我正在使用這本教科書 Randal E. Bryant, David R. O'Hallaron - Computer Systems。A Programmer's Perspective [3rd ed.] (2016, Pearson),還有一段我不太明白。
代碼:
void write_read(long *src, long *dst, long n)
{
long cnt = n;
long val = 0;
while (cnt) {
*dst = val;
val = (*src) 1;
cnt--;
}
}
的內回圈write_read:
#src in %rdi, dst in %rsi, val in %rax
.L3:
movq %rax, (%rsi) # Write val to dst
movq (%rdi), %rax # t = *src
addq $1, %rax # val = t 1
subq $1, %rdx # cnt--
jne .L3 # If != 0, goto loop
給出這段代碼,教科書給出了這個圖來描述程式流程 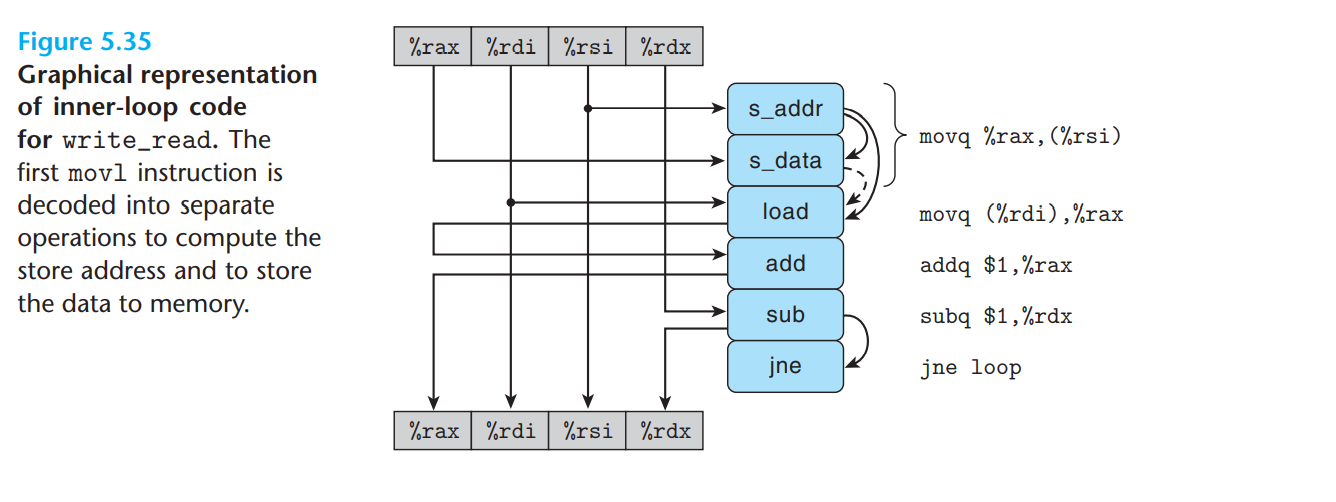
對于那些無法訪問 TB 的人,這是給出的解釋:
圖 5.35 顯示了此回圈代碼的資料流表示。該指令
movq %rax,(%rsi)被翻譯成兩個操作: s_addr 指令計算存盤操作的地址,在存盤緩沖區中創建一個條目,并設定該條目的地址欄位。s_data 操作設定條目的資料欄位。正如我們將看到的,這兩個計算獨立執行的事實對程式性能很重要。這激發了參考機中這些操作的獨立功能單元。除了暫存器的寫入和讀取導致的操作之間的資料依賴之外,運算子右側的弧表示這些操作的一組隱式依賴。特別是 s_addr 操作的地址計算必須明確在 s_data 操作之前。
此外,通過解碼指令生成的加載操作
movq (%rdi), %rax必須檢查任何掛起的存盤操作的地址,從而在它和 s_addr 操作之間創建資料依賴關系。該圖顯示了 s_data 和加載操作之間的虛線弧。這種依賴是有條件的:如果兩個地址匹配,則加載操作必須等到 s_data 將其結果存入存盤緩沖區,但如果兩個地址不同,則兩個操作可以獨立進行。
a) What I am not really clear about is why after this line movq %rax,(%rsi) there needs to be a load done after s_data is called? I'm assuming that when s_data is called, the value of %rax is stored in the location that the address of %rsi is pointing to? Does this mean that after every s_data there needs to be a load call?
b) It doesn't really show in the diagram but from what I understand from the explanation given in the book, movq (%rdi), %rax this line requires its own set of s_addr and s_data? So is it accurate to say that all movq calls require an s_addr and s_data call followed by the check to check if the addresses match before calling load ?
Quite confused over these parts, would appreciate if someone can explain how the s_addr and s_data calls work with load and when it is required to have these functions, thank you!!
uj5u.com熱心網友回復:
藍色框中的操作是由流水線的解碼器發出的微操作(也稱為 uops 或微指令)。它們是正在執行的程式的一部分。該movq (%rdi), %rax指令被解碼到加載微指令中。uop 是管道中的執行單元。Uops 沒有被呼叫,它們被執行。
根據書中討論的假設處理器設計,像這樣的簡單存盤指令movq %rax, (%rsi)被解碼為兩個uop,稱為s_addr和s_data。這也發生在真正的 x86 處理器中。一個宏指令可能被解碼成多個 uop 的一個原因是因為一個 uop 的格式不允許它保存指令中給出的所有資訊,例如當指令有太多運算元或代表一個復雜的任務時. 另一個原因是增加指令級并行性。存盤的地址和存盤的資料可以在不同的周期變得可用。如果地址可用但資料不可用,則s_addr可以將 uop 分派到加載存盤單元,以使下游加載 uop 的地址更早地與存盤的地址進行比較,而無需等待存盤的資料。確定較晚加載是否取決于較早存盤的程序稱為記憶體消歧。如果加載movq (%rdi), %rax不與較早的 store 重疊movq %rax, (%rsi),那么它可以立即執行,無論 in 的值%rax是否準備好。
當執行s_data uop 時,值 in%rax存盤在分配了存盤 uop 的存盤緩沖區條目的資料欄位中。在所有較早的指令完成執行以維持程式順序之后,將值存盤在目標記憶體位置后發生。
書中說“s_addr 操作的地址計算必須明確在 s_data 操作之前”可能是因為,根據書中的說法,s_addr uop必須先在存盤緩沖區中創建一個條目,然后才能將資料存盤在其中。這對于假設的設計來說可能沒問題,但這是一種不必要的依賴,因為分配可以在執行之前完成。無論如何,本書沒有討論資源分配和回收。
一個簡單的加載指令被解碼為單個加載指令。沒有理由將負載分成多個 uops。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/343792.html