我有一個小的 df,其中包含多個測驗中兩個班級的分數。我想建立一個表格來展示從第一次測驗到每次測驗的變化。
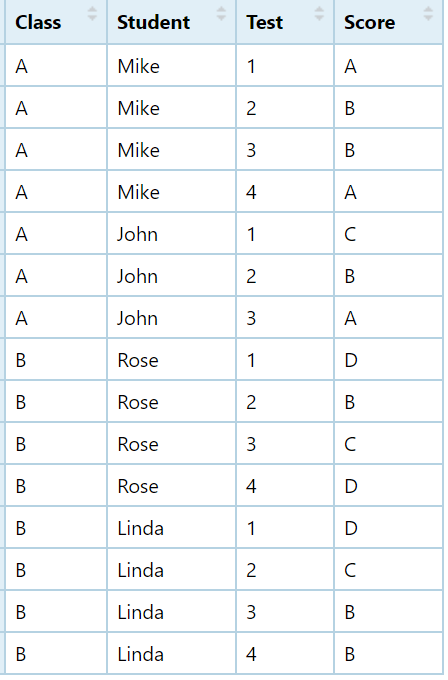
df 看起來像這樣:
我要構建的新表如下所示:
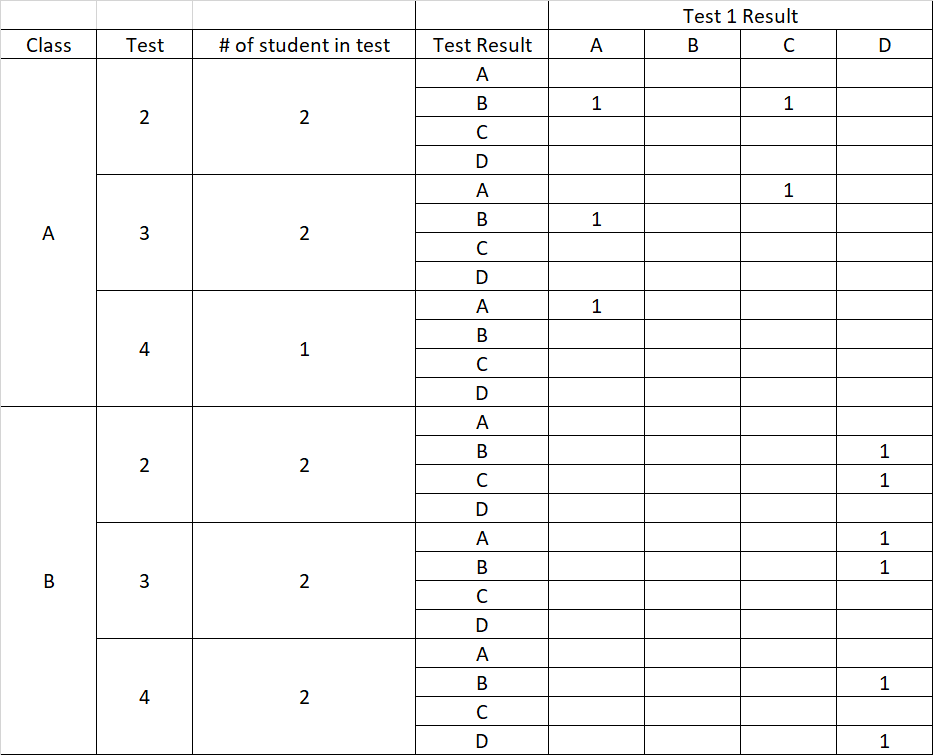
因此,我們可以為每個測驗判斷有多少學生在哪個年級以及他們的第 1 次測驗結果。我應該怎么做才能建立這樣的表?我是否必須構建每一行然后將它們系結在一起?有什么聰明的辦法嗎?
