2021SC@SDUSC
目錄
- 一、MerkleProof
- 二、MerkleSortTree
一、MerkleProof
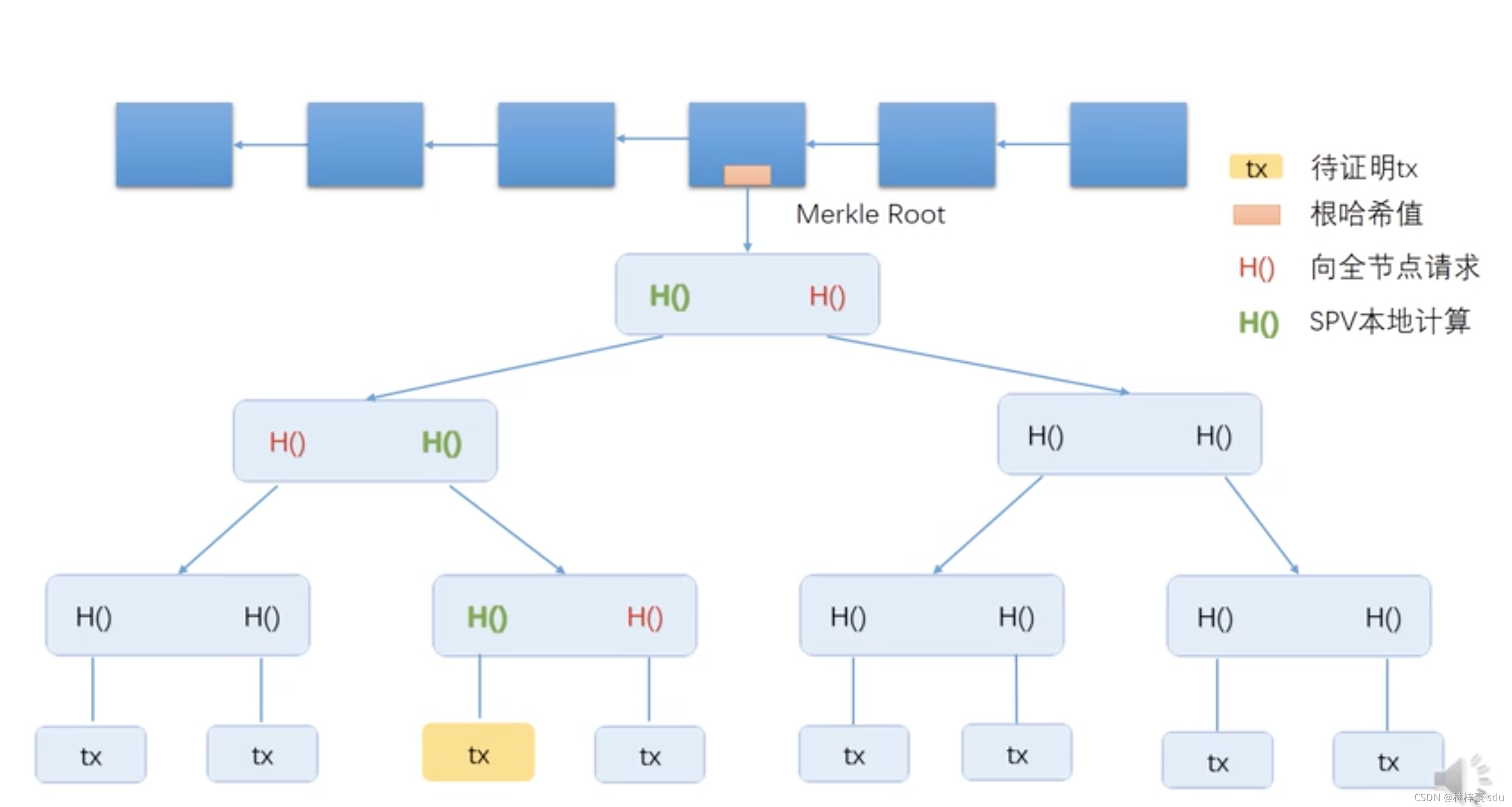
假如一個輕節點想知道一個事物資訊是否被保存到了區塊中,它可以向途中的全節點發出請求,這個輕節點會被給到下圖中三個紅色的哈希指標,這樣他就可以在本地算出綠色的哈希指標,即由這個事務算出的哈希值,順著葉節點就可以找到MerkleTree的根節點,而這個header就被保存在區塊鏈的某個節點當中,
那么接下來我們就看看jdchain中MerkleProof的內容,如下方代碼:
package com.jd.blockchain.ledger;
public interface MerkleProof {
com.jd.blockchain.crypto.HashDigest getRootHash();
com.jd.blockchain.ledger.MerkleProofLevel[] getProofLevels();
com.jd.blockchain.crypto.HashDigest getDataHash();
}
我們可以看到MerkleProof中包含著三個介面,一個是HashDigest getRootHash()另一個是getDataHash();顧名思義,我們可以知道這個事一個獲取根節點獲取哈希的資料的方法;究其根本,我們可以看到這么兩個介面,第一個關于位元組序列的介面,這個介面定義了MerkleTree的尾部事物序列,具有不存在證明的職能,第二個介面可以使事務連續,這樣可以防止他人篡改,
public interface ByteSequence {
int size();
byte byteAt(int index);
default boolean equal(byte[] data) { /* compiled code */ }
utils.ByteSequence subSequence(int start, int end);
int copyTo(int srcOffset, byte[] dest, int destOffset, int length);
default int copyTo(byte[] dest, int destOffset, int length) { /* compiled code */ }
}
public interface BytesSerializable {
byte[] toBytes();
}
我們還可以看到一個getProofLevels();,這個是樹的level是按照倒置的方式計算,而不是以根節點的距離衡量,即葉子節點的 level 是 0; 所有的資料的哈希索引都以葉子節點進行記錄每一個資料節點都以標記一個序列號(Sequence Number, 縮寫為 SN),并按照序列號的大小統一地在 level 0;
下面的代碼我們可以看出,它同樣呼叫了HashDigest的方法,獲取了節點的node,用來辨別Merkle樹的層級,
public interface MerkleProofLevel {
int getProofPoint();
com.jd.blockchain.crypto.HashDigest[] getHashNodes();
}
二、MerkleSortTree
首先這個類implements了Transactional的介面,這個介面的職能就基本是更新,提交,洗掉的事物,
public interface Transactional {
boolean isUpdated();
void commit();
void cancel();
}
默克爾排序樹;所有的資料的哈希索引都以葉子節點進行記錄;隨著資料節點的增加,整棵樹以倒置方式向上增長(根節點在上,葉子節點在下),此設計帶來顯著特性是已有節點的資訊都可以不必修改;但由于對單個賬本中的寫入程序被設計為同步寫入,因而非執行緒安全的設計并不會影響在此場景下的使用,而且由于省去了執行緒間同步操作,反而提升了性能;
構建了一個空的樹
public MerkleSortTree(TreeOptions options, String keyPrefix, ExPolicyKVStorage kvStorage,BytesConverter<T> converter) {
this(TreeDegree.D3, options, Bytes.fromString(keyPrefix), kvStorage, converter);
}
創建了一個MerkleSortTree:
rootHash 節點的根Hash;
如果指定為 null,則實際上創建一個空的 Merkle Tree;
options 樹的配置選項;
keyPrefix 存盤資料的 key 的前綴;
kvStorage 保存 Merkle 節點的存盤服務;
converter 默克爾樹的轉換器;
dataPolicy 資料節點的處理策略;
可以通過更改setting來創建不同資料型別的樹
public MerkleSortTree(HashDigest rootHash, TreeOptions options, Bytes keyPrefix, ExPolicyKVStorage kvStorage,
BytesConverter<T> converter, DataPolicy<T> dataPolicy) {
this.KEY_PREFIX = keyPrefix;
this.OPTIONS = options;
this.KV_STORAGE = kvStorage;
