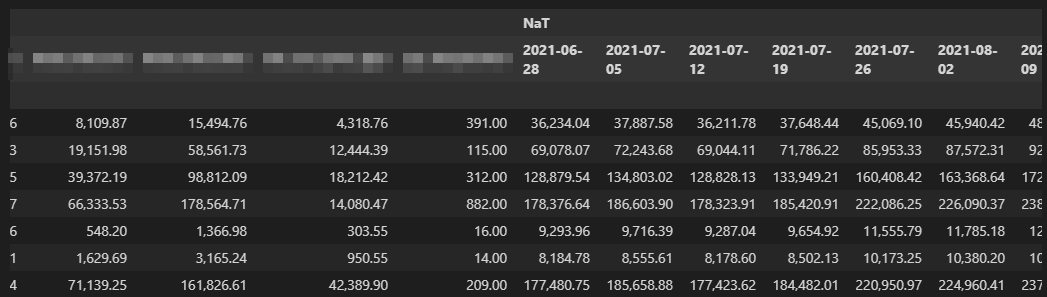
也許這可能是一個問題。
也許這可能是一個問題,df2持有從2021-06-28到2022-06-27的日期,而df1持有從2020到今天的日期。
不需要在df的末尾添加。
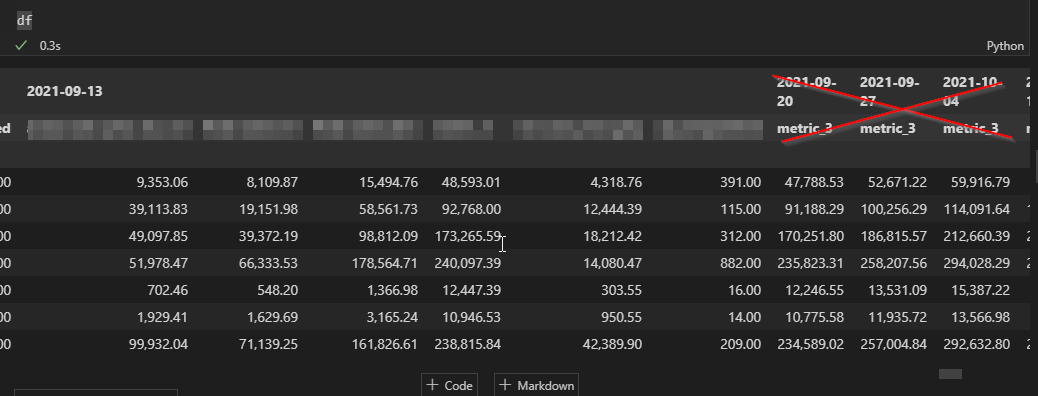
uj5u.com熱心網友回復:
想法是在兩個DataFrame中創建MultiIndex:
date_mappings = {
1 : '2021-06-28'/span>,
2 : '2021-07-05'}。
#create MultiIndex in df2 with datetimes in first level
df2.columns = pd.MultiIndex.from_product([pd.to_datetime(df2.columns.map(date_mappings) )。
['metric_3']])
#removed unused levels, here category, so possible convert first leve to datetimes.
df1.columns = df1.columns.remove_unused_levels()
df1.columns = df1.columns.set_levels(pd.to_datetime(df1.columns.level[0], level=0)
#join together and sorting MultiIndex
df = df1.join(df2).sort_index(axis=1)
print (df)
2021-06-28 202107-05
公制_1 公制_2 公制_3 公制_1 公制_2
類別
A 4120.550000 9907.79 36234.035578 5817.320000 6321.21
B 11226.016667 7614.65 69078.070892 10799.450000 5606.01[/span
C 25049.443333 13775.26 128879.539752[/span> 23521.510000 10239.69[/span
D 18261.083333 13158.25 178376.635369 22062.350833 17476.602553.120833 1457.85 9293.956915 1249.597500 943.72
F 2843.010000 1089.56 8184.780211 3229.770000 1410.33
G 73203.513333 38864.90 177480.745403 52796.060833 29645.45[/span
公制_3
類別
A37887.581678
B類72243.679562
C134803.023421
D 186603.896317[/span
E 9716.385738[/span
F 8555.606694[/span
G185658.875780
如果需要洗掉更大的資料時間,如最大的df1資料時間,請使用:
#change mapping for test
date_mappings = {
1 : '2021-06-28'/span>,
2 : '2022-07-05'}.
df2.columns = pd.MultiIndex.from_product([pd.to_datetime(df2.columns.map(date_mappings))。
['metric_3']])
df1.columns = df1.columns.remove_unused_levels()
df1.columns = df1.columns.set_levels(pd.to_datetime(df1.columns.level[0]), level=0)
df2 = df2.loc[:, df2.columns.get_level_values(0) <= df1.columns.get_level_values(0).max() ]
print (df2)
2021-06-28
公制_3
類別
A 36234.035578[/span
B 69078.070892[/span
C 128879.539752[/span
D 178376.635369[/span
E 9293.956915[/span
F 8184.780211[/span
G177480.745403
#join together and sorting MultiIndex
df = df1.join(df2).sort_index(axis=1)
print (df)
2021-06-28 202107-05
公制_1 公制_2 公制_3 公制_1 公制_2
類別
A 4120.550000 9907.79 36234.035578 5817.320000 6321.21
B 11226.016667 7614.65 69078.070892 10799.450000 5606.01[/span
C 25049.443333 13775.26 128879.539752[/span> 23521.510000 10239.69[/span
D 18261.083333 13158.25 178376.635369 22062.350833 17476.602553.120833 1457.85 9293.956915 1249.597500 943.72
F 2843.010000 1089.56 8184.780211 3229.770000 1410.33
G 73203.513333 38864.90 177480.745403 52796.060833 29645.45
uj5u.com熱心網友回復:
使用pd.DataFrame.reindex pd.DataFrame.join。
reindex有一個方便的級別引數,允許你對不存在的索引級別進行擴展。
df1.join(df2.reindex(df1.index, level=0)
uj5u.com熱心網友回復:
我不確定這是否是你想要的,但你可能需要to_frame:
f = lambda x: pd.to_datetime(x)
df = (df2.merge(df1.unstack().to_frame(), left_index=True, right_index=True).sort_index(level=0)
print(df)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/332437.html
標籤: