我想獲得位置之間唯一連接的數量,因此 a->b 和 b->a 應該算作一。資料幀包含時間戳和開始和結束位置名稱。結果應顯示一年中每天站點之間的獨特連接。
import findspark
findspark.init('/home/[user_name]/spark-3.1.2-bin-hadoop3.2')
import pyspark
from pyspark.sql.functions import date_format, countDistinct, struct, col
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('cluster1').getOrCreate()
from pyspark.sql.types import StructType,StructField, StringType, IntegerType, DateType, TimestampType
from pyspark.sql.functions import to_timestamp
data2 = [
('2017-12-29 16:57:39.6540','2017-12-29 16:57:39.6540',"A","B"),
("2017-12-29 16:57:39.6540","2017-12-29 17:57:39.6540","B","A"),
("2017-12-29 16:57:39.6540","2017-12-29 19:57:39.6540","B","A"),
("2017-12-30 16:57:39.6540","2017-12-30 16:57:39.6540","C","A"),
("2017-12-30 16:57:39.6540","2017-12-30 17:57:39.6540","B","F"),
("2017-12-31 16:57:39.6540","2017-12-31 16:57:39.6540","C","A"),
("2017-12-31 16:57:39.6540","2017-12-31 17:57:39.6540","A","C"),
("2017-12-31 16:57:39.6540","2017-12-31 17:57:39.6540","B","C"),
("2017-12-31 16:57:39.6540","2017-12-31 17:57:39.6540","A","B"),
]
schema = StructType([ \
StructField("start",StringType(),True), \
StructField("end",StringType(),True), \
StructField("start_loc",StringType(),True), \
StructField("end_loc", StringType(), True)
])
df2 = spark.createDataFrame(data=data2,schema=schema)
df2 = df2.withColumn("start_timestamp",to_timestamp("start"))
df2 = df2.withColumn("end_timestamp",to_timestamp("end"))
df2 = df2.drop("start", "end")
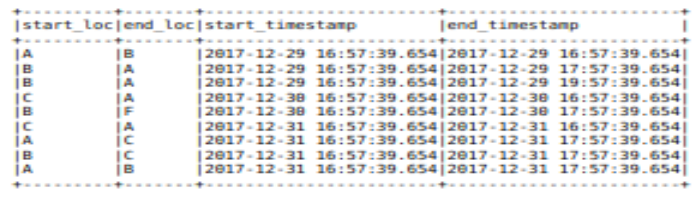
df2.printSchema()
df2.show(truncate=False)
df2_agg = df2.withColumn("date", date_format('start_timestamp', 'D'))\
.groupBy('date', 'start_loc','end_loc').agg(
collect_list(struct(col('start_loc'), col('end_loc'))).alias("n_routes_sets"),
)
df2_agg.show()
結果如下所示:
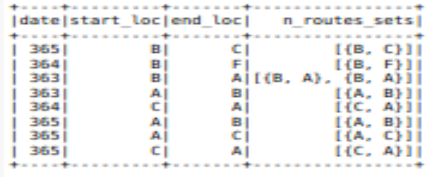
,但結果應該是這樣的:
| 日期 | n_routes |
|---|---|
| 365 | 3 |
| 364 | 2 |
| 363 | 1 |
下面一行是錯誤的。
collect_list(struct(col('start_loc'), col('end_loc'))).alias("n_routes_sets"),
uj5u.com熱心網友回復:
按照下面修改您的行,并將 a,b 和 b,a 重新排序為 a,b,反之亦然:
from pyspark.sql.functions import date_format, countDistinct, collect_set, struct, col, when, size
...
...
df2 = df2.withColumn("sl2", when(df2['end_loc'] < df2['start_loc'], df2['end_loc']).otherwise(df2['start_loc']) )
df2 = df2.withColumn("el2", when(df2['end_loc'] > df2['start_loc'], df2['end_loc']).otherwise(df2['start_loc']) )
df2 = df2.drop("start_loc", "end_loc")
df2.printSchema()
df2.show(truncate=False)
df2_agg = df2.withColumn("date", date_format('start_timestamp', 'D'))\
.groupBy('date').agg(collect_set(struct(col('sl2'), col('el2'))).alias("n_routes_sets"),
)
df2_agg.select("date", size("n_routes_sets")).show()
回傳:
---- -------------------
|date|size(n_routes_sets)|
---- -------------------
| 363| 1|
| 364| 2|
| 365| 3|
---- -------------------
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/345657.html