this.DEFAULT_HASH_FUNCTION = Crypto.getHashFunction(options.getDefaultHashAlgorithm());
this.CONVERTER = converter;
this.DATA_POLICY = dataPolicy;
MerkleIndex merkleIndex = loadMerkleEntry(rootHash);
int subtreeCount = merkleIndex.getChildCounts().length;
TreeDegree degree = null;
for (TreeDegree td : TreeDegree.values()) {
if (td.DEGREEE == subtreeCount) {
degree = td;
}
}
if (degree == null) {
throw new MerkleProofException("The root node with hash[" + rootHash.toBase58() + "] has wrong degree!");
}
this.DEGREE = degree.DEGREEE;
this.MAX_LEVEL = degree.MAX_DEPTH;
this.MAX_COUNT = MathUtils.power(DEGREE, MAX_LEVEL);
this.root = new PathNode(rootHash, merkleIndex, this);
refreshMaxId();
}
從指定的默克爾索引開始,搜索指定 id 的資料,并記錄搜索經過的節點的哈希;如果資料不存在,則回傳 null;
merkleIndex 開始搜索的默克爾索引節點;
id 要查找的資料的 id;
pathSelector 路徑選擇器,記錄搜索程序經過的默克爾節點;
搜索到的指定 ID 的資料;
private T seekData(MerkleIndex merkleIndex, long id, MerkleEntrySelector pathSelector) {
int idx = index(id, merkleIndex);
if (idx < 0) {
return null;
}
if (merkleIndex.getStep() > 1) {
MerkleIndex child;
if (merkleIndex instanceof PathNode) {
PathNode path = (PathNode) merkleIndex;
child = path.getChild(idx);
if (child == null) {
return null;
}
HashDigest childHash = path.getChildHashs()[idx];
pathSelector.accept(childHash, child);
} else {
HashDigest[] childHashs = merkleIndex.getChildHashs();
HashDigest childHash = childHashs[idx];
if (childHash == null) {
return null;
}
child = loadMerkleEntry(childHash);
pathSelector.accept(childHash, child);
}
return seekData((MerkleIndex) child, id, pathSelector);
}
// leaf node;
T child;
if (merkleIndex instanceof LeafNode) {
@SuppressWarnings("unchecked")
LeafNode<T> path = (LeafNode<T>) merkleIndex;
child = path.getChild(idx);
} else {
HashDigest[] childHashs = merkleIndex.getChildHashs();
HashDigest childHash = childHashs[idx];
if (childHash == null) {
return null;
}
child = CONVERTER.fromBytes(loadNodeBytes(childHash));
}
return child;
}
合并指定的索引節點和資料節點
indexNodeHash 索引節點的哈希;
indexNode 索引節點;
dataId 資料節點的 id;
data 資料;
回傳共同的父節點;如果未更新資料,則回傳 null;
private MerkleNode mergeChildren(HashDigest indexNodeHash, MerkleIndex indexNode, long dataId, T data) {
final long PATH_OFFSET = indexNode.getOffset();
final long PATH_STEP = indexNode.getStep();
long pathId = PATH_OFFSET;
long dataOffset = calculateOffset(dataId, PATH_STEP);
long pathOffset = PATH_OFFSET;
long step = PATH_STEP;
while (dataOffset != pathOffset) {
step = upStep(step);
if (step >= MAX_COUNT) {