樣本資料:
df<-structure(list(Class = c("A", "A", "A", "A", "A", "A", "A", "B",
"B", "B", "B", "B", "B", "B", "B"), Student = c("Mike", "Mike",
"Mike", "Mike", "John", "John", "John", "Rose", "Rose", "Rose",
"Rose", "Linda", "Linda", "Linda", "Linda"), Test = c(1, 2, 3,
4, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4), Score = c("A", "B", "B",
"A", "C", "B", "A", "D", "B", "C", "D", "D", "C", "B", "B")), row.names = c(NA,
-15L), class = c("tbl_df", "tbl", "data.frame"))
uj5u.com熱心網友回復:
呼,那是一個艱難的程序。不確定是否有更簡單的選擇,但考慮到不同的聚合/分組級別以及以下事實:a)并非所有所需的輸出行都是資料的一部分,并且 b)您的學生都沒有得分“B”第一次測驗,很難得到更短的代碼版本。
注意:對于“B”類,測驗 3,您的預期輸出顯示測驗 1 = D 和測驗結果 = A/B 的結果。但是,您的資料顯示 Rose 從 D 到 C,Linda 從 D 到 B,所以我想這是一個錯誤。
df %>%
group_by(Class, Student) %>%
mutate(first_result = Score[Test == 1],
first_result = fct_expand(first_result, LETTERS[1:4])) %>%
ungroup() %>%
complete(Class, Test, Score, first_result) %>%
mutate(first_result = as.character(first_result)) %>%
group_by(Class, Test) %>%
mutate(student_per_test = length(unique(Student[!is.na(Student)])),
result = if_else(!is.na(Student), 1L, NA_integer_)) %>%
filter(Test != 1) %>%
select(-Student) %>%
ungroup() %>%
arrange(Class, Test, Score, first_result) %>%
pivot_wider(names_from = first_result,
values_from = result)
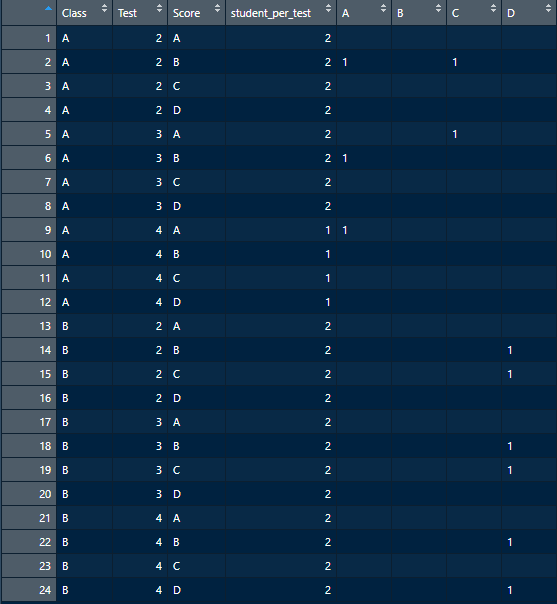
這使:
# A tibble: 24 x 8
Class Test Score student_per_test A B C D
<chr> <dbl> <chr> <int> <int> <int> <int> <int>
1 A 2 A 2 NA NA NA NA
2 A 2 B 2 1 NA 1 NA
3 A 2 C 2 NA NA NA NA
4 A 2 D 2 NA NA NA NA
5 A 3 A 2 NA NA 1 NA
6 A 3 B 2 1 NA NA NA
7 A 3 C 2 NA NA NA NA
8 A 3 D 2 NA NA NA NA
9 A 4 A 1 1 NA NA NA
10 A 4 B 1 NA NA NA NA
11 A 4 C 1 NA NA NA NA
12 A 4 D 1 NA NA NA NA
13 B 2 A 2 NA NA NA NA
14 B 2 B 2 NA NA NA 1
15 B 2 C 2 NA NA NA 1
16 B 2 D 2 NA NA NA NA
17 B 3 A 2 NA NA NA NA
18 B 3 B 2 NA NA NA 1
19 B 3 C 2 NA NA NA 1
20 B 3 D 2 NA NA NA NA
21 B 4 A 2 NA NA NA NA
22 B 4 B 2 NA NA NA 1
23 B 4 C 2 NA NA NA NA
24 B 4 D 2 NA NA NA 1
請注意,空單元格是NA.
如果需要,您可以在上面的代碼末尾添加另一行代碼,將這些列轉換為空字串:
mutate(across(LETTERS[1:4], ~replace_na(.x, "")))
但是,這會將數字列轉換為字符列。所以,如果你想要那個,就看你了。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/343294.html
標籤:r
上一篇:根據兩個標準為每組獲取多個值