我試圖找出我的資料幀值所在的時間視窗,但我無法理解輸出。我無法理解: window(timeColumn, windowDuration, slideDuration=None, startTime=None)是如何作業的。
這是代碼:
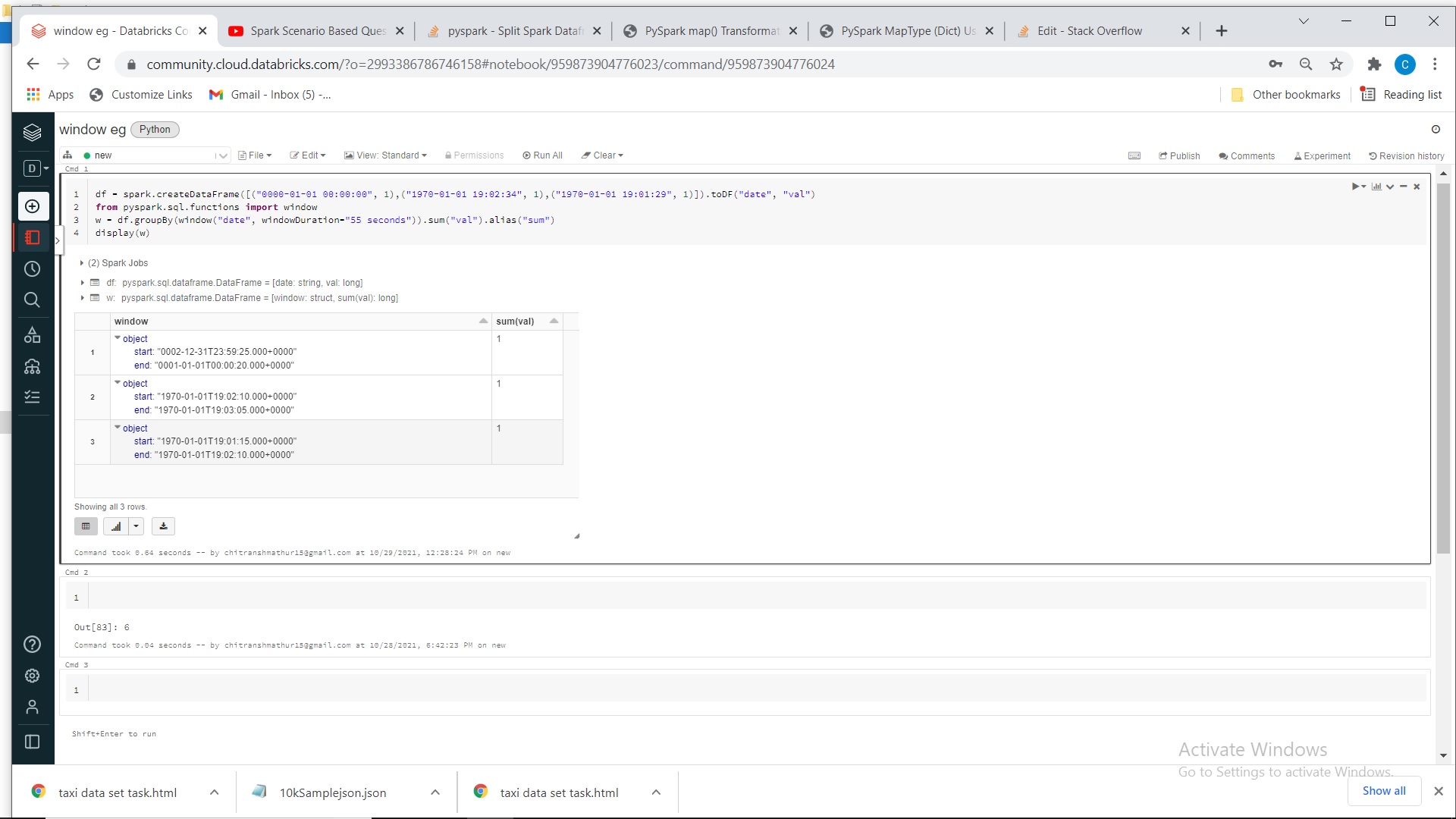
df = spark.createDataFrame([("0000-01-01 00:00:00", 1),("1970-01-01 19:02:34", 1),("1970-01-01 19:01:29", 1)]).toDF("date", "val")
from pyspark.sql.functions import window
w = df.groupBy(window("date", windowDuration="55 seconds")).sum("val").alias("sum")
display(w)
使用資料塊。
有人可以告訴我輸出并解釋它是如何作業的。
uj5u.com熱心網友回復:
從時間戳列,window將創建一個包含輸入時間戳的“存盤桶”(開始和結束時間)。桶的“大小”取決于windowDuration持續時間引數。
例如,您有一個時間戳2021-10-29 11:13:51并且您應用了帶有 的視窗函式windowDuration = "15 minutes",新列將是帶有start = "2021-10-29 11:00:00"和的結構體 end = "2021-10-29 11:15:00"。在開始和結束之間,您有 15 分鐘,您的時間戳包含在兩者之間。
在您當前的代碼中,您使用windowDuration="55 seconds". 根據檔案:
startTime 是相對于 1970-01-01 00:00:00 UTC 的偏移量,用于開始視窗間隔。
這意味著從日期 1970-01-01 00:00:00 開始,它將創建 55 秒長度的視窗。第一個將是1970-01-01 00:00:00 ==> 1970-01-01 00:00:55,第二個將是1970-01-01 00:00:55 ==> 1970-01-01 00:01:50,等等......它可以作業,但開始和結束1 minutes與例如引數相比不是常規的。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/345660.html