throw new IllegalStateException("The 'step' overflows!");
}
dataOffset = calculateOffset(dataId, step);
pathOffset = calculateOffset(pathId, step);
}
// 判斷引數指定的索引節點和資料節點是否具有從屬關系,還是并列關系;
if (step == PATH_STEP && pathOffset == PATH_OFFSET) {
// 資料節點屬于 pathNode 路徑節點;
// 把資料節點合并到 pathNode 路徑節點;
int index = index(dataId, pathOffset, step);
if (PATH_STEP > 1) {
PathNode parentNode;
if (indexNode instanceof PathNode) {
parentNode = (PathNode) indexNode;
} else {
parentNode = new PathNode(indexNodeHash, indexNode, this);
}
boolean ok = updateChildAtIndex(parentNode, index, dataId, data);
return ok ? parentNode : null;
} else {
// while PATH_STEP == 1, this index node is leaf;
LeafNode<T> parentNode;
if (indexNode instanceof LeafNode) {
parentNode = (LeafNode<T>) indexNode;
} else {
parentNode = new LeafNode<T>(indexNodeHash, indexNode, this);
}
boolean ok = updateChildAtIndex(parentNode, index, dataId, data);
return ok ? parentNode : null;
}
} else {
// 資料節點不從屬于 pathNode 路徑節點,它們有共同的父節點;
// 創建共同的父節點;
PathNode parentPathNode = new PathNode(pathOffset, step, this);
int dataChildIndex = parentPathNode.index(dataId);
boolean ok = updateChildAtIndex(parentPathNode, dataChildIndex, dataId, data);
if (!ok) {
return null;
}
int pathChildIndex = parentPathNode.index(pathId);
updateChildAtIndex(parentPathNode, pathChildIndex, indexNodeHash, indexNode);
return parentPathNode;
}
}
這個是一個判斷子節點是否溢位,或超出范圍的方法,
public long skip(long count) {
if (count < 0) {
throw new IllegalArgumentException("The specified count is out of bound!");
}
if (count == 0) {
return 0;
}
if (childIndex >= TREE.DEGREE) {
return 0;
}
long s = ArrayUtils.sum(childCounts, 0, childIndex + 1);
long skipped;// 實際可略過的數量;
long currLeft = s - cursor - 1;
if (count < currLeft) {
// 實際略過的數量在 index 指示的當前子節點的范圍內;
if (childIterator == null) {
childIterator = createChildIterator(childIndex);
}
skipped = count;
long sk = childIterator.skip(skipped);
assert sk == skipped;
} else {
// 已經超過 index 指示的當前子節點的剩余數量,直接忽略當前子節點;
childIterator = null;
skipped = currLeft;
childIndex++;
while (childIndex < TREE.DEGREE && skipped + childCounts[childIndex] <= count) {
skipped += childCounts[childIndex];
childIndex++;
}
if (childIndex < TREE.DEGREE) {
// 未超出子節點的范圍;
long c = count - skipped;
childIterator = createChildIterator(childIndex);
long sk = childIterator.skip(c);
assert sk == c;
skipped = count;
}
}
cursor = cursor + skipped;
return skipped;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/333405.html
標籤:區塊鏈