我的資料框 1 如下所示:
| 風碼 | 姓名 | 屈服 | 人 |
|---|---|---|---|
| 163197.SH | 上國公司 | 2.9248 | 不 |
| 154563.SH | 國盛公司 | 2.886 | 是的 |
| 789645.IB | 國友公司 | 3.418 | 不 |
我的資料框 2 看起來像這樣
| 風碼 | 中航協 |
|---|---|
| 1202203.IB | 2.5517 |
| 1202203.IB | 2.48457 |
| 1202203.IB | 2.62296 |
并且我希望我的結果資料框 3 比資料框 1 多一個新列,即使用資料框 1 中“產量”列中的值減去資料框 2 中“計算”列中的值:結果資料框 3 應該看起來像這個
| 風碼 | 姓名 | 屈服 | 人 | 收益率-CALC |
|---|---|---|---|---|
| 163197.SH | 上國公司 | 2.9248 | 不 | 0.3731 |
| 154563.SH | 國盛公司 | 2.886 | 是的 | 0.40413 |
| 789645.IB | 國友公司 | 3.418 | 不 | 0.79504 |
如果有人能告訴我如何在 python 中做到這一點,那將非常有幫助。
uj5u.com熱心網友回復:
你可以嘗試這樣的事情:
df1['yield-CALC'] = df1['yield'] - df2['yield']
我假設您不想加入資料幀,因為風碼不一樣。
uj5u.com熱心網友回復:
我們是否需要從 Windcodes 列加入 2 個資料幀?您在 Dataframe2 中給出的示例資料中的風碼都相同。你能解釋一下嗎?
如果我們要從 windscode 領域加入。下面的代碼將起作用。
df = pd.merge(left=df1, right=df2,how='inner',on='windcodes')
df['yield-CALC'] = df['yield']-df['CALC']
uj5u.com熱心網友回復:
我會盡量保持詳細說明:
我用于編碼的環境是Jupyter Notebook
匯入我們所需的熊貓庫
import pandas as pd
以串列串列的形式獲取您的第一個表格資料(您也可以在此處使用 csv、excel 等)
data_1 = [["163197.SH","shangguo comp",2.9248,"NO"],\
["154563.SH","guosheng comp",2.886,"Yes"] , ["789645.IB","guoyou comp",3.418,"NO"]]
創建資料框一:
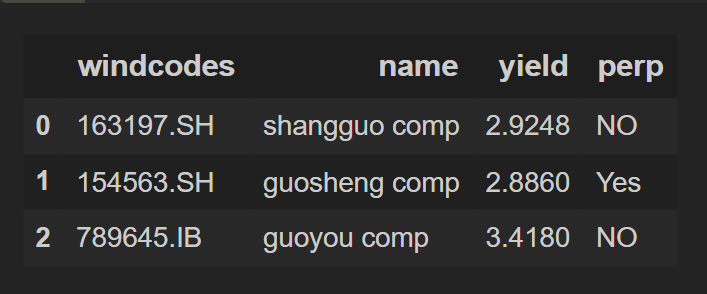
df_1 = pd.DataFrame(data_1 , columns = ["windcodes","name","yield","perp"])
df_1
輸出:
以串列串列的形式獲取第二個表格資料(您也可以在此處使用 csv、excel 等)
data_2 = [["1202203.IB",2.5517],["1202203.IB",2.48457],["1202203.IB",2.62296]]
創建資料框二:
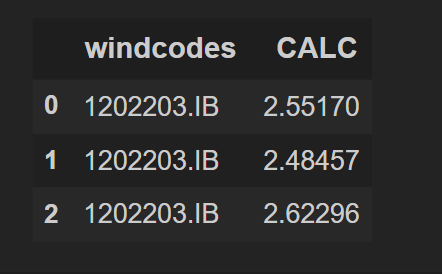
df_2 = pd.DataFrame(data_2 , columns = ["windcodes","CALC"])
df_2
輸出:
現在創建第三個資料框:
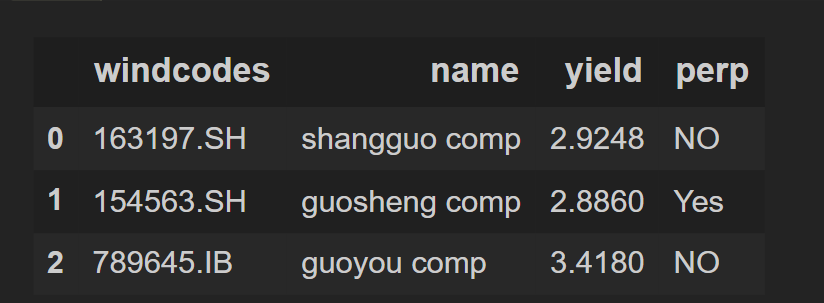
df_3 = df_1 # becasue first 4 columns are same as our first dataframe
df_3
輸出:
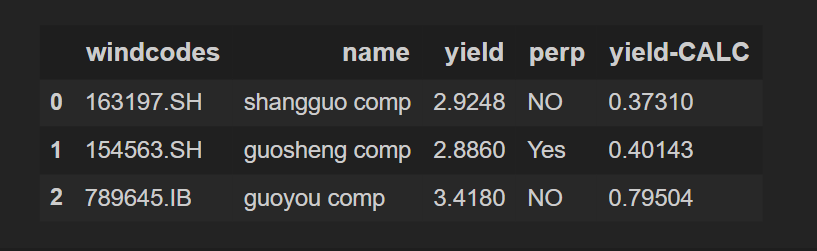
現在計算第四列,即“yield-CALC”:
df_3["yield-CALC"] = df_1["yield"] - df_2["CALC"] # each df_1 datapoint will be subtracted from df_2 datapoint one by one (still confused? search for "SIMD")
df_3
輸出:
希望你明白。
快樂編碼!
uj5u.com熱心網友回復:
以防萬一您有完全不同的索引,請使用 df2 的底層 numpy 陣列:
df1['yield-CALC'] = df1['yield'] - df2['yield'].values
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/343733.html