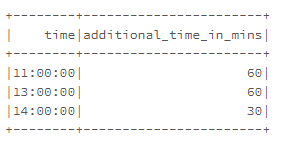
我有以下的pyspark資料框架,都是字串列。
time additional_time_in_mins
11: 00: 00 60
13:00: 00 60
14:00: 00 30
我必須將附加時間欄中的分鐘數添加到實際時間中,并在pyspark中創建一個如下的輸出。
預期輸出:
new_time
12: 00: 00
14:00:00
14:30: 00
在pyspark中是否有辦法做到這一點
uj5u.com熱心網友回復:
一個簡單的選擇是使用unix_timestamp函式將time列轉換為bigint,以秒為單位,加上分鐘(minutes * 60s),然后將結果投回到timestamp。
最后,轉換為每小時的格式。
df = df.withColumn('new_time', F. date_format((F.unix_timestamp('time'/span>, 'HH:mm:ss') F.col('additional_time_in_mins')*60).cast('timestamp'), 'HH:mm:ss')
df.show()
-------- ----------------------- --------
|時間|additional_time_in_mins|new_time|
-------- ----------------------- --------
|11:00。 00| 60|12:00:00|
|13:00。 00| 60|14:00:00|
|14:00。 00| 30|14:30:00|
-------- ----------------------- --------
uj5u.com熱心網友回復:
使用UDF的其他方法:
from pyspark.sql.function import date_format, col
data = [...
("11:00:00"/span>, "60"/span>)。
("13:00:00", "60") 。
("14:00:00", "30")。
]
df = spark.createDataFrame(data, ["time", "additional_time_in_mins"] )
df.show()
UDF邏輯求和。
UDF邏輯來總結時間
from pyspark.sql.types import StringType, IntegerType
from pyspark.sql.function import udf
)。
def sum_time(var_time, additional_time) 。
# 將var_time字串轉換為時間。
var_time = datetime.strptime(var_time, '%H:%M:%S').time()
#Using date to utitlise the time function[/span]。
combined_time = (datetime.combined(date.today(), var_time) timedelta(minutes=additional_time)).time()
return str(combined_time)
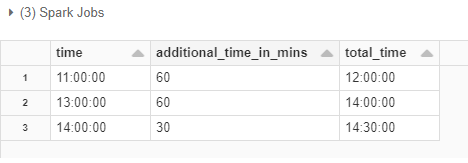
使用UDF來獲得最終的輸出:
df = df.withColumn(
"total_time", sum_time(col("time"), col("additional_time_in_mins").cast(IntegerType())
)
顯示(df)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/332768.html
標籤:
上一篇:Python類變數用于呼叫方法