我有一個這樣的資料框,但要大得多:
data = {
"p_id": [1, 1, 1, 2,2,3,3],
"m_id": [11,25,35,11,35,25,35],
"Time": [25,40,10,21,13,15,20]
}
我如何將其轉換為以下串列
Jobs = [#(m_id, Time)
[(11,25) , (25,40) , (35,10)] #p_id=1
[(11, 21) , (35,13)]#p_id = 2
[(25,15), (35,20)]#p_id = 3
]
我已經用下面的行嘗試過,但它不能正常作業
df.groupby(‘p_id’)[[‘m_id’,’time’]].apply(list)
有沒有簡單的方法來轉換這個?
謝謝 !
uj5u.com熱心網友回復:
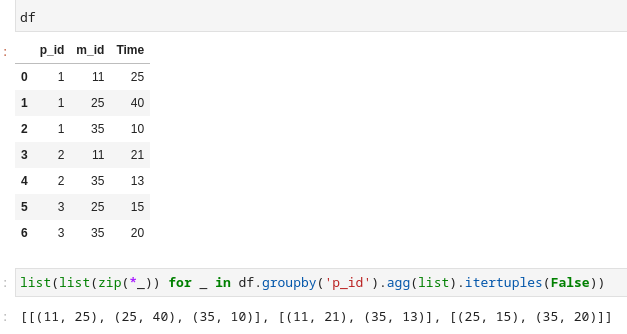
[list(zip(*_)) for _ in df.groupby('p_id').agg(list).itertuples(False)]
- 與
p_id - 用串列聚合其他列
- 將它們作為元組迭代并洗掉索引(索引=假)
- 我們得到
Pandas(m_id=[11, 25, 35], Time=[25, 40, 10]),
Pandas(m_id=[11, 35], Time=[21, 13]),
Pandas(m_id=[25, 35], Time=[15, 20])
但我們需要轉置它們,所以我們為它做了 zip(*_)
- zip 回傳生成器,因此我們需要將其包裝串列
uj5u.com熱心網友回復:
一種方法是設定p_id為索引,然后applytuple on axis=1,然后 group on level=0,最后 apply list:
>>> out = df.set_index('p_id').apply(tuple, axis=1).groupby(level=0).apply(list)
p_id
1 [(11, 25), (25, 40), (35, 10)]
2 [(11, 21), (35, 13)]
3 [(25, 15), (35, 20)]
之后,您可以根據需要將其轉換為 Python 串列:
>>> out.to_list()
[[(11, 25), (25, 40), (35, 10)], [(11, 21), (35, 13)], [(25, 15), (35, 20)]]
替代方式:
df.groupby('p_id').apply(lambda x: x.iloc[:,1:].apply(tuple, axis=1).tolist()).to_list()
[[(11, 25), (25, 40), (35, 10)], [(11, 21), (35, 13)], [(25, 15), (35, 20)]]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/335406.html