我有一個藥物 ID (NDC_NBR) 及其相應藥物名稱 (BRAND_NM) 的資料框。
我需要將每種藥物的藥物名稱折疊/聚合到盡可能低的特異性。
這是我正在使用的資料和預期結果的示例:
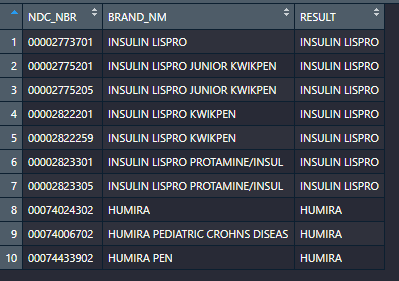
data <- data.frame(NDC_NBR = c("00002773701","00002775201","00002775205","00002822201","00002822259","00002823301","00002823305","00074024302","00074006702","00074433902"),BRAND_NM = c("INSULIN LISPRO","INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO KWIKPEN","INSULIN LISPRO KWIKPEN","INSULIN LISPRO PROTAMINE/INSUL","INSULIN LISPRO PROTAMINE/INSUL","HUMIRA","HUMIRA PEDIATRIC CROHNS DISEAS","HUMIRA PEN"), RESULT = c("INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","HUMIRA","HUMIRA","HUMIRA"))
我希望將這些產品折疊為最不具體的藥物名稱,即使用字符“INSULIN LISPRO”和“HUMIRA”變異一個新列。
“INSULIN LISPRO”對前 7 行通用,而“INSULIN LISPRO KWIKPEN”僅對 7 行中的 2 行通用。同樣,HUMIRA 與任何“INSULIN”行都沒有相似性,但對最后 3 行都是通用的。
我有大量此類產品的資料框,不可能手動轉換每一個。
如果有人能提出解決此類問題的方法,我將不勝感激。
uj5u.com熱心網友回復:
兩種解決方案,分別針對不同的場景:
- 場景#1 - 你有一個理想的品牌名稱串列:
這是針對此場景的兩步解決方案:
首先,將短品牌名稱定義為交替模式p:
p <- paste0(BRAND_NM_short, collapse = "|")
然后使用此模式gsub來匹配BRAND_NM您要保留的部分,并BRAND_NM僅替換為匹配的短品牌名稱:
library(dplyr)
data %>%
mutate(result = gsub(paste0("(", p, ").*"), "\\1", BRAND_NM))
NDC_NBR BRAND_NM result
1 00002773701 INSULIN LISPRO INSULIN LISPRO
2 00002775201 INSULIN LISPRO JUNIOR KWIKPEN INSULIN LISPRO
3 00002775205 INSULIN LISPRO JUNIOR KWIKPEN INSULIN LISPRO
4 00002822201 INSULIN LISPRO KWIKPEN INSULIN LISPRO
5 00002822259 INSULIN LISPRO KWIKPEN INSULIN LISPRO
6 00002823301 INSULIN LISPRO PROTAMINE/INSUL INSULIN LISPRO
7 00002823305 INSULIN LISPRO PROTAMINE/INSUL INSULIN LISPRO
8 00074024302 HUMIRA HUMIRA
9 00074006702 HUMIRA PEDIATRIC CROHNS DISEAS HUMIRA
10 00074433902 HUMIRA PEN HUMIRA
- 場景#2:您沒有理想的品牌名稱串列。
對于這個問題,這里有一個更復雜的解決方案:
步驟 1:運行for回圈以根據動態模式檢測從一行到下一行的任何重復單詞:
# initialize vectors/columns:
p1 <- c()
data$repeats <- NA
# for loop to detect repeated words across rows:
library(stringr)
for(i in 2:nrow(data)){
p1[i-1] <- paste0(unlist(str_split(trimws(data$BRAND_NM[i-1]), "\\s ")), collapse = "|")
data$repeats[i] <- str_extract_all(data$BRAND_NM[i], p1[i-1])
}
第二步:mutate重復詞得到理想的品牌名稱,假設它們最多包含兩個詞:
data %>%
mutate(result = sapply(repeats, function(x) paste(x[1], x[2], collapse = " ")),
result = sub("\\sNA", "", result),
result = ifelse(grepl("NA", result), lead(result), result)) %>%
select(-repeats)
資料:
BRAND_NM_short = c("INSULIN LISPRO", "HUMIRA")
data <- data.frame(NDC_NBR = c("00002773701","00002775201","00002775205","00002822201","00002822259","00002823301","00002823305","00074024302","00074006702","00074433902"),
BRAND_NM = c("INSULIN LISPRO","INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO KWIKPEN","INSULIN LISPRO KWIKPEN","INSULIN LISPRO PROTAMINE/INSUL","INSULIN LISPRO PROTAMINE/INSUL","HUMIRA","HUMIRA PEDIATRIC CROHNS DISEAS","HUMIRA PEN"))
uj5u.com熱心網友回復:
這是一種方法,假設第一個單詞始終是名稱的一部分:
mydata <- data.frame(NDC_NBR = c("00002773701","00002775201","00002775205","00002822201",
"00002822259","00002823301","00002823305","00074024302",
"00074006702","00074433902"),
BRAND_NM = c("INSULIN LISPRO","INSULIN LISPRO JUNIOR KWIKPEN",
"INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO KWIKPEN",
"INSULIN LISPRO KWIKPEN","INSULIN LISPRO PROTAMINE/INSUL",
"INSULIN LISPRO PROTAMINE/INSUL","HUMIRA",
"HUMIRA PEDIATRIC CROHNS DISEAS","HUMIRA PEN"))
# add the first word as a main grouping column
mydata["main_group"] <- mydata %>% apply(1, function(x) strsplit(x["BRAND_NM"], " ")[[1]][1])
mydata["RESULT"] <- mydata %>%
# per group: get the number of words in common between all rows in group
group_by(main_group) %>%
mutate(intersect_cnt = Reduce(intersect, strsplit(BRAND_NM," ")) %>% length()) %>%
# extract the identified words
apply(1, function(x) paste(strsplit(x["BRAND_NM"], " ")[[1]][1:x["intersect_cnt"]], collapse = " "))
輸出:
mydata
# NDC_NBR BRAND_NM main_group RESULT
# 1 00002773701 INSULIN LISPRO INSULIN INSULIN LISPRO
# 2 00002775201 INSULIN LISPRO JUNIOR KWIKPEN INSULIN INSULIN LISPRO
# 3 00002775205 INSULIN LISPRO JUNIOR KWIKPEN INSULIN INSULIN LISPRO
# 4 00002822201 INSULIN LISPRO KWIKPEN INSULIN INSULIN LISPRO
# 5 00002822259 INSULIN LISPRO KWIKPEN INSULIN INSULIN LISPRO
# 6 00002823301 INSULIN LISPRO PROTAMINE/INSUL INSULIN INSULIN LISPRO
# 7 00002823305 INSULIN LISPRO PROTAMINE/INSUL INSULIN INSULIN LISPRO
# 8 00074024302 HUMIRA HUMIRA HUMIRA
# 9 00074006702 HUMIRA PEDIATRIC CROHNS DISEAS HUMIRA HUMIRA
# 10 00074433902 HUMIRA PEN HUMIRA HUMIRA
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/333195.html